 夜雨聆风
夜雨聆风摘要
虚拟细胞模型旨在通过计算预测细胞对各类扰动的响应,已成为药物研发与精准医疗的前沿手段。但当前研究存在明显缺口:各类模型在标准基准测试中表现优异,但其预测结果在实际应用中的生物学意义尚不明确。这主要源于现有评估方案的缺陷——评估设置过度简化、流程不统一,无法反映真实生物系统的复杂性与变异性。本文提出1套标准化、模块化的虚拟细胞预测基准评测框架,在未见细胞背景、未见扰动类型、跨数据集泛化3类真实挑战性场景下评测各类模型,更贴合实际应用需求。分析表明,模型性能具有高度的场景依赖性,受任务设计与评估标准显著影响;常规评估设置会高估模型性能,简单的数据集合并策略甚至会降低性能;严格泛化条件下模型性能大幅下降,表明模型对细胞背景偏移的鲁棒性有限。在未见扰动场景中,包括简单线性模型在内的各类方法仅能捕捉全局转录趋势,无法还原细粒度的扰动特异性效应。此外,不同评估指标侧重不同的生物学特性,导致模型排名差异显著。本框架提供了更可靠、贴合生物学意义的评估方案,为虚拟细胞模型的实际应用提供清晰指引。
sunsiqi1@pjlab.org.cn
gaozhangyang@pjlab.org.cn
结果
虚拟细胞预测基准评测框架
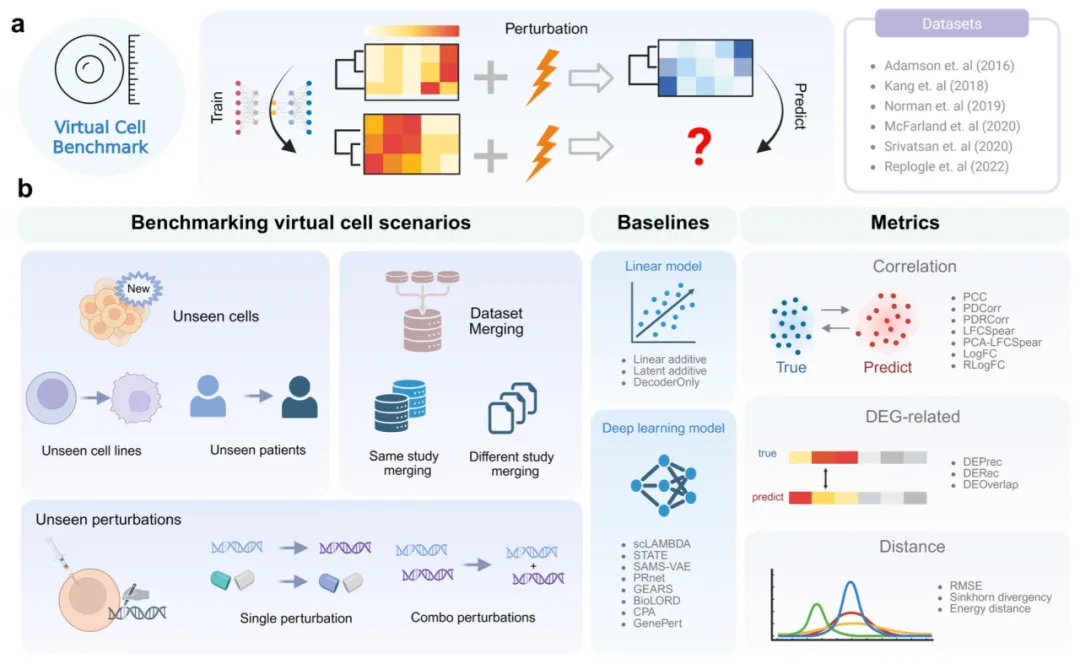
图1VCBench基准评测流程与方法总览
(a) 虚拟细胞预测示意图。虚拟细胞模型以扰动前细胞状态为输入,包括基因表达谱及可选的细胞类型、扰动标识(如基因敲除、药物处理)等背景信息,目标是预测扰动后的基因表达,同时捕捉全局表达偏移与基因水平响应。
(b) 将虚拟细胞预测分为3类场景:未见细胞泛化、未见扰动泛化、多数据集合并。在每类场景下,基于6项代表性研究的7个常用数据集,评测11种典型方法,并采用3类指标开展全面对比。
未见细胞泛化场景的基准评测分析
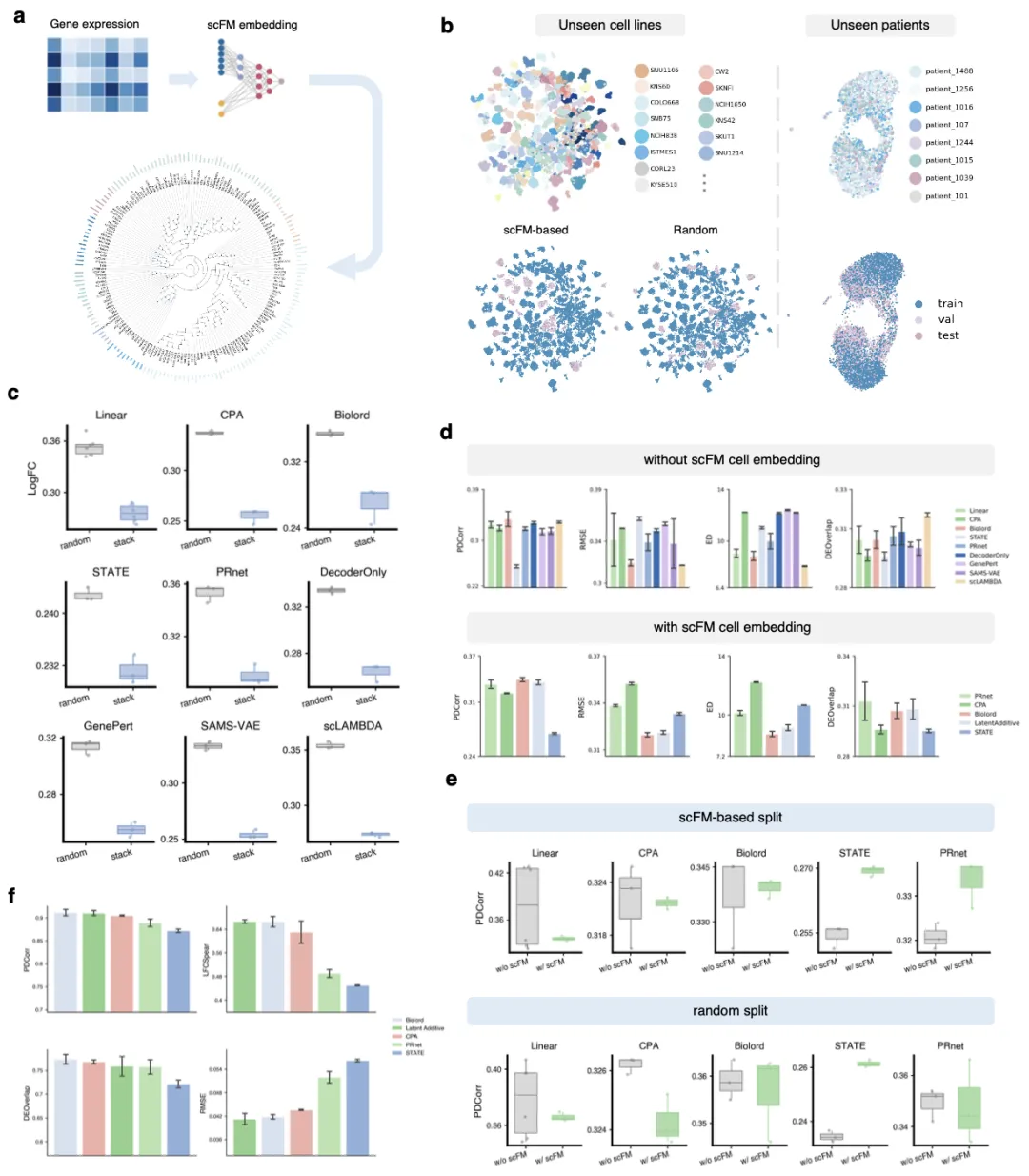
图2基于单细胞基础模型嵌入与随机划分策略的未见细胞评测
(a) 基于单细胞基础模型细胞表征构建未见细胞划分方案。将对照细胞的表达谱投影至基础模型嵌入空间,基于细胞状态相似性定义数据划分。
(b) 基于单细胞基础模型嵌入与随机划分策略下,未见细胞系与未见患者数据划分的可视化。
(c) 随机划分与单细胞基础模型嵌入划分下,各模型在不同评估指标上的性能对比。
(d) 有无单细胞基础模型细胞嵌入时,各模型在代表性指标上的性能。
(e) 不同划分策略下,各模型有无单细胞基础模型细胞嵌入的性能对比。
(f) 未见患者场景下的模型性能对比。
未见扰动泛化场景的基准评测分析
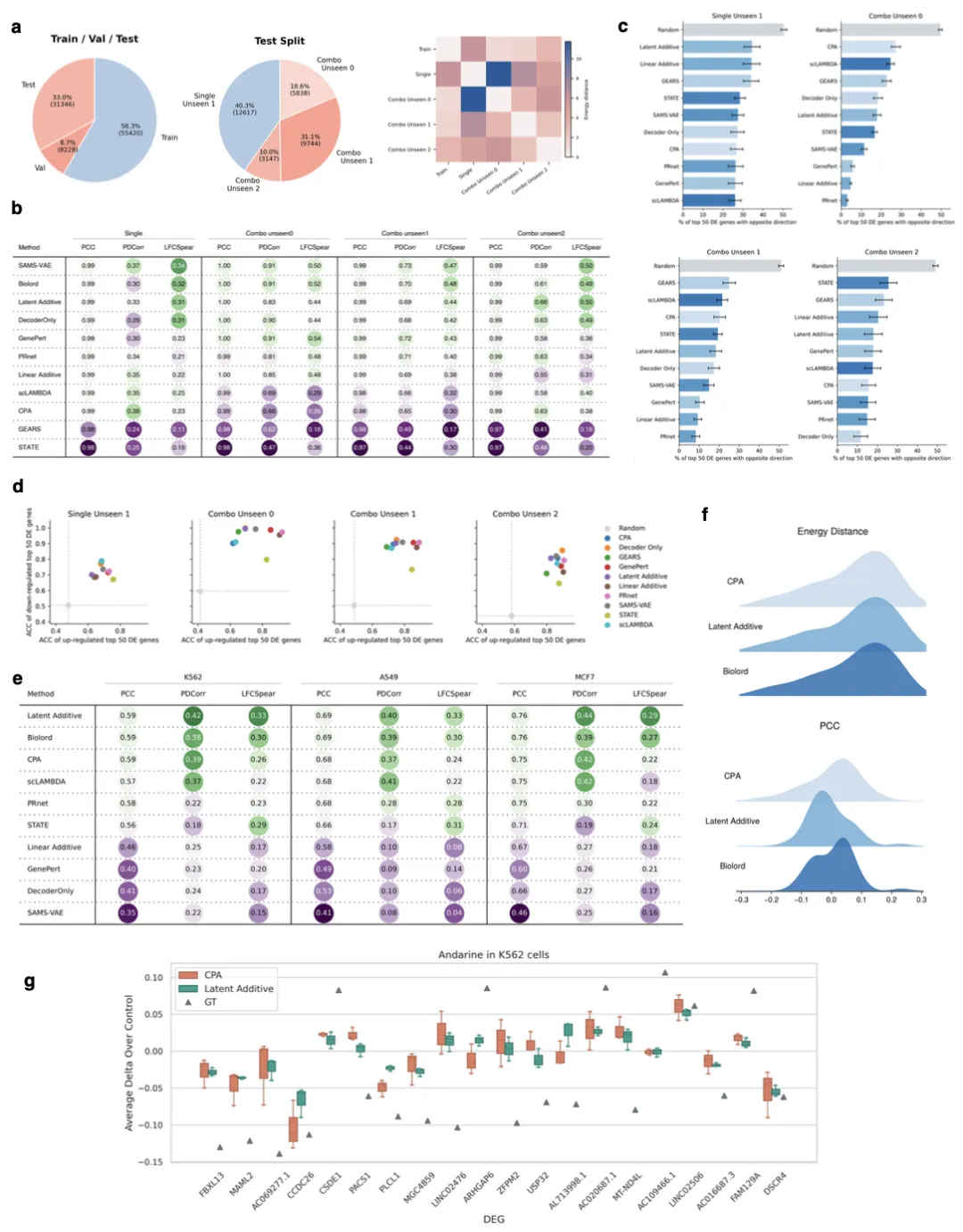
图3 未见扰动任务结果
(a) Norman数据集的数据特征。左:组合扰动任务的数据划分;右:4个测试集划分与训练集的扰动嵌入集之间的能量距离热图。
(b) 所有模型在组合未见扰动任务上的结果。
(c) 所有模型的前50个差异基因反向调控比例;该比例采用标准差异基因计算流程,而非差异基因重叠度所用的修正版本,数值越低性能越好。
(d) 模型预测上调差异基因的平均准确率与下调差异基因的平均准确率对比;点越靠近右上角性能越好。
(e) 所有模型在单一未见扰动任务上的结果。
(f) 针对前50个差异基因的每个基因,分别计算预测细胞集与真实细胞集之间的能量距离(上图)与皮尔逊相关系数(下图),并绘制对应概率密度分布。
(g) 前20个差异基因相对对照的表达变化量。
跨数据集整合的基准评测分析
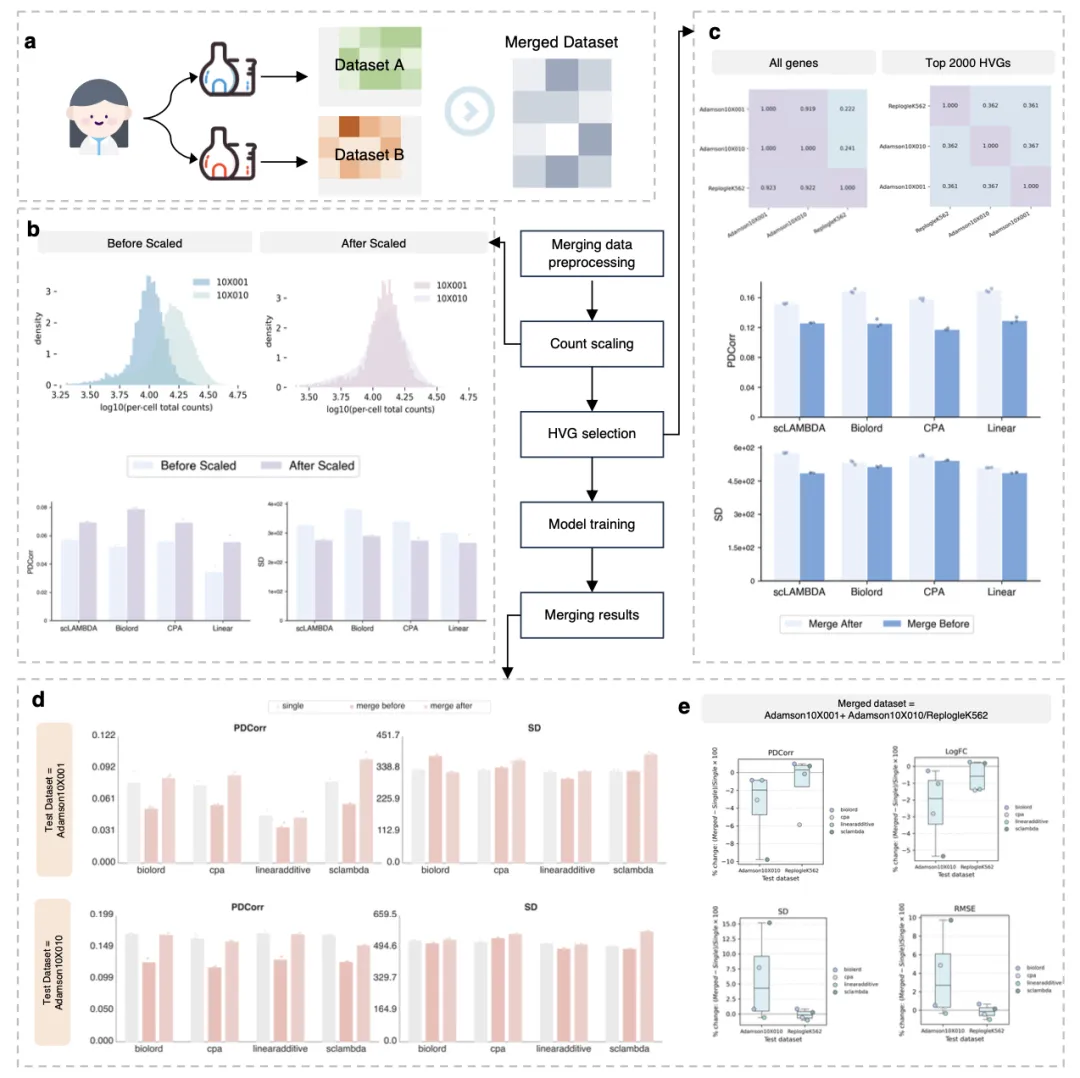
图4不同预处理、合并与评估设置下的跨数据集整合
(a) 数据集合并流程总览,包括合并前预处理、计数标准化、高可变基因筛选、模型训练与评估。
(b) Adamson10X001与Adamson10X010数据集在计数标准化前后的单细胞计数分布,及标准化前后的模型性能。
(c) 采用全部基因与前2,000个高可变基因的基因重叠矩阵,及不同高可变基因筛选策略(先合并后筛选、先筛选后合并)下的模型性能。
(d) 单一数据集训练、先合并后筛选、先筛选后合并3种设置下,模型在Adamson10X001与Adamson10X010数据集对上的性能对比,分别在2个数据集上评估。
(e) 先筛选后合并策略下,Adamson10X001分别与Adamson10X010、ReplogleK562合并的数据集,以Adamson10X010与ReplogleK562为测试集的模型性能。
评估指标的鲁棒性评估
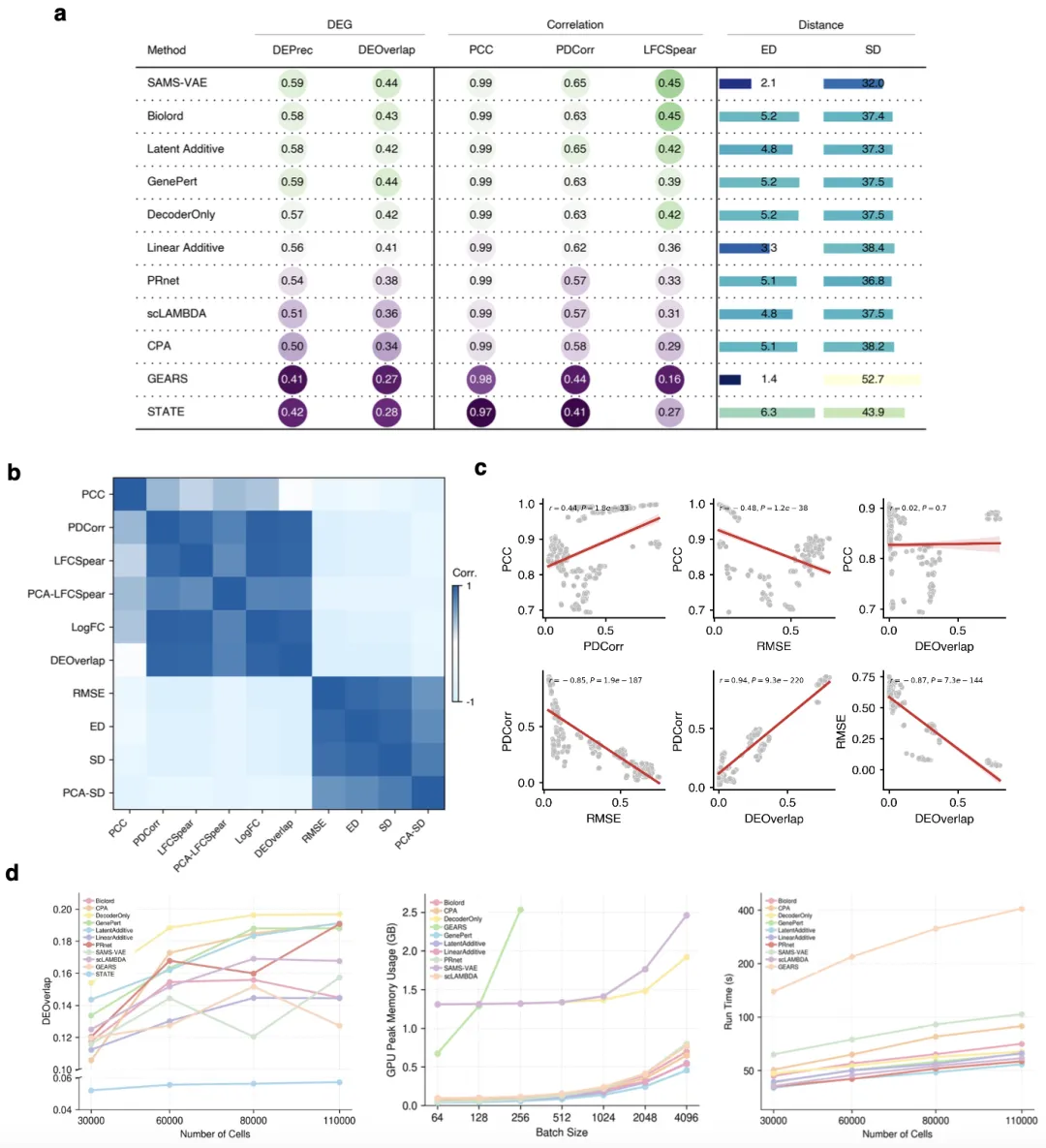
图5依赖指标的评估揭示模型性能的互补维度与计算代价权衡
(a) 各模型在代表性评估指标上的性能,按差异基因相关、基于相关性、分布水平距离3类分组展示。
(b) 评估指标两两间的相关矩阵。
(c) 代表性指标间的两两关系,展示同类指标的一致性与不同评估维度的差异性。
(d) 计算效率分析,包括数据集规模增大时的性能趋势、批次大小变化时的GPU显存占用、各模型的运行时间扩展性。
讨论
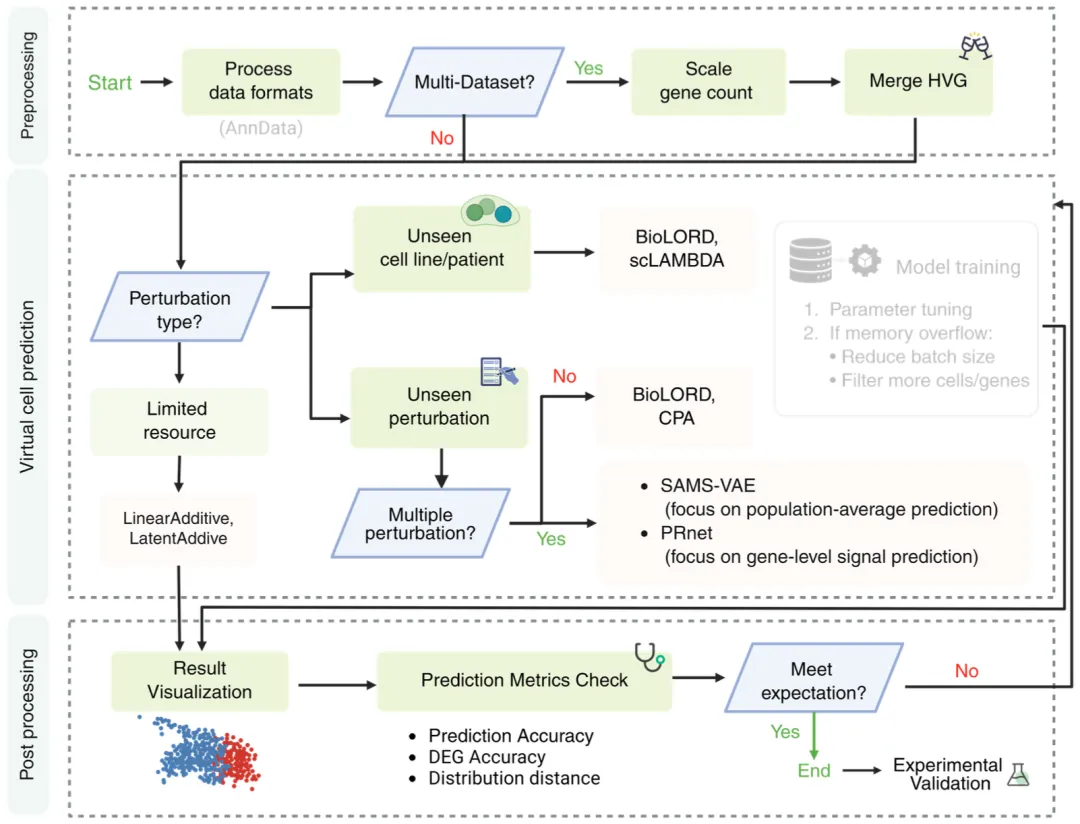
图6虚拟细胞预测分步指南,分为3个阶段
训练前,用户对输入数据进行标准化处理,包括质控、基因水平归一化;若使用多数据集,可开展跨数据集对齐以保证特征空间一致。虚拟细胞建模阶段,用户根据任务场景(如未见细胞状态、未见扰动条件)与计算资源限制选择模型,依次测试线性基线、表征学习、生成模型等方法,并开展标准超参数调优;若出现资源问题,可减小批次大小或降低模型复杂度,若问题未解决则更换方法。预测后,结合定性检查与定量指标(覆盖相关性、分布一致性、差异基因还原)评估结果;若性能达标则开展下游分析,否则返回模型选择环节尝试其他虚拟细胞方法。
方法
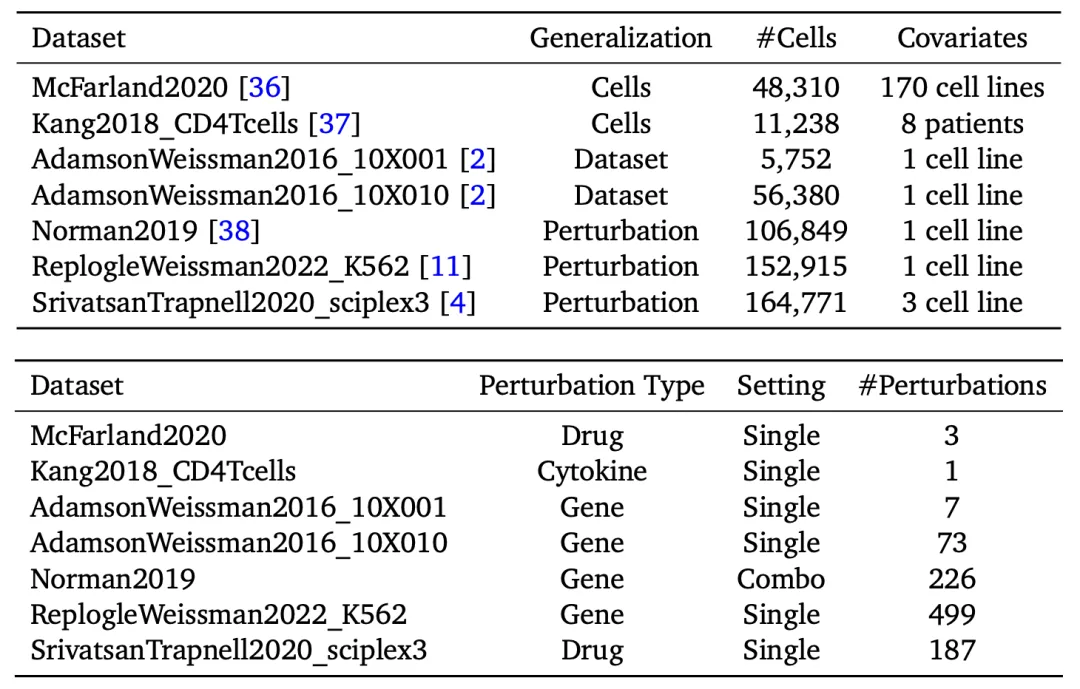
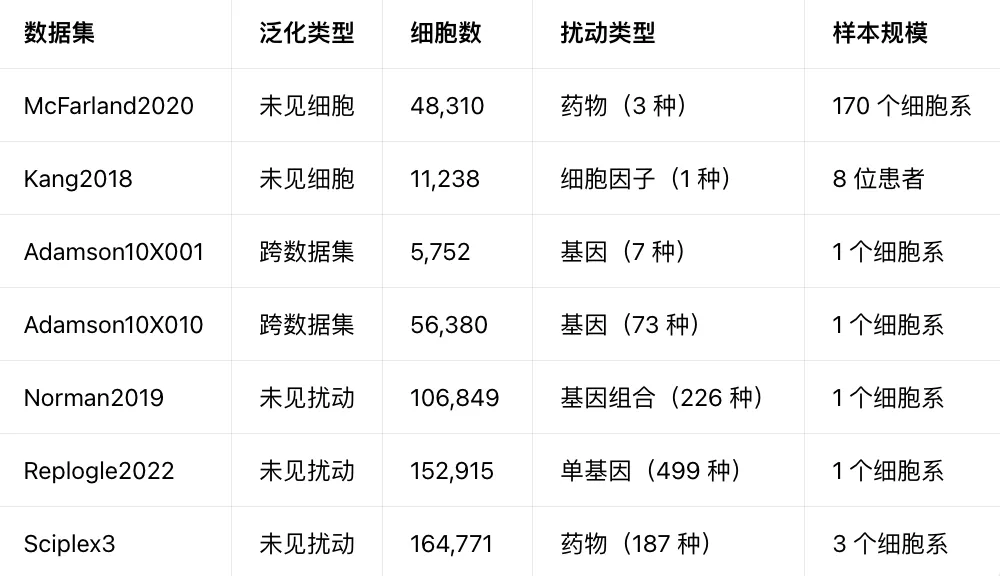
基准评测数据集
表1基准评测所用数据集汇总表
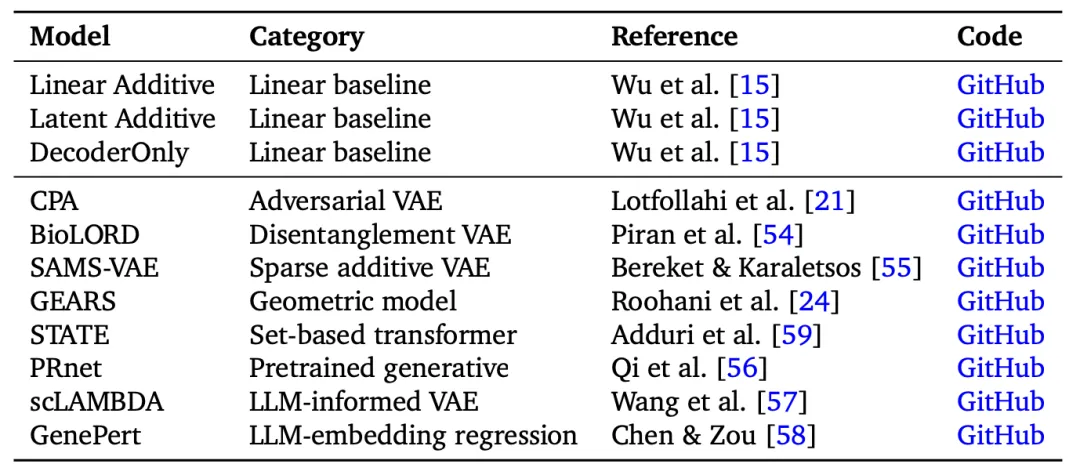
基准评测模型
表2基准评测模型汇总表
所有模型在统一接口下评估,采用一致的预处理与评估流程;GitHub链接为各模型适配所用的原始实现地址。
数据
scPerturb资源以AnnData(h5ad)格式提供统一处理后的单细胞扰动
https://zenodo.org/records/13350497
开展额外预处理,构建基准测试专用的任务划分数据,涵盖未见细胞、未见扰动与跨数据集整合场景。对应任务的处理后
https://drive.google.com/drive/folders/1GrPW9x5_npnT7ILwDVsFWvfDIcqaSjdk?usp=sharing
代码
开源地址
https://github.com/maoxinjie/VCBench/
同时提供交互式网页演示平台,便于探索基准测试结果与模型对比
https://maoxinjie.github.io/VCBench-demo/
详细总结

思维导图
评测数据集(7个)
参考
Benchmarking virtual cell models for in-the-wild perturbation response
https://doi.org/10.48550/arXiv.2604.27646
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。
End
