 夜雨聆风
夜雨聆风

01 简介
PD分离技术:PD分离(Prefill-Decode Disaggregation)技术的核心在于,将一个完整的大模型推理任务,拆分为由不同硬件集群负责的预填充(Prefill)和解码(Decode)两个阶段。核心概念是在标准的Transformer架构中,推理被分为预填充Prefill阶段(处理用户输入的整个提示词,为每个Token生成KV缓存,属于计算密集型任务,需要大量GPU算力)和解码Decode阶段(基于已生成的KV缓存,逐个生成新Token,属于访存密集型任务,对显存带宽要求极高。)。
在传统的混合部署方式,会将两种截然不同的计算模式放在同一硬件上,导致资源利用不均。预填充分时显卡算力跑满但显存空闲,解码时则因显存带宽受限而算力闲置,造成资源浪费,限制了吞吐量。PD分离技术可以把两个阶段的任务配置到不同GPU计算资源上,P节点由高算力GPU集群构成,专注于处理所有新请求的Prefill阶段,生成KV缓存。D节点由高显存带宽GPU集群构成,专职处理已存在KV缓存的Decode阶段,负责所有Token的生成工作。
两个节点分工的关键在于通过高效的KV Connector(如PyNcclConnector或MooncakeConnector),将P节点计算出的KV缓存传输给D节点继续处理。PD分离技术的工作流程是用户请求先由P节点处理,P节点执行Prefill并生成KV缓存。随后,P节点通过KVTransferConfig将缓存等元数据传递给D节点。最后,D节点基于获取的KV缓存执行Decode阶段,迭代生成最终回复。
KV缓存精度:KV缓存精度(KV Cache Quantization)旨在通过调整KV缓存的数据存储格式,降低显存占用,让有限的显存能同时服务更多请求。KV Cache本质是Transformer模型中存储键(Key)和值(Value)张量的大块显存。降低其精度,相当于用更低的精度存储中间结果,以换取存储空间。在大模型推挤阶段KV缓存的显存占用常常是瓶颈。降低其精度可以直接减少显存占用,从而增大批次大小(BatchSize),提升吞吐量并支持更长的上下文。
主要精度选项(kv_cache_dtype):
auto:默认值,使用模型本身的精度(如BF16/FP16),精度最高,但显存占用也最大。
fp8:推荐精度,将KV缓存压缩为8位浮点格式,在精度和效率间取得绝佳平衡。实测显示,使用FP8后,吞吐量可提升60%,并发处理能力提升5倍以上。
fp8_e4m3/fp8_e5m2:两种FP8数据格式。e4m3动态范围稍小但精度更高,通常为首选。
实验室为更高治理地实施Token工厂项目,通过实验分析两类技术对推理性能的实际影响:
1.1 部署形态:
默认vLLM
vLLM--enable-chunked-prefill
1P1D(1Prefill+1Decode)PD分离
1.2 KVCache精度:
FP16
FP8
重点考察它们对以下性能指标的影响:
TTFT(Time To First Token,首token延迟)
TPOT(Time Per Output Token,单输出token时间)
ITL(Inter-Token Latency,token间时延)
E2EL(End-to-End Latency,端到端延迟)
Throughput(吞吐,tok/s)

02 实验配置
根据实验表格,主要设置如下:
并发数:2
输入/输出长度:1024/512
Model max len/max token参数:2048
03 PD分离技术原理
PD分离(Prefill-Decode Disaggregation)的技术原理,是将一次推理请求中的prefill阶段与decode阶段部署到不同的vLLM实例上执行。其核心思想是:prefill负责处理长输入上下文、构建KV Cache,decode负责基于已生成的KV Cache持续输出后续token。通过这种方式,系统可以分别为prefill和decode配置不同的并行策略、显存预算和硬件资源,从而实现对TTFT和ITL的分开调优。vLLM官方文档将其定义为一种实验性特性,并指出这种架构的目标是实现prefill与decode的资源解耦,而不是直接提升单实例吞吐。
在实际部署中,PD分离通常由Proxy/Router作为统一入口。客户端仍然像访问普通OpenAI兼容接口一样,向Proxy的/v1/completions或/v1/chat/completions发起请求;随后Proxy选择一组可用的Prefill实例(P)和Decode实例(D),为该请求生成唯一的request_id,并将请求分别转发给两侧。按照官方P2PNCCLConnector的流程,Proxy会先把一个“只做prefill”的请求发给P端,再把原始请求发给D端,随后由P端生成KVCache,并通过KV传输连接器发送给D端,D端在收到KV后继续执行第一次decode并开始输出结果。
从端口监听的角度看,PD分离至少涉及两类端口。第一类是每个vLLM实例对外提供推理服务的HTTP端口,例如prefill实例监听8100,decode实例监听8200,这些端口用于接收Proxy转发过来的OpenAI风格请求;第二类是用于KVCache传输和握手的端口,例如kv_port,它不直接对客户端暴露,而是由P/D实例之间的connector使用。
04 实验结果概览
4.1 TTFT(首token延迟)
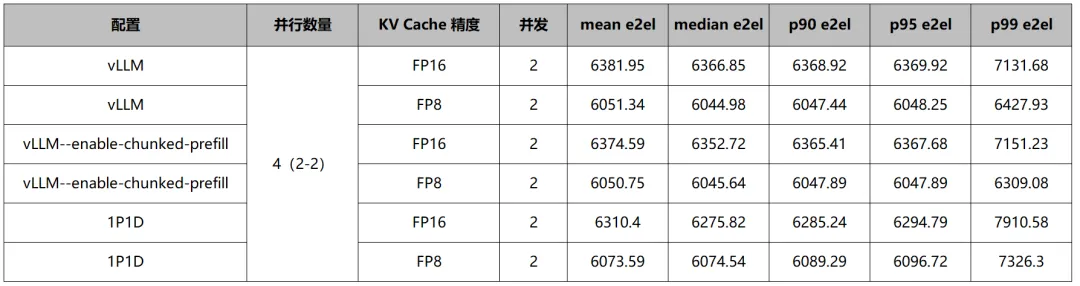
表1:不同配置在TTFT(ms)的表现差异
观察:
在普通vLLM和vLLM+chunk prefill中,FP8与FP16的TTFT基本接近,尤其是中位数的差距在0.01ms级别。FP8的p99 TTFT数值相比FP16显著降低,整体表现更加稳定。
1P1D中,FP8的TTFT明显恶化,从168.12上升到205.25。说明在PD分离场景下,低精度KV Cache对首token阶段更敏感。
从尾延迟看,1P1D的p99 TTFT很高。这说明PD分离会带来更明显的尾部抖动,即使1P1DFP16精度有着最好的中位数TTFT,但极端请求延迟更容易被拉高。但同时FP16精度下1P1D的中位数达到了最佳结果。说明了大部分情况下该配置优化了首token的生成。
综合来看,KV Cache精度对TTFT的影响具有明显的部署相关性。在普通vLLM和vLLM+chunk prefill场景下,FP8与FP16的平均和中位数TTFT基本持平,而FP8在p99指标上反而更优,说明单机一体化推理链路中,低精度KV Cache并不会显著伤害首token性能,甚至有助于提升尾延迟稳定性。但在1P1D的PD分离场景中,FP8的TTFT明显变差,且整体尾延迟抖动更突出,说明此时首token性能已不再主要受计算本身限制,而更多受到KV传输、跨实例调度、缓冲与同步开销的影响。也就是说,FP8的收益主要体现在稳态decode阶段,而PD分离带来的链路复杂度会放大首token路径上的不确定性。因此,如果系统目标是提升吞吐和长期生成效率,FP8仍然是有价值的优化方向;但如果业务更看重交互式体验中的首token延迟和尾延迟稳定性,那么在PD分离架构下,需要更加谨慎地评估FP8 KV Cache的实际收益。
4.2 TPOT(单输出token时间)
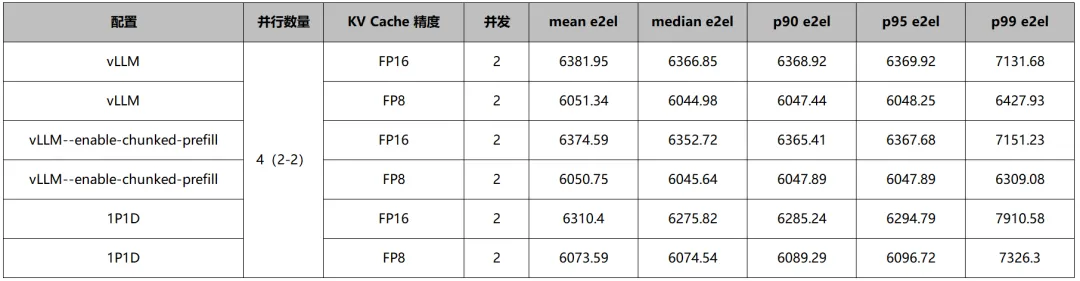
表2:不同配置在TPOT(ms)的表现差异
观察:
所有配置下,FP8的都优于FP16/BF16。
说明KV Cache量化对decode阶段的持续生成效率帮助明显,因为KV占用下降后,访存压力减轻,token生成速度更快。
普通vllm和vllm+chunk在TPOT上的表现近似,1P1D在0.1ms级上有一定的提速。
综合来看,FP8 KV Cache在decode阶段带来的收益是稳定且一致的。无论是普通vLLM、vLLM+chunk prefill,还是1P1D,FP8在TPOT指标上都优于FP16/BF16,说明KV Cache量化确实能够有效降低decode过程中的访存负担,从而提升持续生成阶段的token输出效率。从不同部署形态的横向比较来看,普通vLLM与vLLM+chunk prefill在TPOT上几乎没有差异,表明chunk prefill主要影响的是prefill阶段,对稳态decode性能影响有限;而1P1D在0.1ms量级上进一步降低了TPOT,说明PD分离在将prefill与decode负载解耦后,能够让decode侧获得更稳定、更纯粹的计算资源,从而在持续生成阶段体现出轻微但可观测的提速效果。因此,可以认为:KV Cache精度决定了decode的基础效率,而PD分离更多是在资源调度层面进一步优化decode的执行环境,但是目前观测到的优化程度有限。
4.3 ITL(token间时延)

表3:不同配置在ITL(ms)的表现差异
观察:
ITL与TPOT走势基本一致。FP8的收益主要体现在decode阶段的连续token生成,而不是统一地改善所有阶段。
实验结果表明,FP8在所有配置下都能带来更低的ITL,这说明KV Cache量化的主要收益并不体现在首token生成或整体链路各阶段的普遍优化上,而是集中体现在持续生成阶段的访存开销降低与解码节奏加快。换言之,FP8更像是一种针对decode路径的专项优化:它通过减少KV Cache占用、缓解显存带宽与访问压力,使模型在长序列生成过程中保持更快的token输出速度。从PD分离与不分离的对比来看,ITL在不同部署方式下整体差异不大。普通vLLM与vLLM+chunk prefill的ITL也基本接近。此处表现与预期并不相符,没有体现出PD分离对推理阻塞问题的优势。后续扩张prompt和输出长度也没有体现出PD分离和普通配置之间的差异。
4.4 推理端:E2EL(端到端延迟)

表4:不同配置在E2EL(ms)的表现差异
观察:
从端到端结果看,FP8一致优于FP16。
说明虽然1P1D下FP8的TTFT变差,但在整个请求生命周期内,decode侧收益仍然足以让E2EL总体下降。在平均数和中位数对比中依然有优秀的表现。
从E2EL(端到端延迟)结果来看,FP8在所有部署配置下均优于FP16/BF16,说明KVCache量化带来的收益不仅体现在单个token的生成速度上,也最终传导到了完整请求的总完成时间。普通vLLM与vLLM+chunk prefill的E2EL表现非常接近,说明chunk prefill对整体端到端时延的影响较小,其作用更多体现在prefill阶段的调度方式调整,而不会显著改变完整请求的执行效率。相比之下,1P1D的E2EL在不同精度下也保持了较好的水平:虽然PD分离在TTFT上引入了一定额外开销,但在后续decode阶段,由于prefill和decode负载被拆分,decode侧资源竞争减轻,因此整体端到端延迟并未恶化,反而在部分配置下表现更优。
05 PD分离的影响分析
从与普通vLLM的对比结果来看,PD分离对平均性能的影响整体较小。在FP16配置下,1P1D的mean TTFT仅比普通vLLM高约1.39%,而E2EL反而下降约1.12%,Throughput也提升约1.11%,说明在本实验设置中,PD分离并没有明显拉低系统的平均吞吐或平均端到端性能。进一步看分位数指标可以发现,1P1D在中位数TTFT上甚至具有一定优势,说明对于大多数常规请求而言,PD分离后的prefill与decode负载解耦并不会显著拖慢首token返回,部分情况下还可能因为decode资源更独立而表现更优。然而,PD分离的代价主要体现在尾部时延的放大上:其p99 TTFT明显高于普通vLLM,表明在少数极端请求中,分离后的链路更容易受到调度、通信、KV传输和同步开销的影响,从而产生更强的尾部抖动。也就是说,PD分离的核心特征并不是显著改变平均性能,而是在“中位数表现尚可、甚至略优”的同时,引入更高的尾延迟风险。对于关注整体吞吐和平均完成时间的场景,这种代价可能是可以接受的;但对于高度依赖首token稳定性的在线交互服务,则需要特别关注这类尾部抖动带来的体验波动。
值得注意的是,PD分离显著提升了对显存的需求。不仅要使用P和D两端两个实例加载完整模型,KVCache在传输调度的过程中会需要额外的缓冲。这导致在使用同样数量GPU的情况下,PD分离只能配置较小的上下文长度,接受更小的prompt,并且有更高的OOM风险。这也是局限本实验使用小prompt/output的原因。
06 KVCache精度的影响分析
从整体结果来看,FP8的主要收益集中体现在decode阶段。无论是TPOT、ITL、吞吐还是E2EL,FP8相比FP16/BF16都表现出较为一致的改善,这说明KV Cache量化的核心作用在于降低KV的存储与访存成本,使模型在持续生成过程中读取历史上下文的负担更轻,从而提升连续token输出效率,并最终转化为更高的整体吞吐和更低的端到端时延。
相比之下,FP8对TTFT的影响则表现出明显的不稳定性。在普通vLLM场景下,FP8与FP16的TTFT基本接近;在vLLM+chunk prefill中,FP8还表现出一定改善;但在1P1D的PD分离场景下,FP8的TTFT却明显恶化。这说明KV Cache量化对首token阶段并不是单调增益,其效果会受到具体系统链路的强烈影响。尤其在PD分离架构中,首token生成不仅依赖prefill本身,还会受到prefill与decode之间KV传输、cache格式转换或序列化、量化与反量化带来的启动开销,以及调度与同步机制的共同影响,这些额外因素会放大首token路径上的不确定性。因此可以认为,FP8更适合作为面向吞吐和总时延的优化手段,而不是保证最佳首token体验的通用方案。
07 结论
综合本次实验可以得出如下结论:PD分离与KV Cache精度优化对推理性能的影响具有明显的阶段性和目标导向性。从整体趋势看,FP8的优势主要集中在decode阶段,其在TPOT、ITL、吞吐和E2EL上均表现出较为一致的改善,说明KV Cache量化能够有效降低显存占用和访存压力,从而提升连续生成阶段的效率;但在TTFT上,FP8的收益并不稳定。另一方面,PD分离本身并未明显拉低平均吞吐或平均端到端时延,甚至在中位数指标和decode稳态性能上表现出一定优势,但其代价在于更高的尾延迟风险,即少数请求更容易受到链路复杂度影响而出现显著抖动。
基于以上结论,建议在实际部署中根据业务目标进行针对性选择:如果系统更关注吞吐、长文本生成效率和整体完成时间,则优先考虑采用FP8 KV Cache,并结合普通vLLM或vLLM+chunk prefill部署,以在保证整体稳定性的同时获得更高的decode效率。PD分离仍具有实际价值,但需要重点优化KV传输缓冲、调度策略与并发控制,以降低尾部抖动对用户体验的影响。
附件:
A.1、PD分离情况下GPU使用情况
GPU0和GPU1:prefill GPU
GPU4和GPU5:decode GPU
GPU Utilization Percentage:在单位采样时间里,计算核心有多少时间在工作
GPU Memory UtilizationPercentage:在采样周期内,GPU的显存带宽接口有多大比例的时间在进行读写
Prefill GPU的工作特点:相对低的基线,间歇性峰值。这符合prefill处理的特点:一次性编码prompt,建立KVcache。并且prefill单次计算量大,但持续时间短,导致了间歇性峰值的出现。
Decode GPU的工作是持续性的,算子在推理过程中不断被调度,稳定处在高位状态。偶尔出现的下探型尖峰代表着活跃序列数变化,调度与通信的开销。而且GPU4明显比5更忙,体现出了负载的不完全均衡。
下图符合PD分离的预期,prefillGPU表现为突发式、低占空比的脉冲负载;decodeGPU表现为持续式、高占空比的平台负载。说明系统已经把prompt编码与逐token生成两个阶段有效解耦,并分别落在不同GPU上执行。
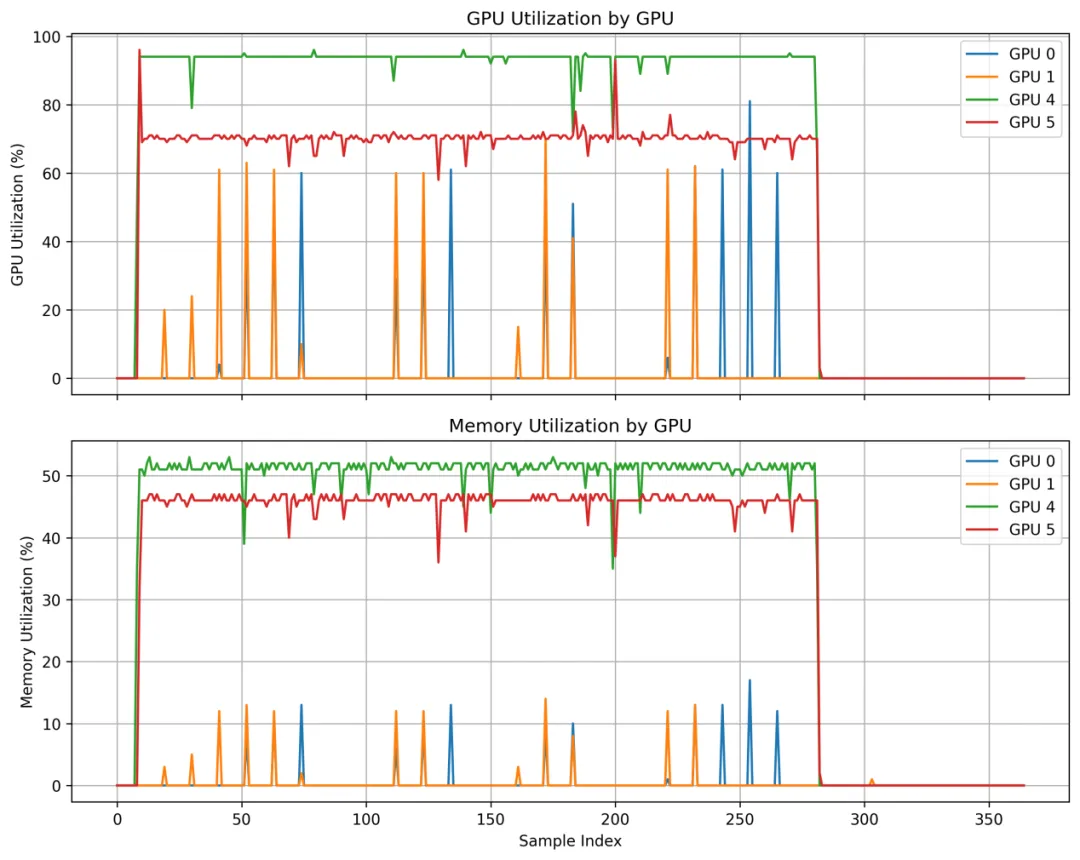
图1:PD分离下GPU采样时间内的工作情况
A.2、普通四卡并行情况下GPU使用情况
在没有PD分离的情况下,四张GPU都呈现出持续性工作,偶有突发的情况。每张卡都同时在做prefill+decode,所以四张卡的曲线形态更相似、更混合。不再有PD分离时清晰的波动形状。而且负载情况并不均衡,GPU0的算子工作明显低于其他GPU,而GPU1的显存带宽占用情况同样要低于别的GPU。
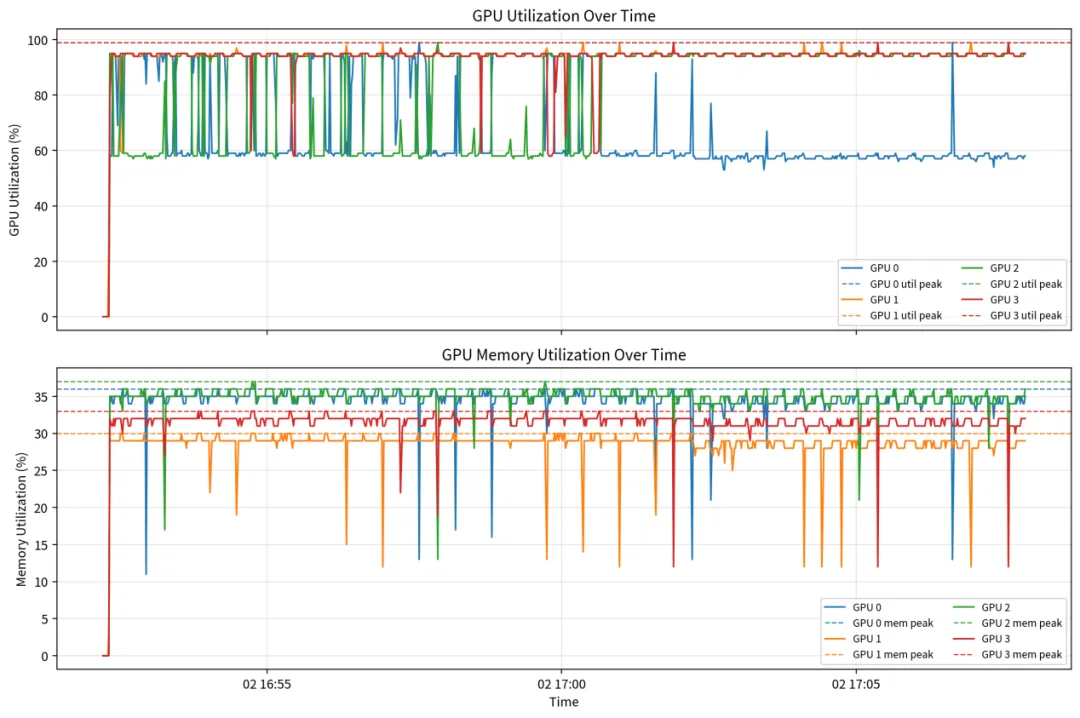
图2:四卡并行推理,无PD分离下GPU使用情况


【原创声明】本文由“国药数科”公众号原创出品,引用或转载请注明公众号出处。如需交流合作,请联系国药数科公众号或邮箱:liangwenge@sinopharm.com。
END

内容来源:科技创新中心
点击关注 了解更多
