 夜雨聆风
夜雨聆风
在 TransLit 的之前版本中,“AI Review”模式只是为了处理像 Gemini 2.5 Pro 偶尔出现的语言混杂问题。当时模型在翻译时常会蹦出一些不属于原文的外语单词,我希望再次校对译文来过滤掉这些词汇。
读过思果的《译后交稿或付印前的检查工作》一文(收录于《翻译研究》),思路有了变化。我觉得“校对”也许不仅是debug,还可以尝试改善中文表达。于是,我根据书中的原则重写了校对提示词。
在实际测试中,这种基于纯译文的校对方式对知识性书籍效果尚可,但在处理小说类文本时,准确度却明显下降——由于校对环节缺失了原文约束,模型在追求“洗练”时容易出现语义偏差。
我不禁联想到许多转译本(从英文译本翻译出的中文译本),产生了信任危机。
为了在“少费 Token”(不用在校对时一并附上原文与译文)与“保持信度”之间寻找平衡,我开始测试一种古老的 AI 翻译技术:两步法。
重新发现“两步法”

此图使用 Nano Banana 2 生成,抄袭自天津美术学院通识课教学展的一幅作品[1]。
“两步法”是在模仿人工翻译流程,包括初译和审校两步。为了省 Token,这两步在每个分片内依次进行,最后写成结构化提示词:
export const TWO_STEP_BASE_PROMPT = `你是一位精通[SOURCE_LANG]与中文的文学翻译和审校专家。请执行“初译”与“审校”两步法任务。### 第一步:初译 (遵循以下律法)【遗忘之律】忘记[SOURCE_LANG]的句法和语序,只保留原意。【重生之律】设想你是中国作者,面对中国读者,用自然的中文讲故事。【地道之律】追求“写得真好”而非“翻译得真好”。注意短语的节奏、口语的亲切感。【真实之锚】数据不改,事实不动,逻辑完整,术语标注:大语言模型(LLM)。### 第二步:审校润色 (重塑中文字韵)1. **精简代词**:审视并剔除不必要的“我的”、“你的”、“他的”等代名词。中文习惯通过语境表达所属关系,非必要不保留。2. **剔除虚词量词**:精简如“一个”、“一种”、“一项”等不具实际意义的修饰语,避免句子结构臃肿。3. **“的”字减法**:检查句中的“的”字。原则上一句之内不宜超过三个;若觉读来绕口,请通过拆句或重组结构予以优化。4. **语态转换**:将生硬的被动语态(如“被...”、“受到...”)重组为自然的主动语态或习惯性表达。5. **删繁就简**:删去不影响文义、文气的赘言;对语意不足处做精练补全,确保文字气韵贯通。6. **主谓匹配**:严格校验动作与主体的逻辑。注意动词的适用对象(如“挨近”通常用于人而非物),确保字词妥帖。7. **动宾精当**:纠正搭配不当的动宾关系。若一个动词带多个宾语,须逐一核对,确保每个词都“用得顺”。8. **自然化读**:以“不通英文的读者”为基准,确保全文朗朗上口,无任何欧化翻译痕迹。`;export const FMT_TWO_STEP_GLOSSARY = `### 结构化输出要求请严格遵循 XML 标签格式分块输出,确保结果纯粹干净。严禁以“第一步”、“第二步:最终审校润色...”类字眼作为小标题混入正文。<translation_draft>在此处仅输出第一步的初译正文内容。</translation_draft><translation>在此处仅输出经过最终审校润色后的目标语言内容,不可包含任何说明性引导语或标注。</translation><glossary>只提取本段新发现且未在已知术语表中出现过的高风险/专有词汇。严禁发散。请严格遵循单行配对格式,若无新术语则留空该标签内心:SOURCE: 原文词汇 | TARGET: 译文对应词汇</glossary>`;这种形式的提示词在 AiNiee 里叫做“思维链”。想起之前刷到的,只是把问题重问一次,AI 回答的质量就会有提升,可能也是同理。
缺点就是带来了更明显的延迟,为了程序的稳定性,我还减短了分片长度。于是,TransLit 又有了更慢的翻译模式——Two-Step。
“只有机器才会欣赏另一个机器写出的——”
为了观察这一流程的效果,我使用 Gemini 3.0 Flash 作为唯一的翻译模型,分别生成了“两步法(Method A)”和一次性“重写法(Method B)”的译文。随后,我邀请了三个主流模型 ChatGPT、Gemini 自己和 Kimi 作为独立评估者进行打分。
测试用到了两个领域的文本:韩炳哲的《Der Geist der Hoffnung》(学术文本)与 Nicholson Baker 的《The Fermata》(文学文本)。
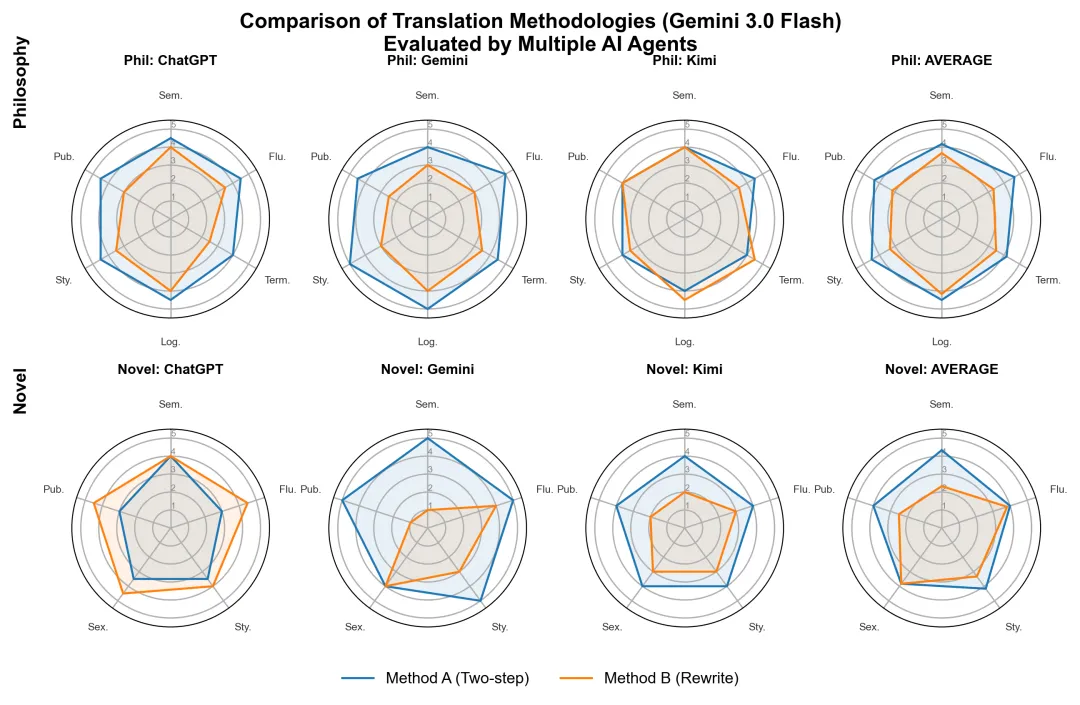
本图汇总了学术类(Philosophy)与文学类(Novel)文本在两步法(Method A)与重写法(Method B)下的对比结果。坐标轴缩写包括:Sem(语义准确性)、Flu(流畅度)、Term(术语准确性)、Log(逻辑结构)、Sty(风格保留)、Pub(出版适配性)、Sex(性描写处理)。评分由三个主流 AI 模型独立盲测得出,最后一列为综合平均分。
可以看到,在哲学翻译中,三位评估者认为“两步法”在逻辑结构、术语准确性等方面得分更高。
而在小说翻译中,评分出现了分歧。虽然平均分仍是两步法占优,但 ChatGPT 认为“两步法”译文流失了作者的风格,反映出文学审美的不确定性。
不插手“翻译的艺术”

如果只让 AI 读,翻译都是多余,还是要自己读读看。
《Der Geist der Hoffnung》是德语书,只附上其中一段话的“重写法”和“两步法”对比:
| 这恰恰是人工智能(AI)无法思考的原因 | 人工智能之所以无法思考,原因便在于此 |
相比之下,“两步法”的语言确实书面一些、少一些赘余。
但不得不承认,“两步法”更像是“文字滤镜”,只是给译文瘦了脸、磨了皮。好的中文凝结了复杂的个人品味,很难通过一段简短的指令完全复制。何况,思果的准则虽然提供了汉语的审美选择,但这只是众多翻译流派中的一种。
我的想法是:我只负责完成翻译的“工程”,而不插手翻译的“艺术”。
总之,“两步法”只是 TransLit 提供的一种翻译模式,它可以润色汉语,但也可能失掉原味,还会让翻译过程变得繁琐且缓慢。不妨想想,谁都知道翻译的艺术很重要,但对于阅卷速度的读者来说,又能接收多少呢?
只能说是一番心意。
http://xhslink.com/o/1lBaUy7ImM7
