 夜雨聆风
夜雨聆风
三层等价
让算法跑进 FPGA 的方法论
最近想给 Python2Verilog 框架找个新的应用方向,顺手挑了高频交易这种"低延迟到极致"的场景。结果第一轮就交了大笔学费。
我先拿了一份网上能找到的 tick-to-trade VHDL 参考代码,丢给 Claude Code,让它"自动"按 Python2Verilog 的三层架构改写:算法模型、周期仿真模型、Verilog RTL。Auto Mode 打开就出门了,期待回来时它已经迭代出一个性能更好的版本。
token 烧了不少,输出几乎不能用。
把架构决策外包给 AI,是这件事最贵的错误。
1AI 不会替你识别"参考实现写错了"
那份 VHDL 参考用了一个朴素到有点笨的结构来做订单匹配:所有价位塞进一组寄存器,并行比较器一通排序。算法逻辑没错,但代价是 FPGA 资源消耗按"价位数 × 标的数"线性放大。撑死能跑几只股票。
AI 拿到这种参考会做什么?它会在这个错误的骨架里继续优化。流水线再深一点、字段再压几位,但骨架没动,扩展性问题原封不动。
之前写过一篇文章讲在 FPGA 上让 AI 自主实现 LDPC 译码器,那次也是同样的剧情:AI 不掌握"系统架构应该长什么样"的领域知识,只能在你给它的脚手架里做局部优化。
硬件架构师那一关,省不掉。
2真正卡住人的,是订单簿装不进 FPGA
把交易策略本身放一边不谈,光看数据通路,最难的就是订单簿(order book)。
每只股票都得维护自己的"最优买卖价"和一张完整的"价位到数量"映射表。要支持很多只股票同时跑,存储压力直接起飞。
FPGA 的存储是分层的:寄存器最快、BRAM/URAM 次之、再下来是片内 HBM、最后是片外 DRAM。越靠上越快越小,越靠下越大越慢。
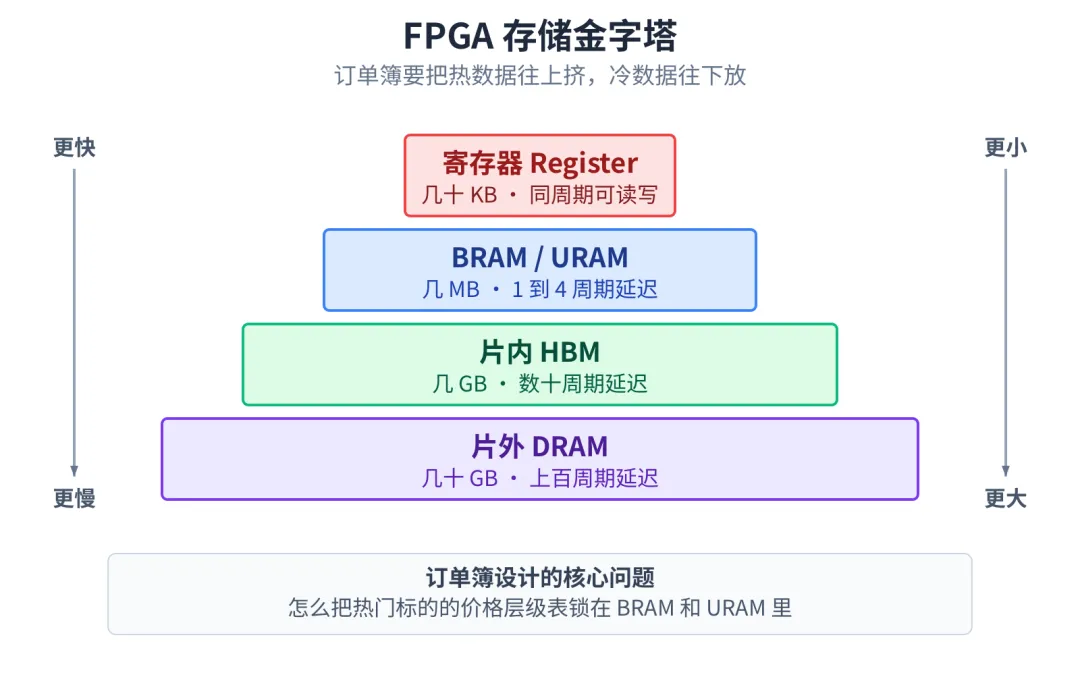
FPGA 存储金字塔,热数据要往上挤
热门标的的订单簿要锁在 BRAM 和 URAM 里;冷门标的可以下沉到 HBM;超大规模才往 DRAM 走。这套思路像极了 CPU 的 Cache 层级,但 FPGA 不会自己给你做 Cache,得自己设计:
- ▶L1(寄存器):最热的几只标的最热的几个价位
- ▶L2(BRAM/URAM):主力标的的完整价位表
- ▶L3(HBM/DRAM):冷数据兜底
这种"按热度分层"的存储结构,AI 不会自己想出来。给它讲一遍它能照做,但你必须先自己想清楚。
3转折点:从算法模型开始,不是从代码开始
吃过这个亏,重新捋了一下 Python2Verilog 在以前那些成功案例里到底做对了什么。
答案其实早就在那儿:先建立一个算法层的"金标准",所有后续设计都对照它做。
高频交易这种领域,社区里有验证过的开源参考,比如 hftbacktest 这个项目,把限价单、队列位置、各种延迟都建模进去了,能直接喂真实交易数据回放。
我让 Claude Code 参照这个项目,先把 Python 算法模型写出来。注意是参照算法,不是抄代码。换一种语言、换一种数据结构都可以,但行为要对得上。算法模型一旦验证通过,它就成了后面所有迭代的不动点。
然后才开始设计硬件结构和电路微结构,再翻译成周期仿真模型,最后才是 Verilog。

三层等价方法论:math 到 cycle 到 RTL
这套方法论的关键是每一层都明确知道在跟谁对照:算法层对照行业规范,周期层对照算法层,RTL 层对照周期层。哪一层不一致,回退一格就行,不会一路懵到 P&R 才发现根因。
业界最快的 tick-to-trade FPGA 实现已经做到几十纳秒级,整体水平在百纳秒到几百纳秒区间。在这个量级上做对,靠 vibe 调试是不可能的。
✅ Tip
复用社区认可的开源算法当算法层金标准,比从论文公式从零推一遍稳得多,也比让 AI 自己造一个稳得多。
4顺手做出来的副产品:通用原语库
走通了订单簿,再去看其他几个大块(风控、策略、下单编码),有一个意外发现:解决高频订单簿的那几个硬件结构,跟其他事件驱动场景需要的结构是同一批。
- ▶优先级存取:取最优买卖价,本质是 Top-K
- ▶键索引哈希表:从 order_id 找记录,跟从 5 元组找网络连接没区别
- ▶读改写聚合:同一个 BRAM 单元做累加
- ▶多端口冒险转发:写后立读不丢拍
- ▶工作集缓存:热数据 L1,温数据 L2,冷数据 L3
这些都不是 HFT 专属。把 key 宽度、深度、端口数当参数交给用户,同一份 RTL 在网络流表、KV 存储、调度器优先队列、遥测聚合这些场景里都能直接复用。
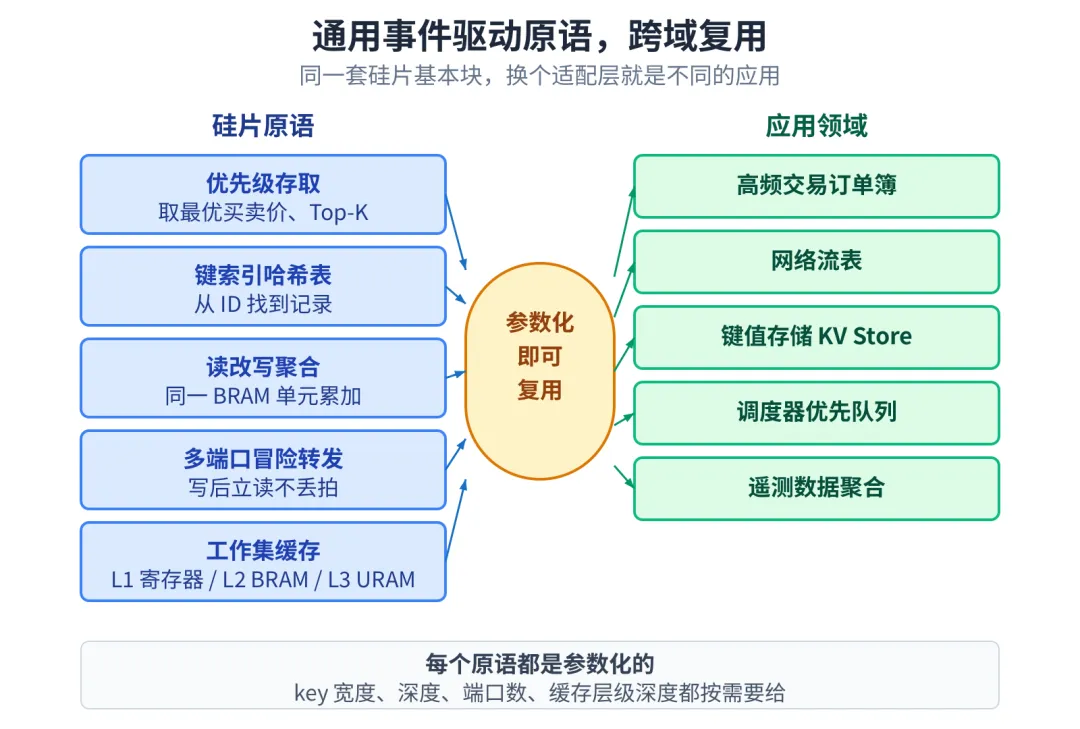
通用事件驱动原语,跨域复用
我们干脆把这些抽象成一组通用事件驱动原语,每个都按 math 到 cycle 到 RTL 走完三层验证。HFT 的端到端流水线,就变成在这些原语之外薄薄的一层"协议适配"。
5端到端跑通了什么
到现在,从真实的 NASDAQ ITCH 行情数据进,经过协议解析、订单簿更新、策略报价、风控校验、下单编码,到 OUCH 下单帧出,整条流水线已经跑通。
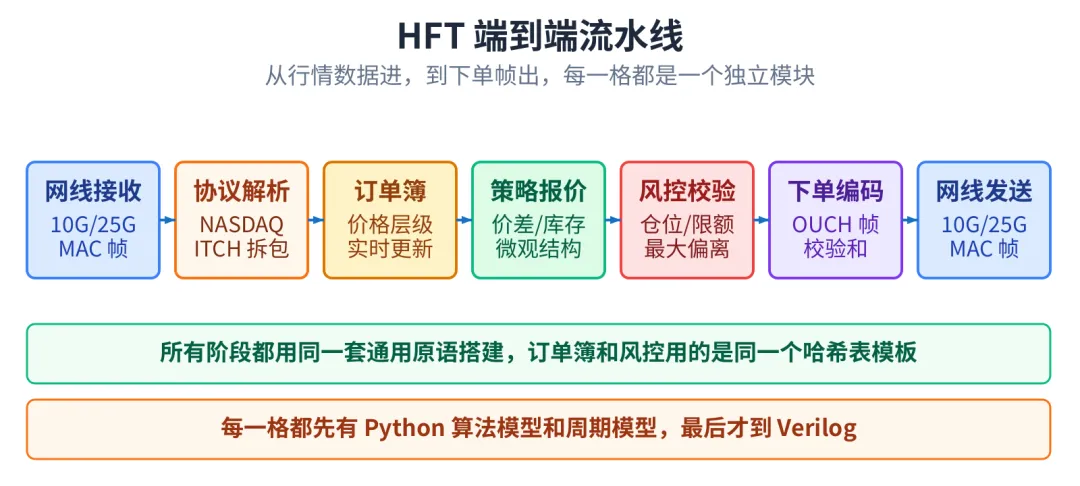
HFT 端到端流水线
每一拍的输出都和 hftbacktest 算法层、Python 周期模型字节级对得上。再喂同一份测试向量进 cocotb 仿真,RTL 输出和周期模型也字节级对得上。三层咬合得很紧。
具体的延迟和资源数字,留到后面拆模块的章节再讲。光看一个数字没有意义,得看它包含了哪些阶段、用什么板子、什么时钟域、和谁对比。这一点的教训太多了,不能在 overview 里草草交代。
6后续章节
接下来这个系列会一篇一篇拆开讲:
- ▶第 02 篇:订单簿微结构。键即地址、Top-K 缓存、价格层级表怎么放
- ▶第 03 篇:事件驱动原语库。每个原语的接口、参数化方式、跨域复用案例
- ▶第 04 篇:策略和风控流水。在一个时钟周期内做完报价加校验
- ▶第 05 篇:多 symbol 和缓存层级。从单标的扩到几百只
- ▶第 06 篇:时序闭环实战。怎么跨过 Fmax 那堵墙,工程上踩了哪些坑
最后留一句给自己看的话:
AI 不是要替代硬件架构师,它是把那张草图画快 100 倍的助手。
把设计决策的笔握在自己手里,AI 才能在框架里跑得既快又准。
