 夜雨聆风
夜雨聆风跨会话记忆系统是 ClawCode 最大的差异化能力,也是为什么它能比 Cursor 和 Copilot"更像队友"

开篇
先想一个问题:你的 AI 编程助手,记得住你的名字吗?

这听起来是个玩笑,但试试看:
告诉 Cursor:"我们项目用 Axum框架,你不用问我了"关掉编辑器,喝杯咖啡 打开编辑器,新会话
结果通常是这样:
"帮我在项目中加一个 HTTP 路由" "好的,用 Actix-web实现……"
它忘了。不是你说了它没听懂,而是它根本没有"记住"这个功能。
一、为什么 AI 编程助手普遍"不长记性"?
1.1 会话窗口的诅咒
所有的 AI 编程助手都基于 LLM(大语言模型)。而 LLM 有一个根本限制:
每次对话都是一个新的上下文窗口。
即使是最先进的模型(DeepSeek V4 的 1M Token、Claude 的 200K Token),也解决不了跨会话的记忆问题。每次新会话都是"重新开始"。
1.2 这不是模型的问题,是架构的问题
Cursor 之所以记不住,不是因为 Claude 或 GPT 不够聪明,而是因为 产品层没有设计记忆系统。它把每次对话当成独立的""黑盒事务"",而不是一个持续演进的过程。
| ClawCode | ✅ 有 | 专门设计了记忆系统 |
结论:跨会话记忆不是 AI 能力问题,是工程架构问题。
二、ClawCode 的解决方案:四层记忆架构
ClawCode 设计了一套完整的记忆系统(claw-memory crate),参考了认知科学中的人类记忆模型。
2.1 架构全景
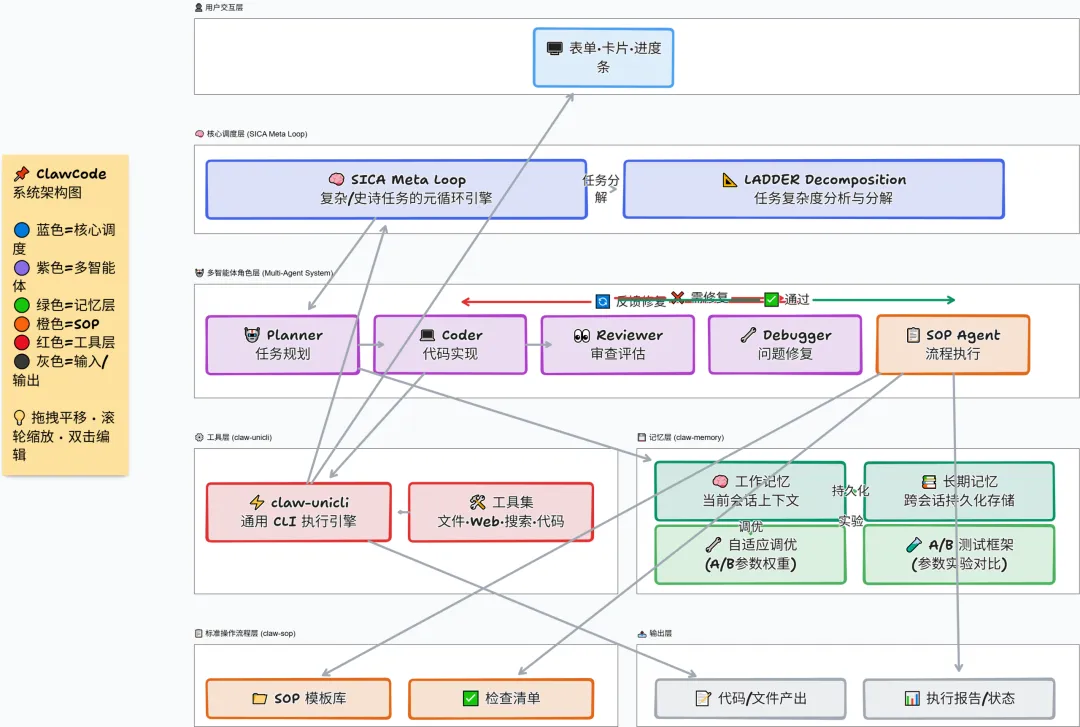
2.2 工作记忆(Working Memory)— 代码实现
工作记忆是最底层的记忆层,对应我们当前的"思考空间"。
每个会话有自己的工作记忆。当条目数超过容量时,最旧且重要性最低的条目会被淘汰。
2.3 长期记忆(Long-term Memory)— 核心数据结构当工作记忆中的条目被认为"重要"时,它会被提升到长期记忆,并持久化到 SQLite。
关键设计:每个记忆记录都带 importance 和 access_count,这是后面"遗忘机制"的基础。
2.4 衰减机制(Decay)— 该忘的得忘
人脑会遗忘,好的记忆系统也应该会。ClawCode 实现了主动遗忘机制:
简单说:
- 经常访问的记忆
→ 权重增强,保留更久 - 长时间不访问的记忆
→ 权重衰减,最终被清理 - 半衰期配置
:默认 30 天,可自定义
2.5 反射机制(Reflection)— 自动提炼核心信息
最有趣的设计:反射机制 定期扫描工作记忆,自动识别哪些信息值得记住。
反射流程:
工作记忆条目数达到阈值 → 触发反射 扫描所有条目,计算重要性评分 重要性高的 → 提升到长期记忆 相关的条目 → 合并成摘要 冗余/低价值条目 → 清理
三、实际效果:ClawCode 的"记忆"长什么样?
场景 1:记住项目约定
bash
# 会话 1 用户:我们项目用 Axum 框架,所有 handler 放在 handlers/ 目录下 ClawCode:好的,我已记住这个约定。 # 会话 2(第二天) 用户:帮我添加一个用户注册的 handler ClawCode:好的,按照约定,我在 handlers/user.rs 中创建注册 handler。 (它记得!不需要再重复说)场景 2:记住开发者偏好
bash
# 在多次交互后,ClawCode 自动学习 用户:这个函数命名改成 snake_case ClawCode:好的,已修改。我记住了你的命名偏好:函数名使用 snake_case。 # 后续代码生成 ClawCode:我来生成这个模块... (自动使用 snake_case 命名规则)场景 3:跨会话的 Bug 修复记录
bash
# 会话 1 用户:这个数据库连接泄漏了,需要加事务管理 (修复完成后,问题记录被存入长期记忆) # 会话 2(一周后) 用户:分析一下数据库连接代码 ClawCode:我注意到这个模块之前有过连接泄漏问题, 这次的改动没有包含事务管理,建议加上。 (它记住了历史问题!)四、技术难点与取舍
难点 1:什么该记住,什么该忘?
这是记忆系统最核心的难题。ClawCode 的做法:
通过 重要性评分 + 衰减机制 自动完成筛选,不需要用户手动管理。
难点 2:记忆冲突
如果同一条信息出现矛盾怎么办?
ClawCode 实现了对抗性验证模块(adversarial.rs),专门检测记忆矛盾:
默认使用 KeepHighest 策略,保留重要性评分更高的那条记忆。
难点 3:性能
跨会话记忆需要持久化存储,每次对话都要加载相关记忆,会增加响应时间。
ClawCode 的优化:
- 延迟加载
:只在需要时检索记忆,不全部加载 - 缓存机制
:高频记忆缓存到内存 - 语义搜索
:用向量嵌入搜索相关记忆,而不是全量扫描
五、总结
AI 编程助手的"记忆"之所以难做,不是因为 AI 不够聪明,而是因为这个问题需要一套完整的系统工程。
ClawCode 用 4 层记忆架构(工作记忆 → 短期记忆 → 长期记忆 → 元记忆)解决了这个问题,包含 15+ 个子模块、4000+ 行 Rust 代码。
这不是一个"能加就加"的特性,而是整个产品的核心架构设计。这也是为什么 Cursor 和 Copilot 至今没有跨会话记忆——要从零补上这个能力,需要重写大量的基础架构。
下一篇文章预告:《跨会话记忆系统设计(上)——SQLite 持久化与向量检索》,我会详解记忆数据的存储、检索和语义搜索的实现。
📦 项目开源:gitee.com/networkadmin/clawcode📢 公众号:AI养成笔记💬 作者微信:zgsm33⭐ 觉得有用请点个 Star,感谢支持!
