 夜雨聆风
夜雨聆风
AI 圈搞 vibe coding 或前一阵养小龙虾的人,多少都干过同一件事:自己写一个 AI 信源扫描工具,把全网的 AI 资讯抓回来,每天早上像批阅奏折一样看一遍。
但是大多数人——包括我自己——这种工具用不过三五天,就彻底打入冷宫了。继续跑着,继续烧 token,再也不打开看。
这两天我看到”数字生命卡兹克“开源了 AI HOT——一个面向 AI 从业者的资讯精选系统。他做了三年自媒体,内部用的信源工具直接免费开放了。除了网站本身,还提供 RSS、REST API 和 Agent Skill 三种接入方式,配套的 GitHub Skill 仓库已经接近万星。
用了几天,我有一个明确的判断:至少在“中文 AI 资讯筛选”这个场景里,它是我目前用过最接近人类编辑判断的系统。
一、 我自己做过的两版工具,分别死在哪里
我用 Claude Code 和 OpenClaw 各做过一版 AI 信源收集工具,都没坚持下来。
复盘下来,DIY 信源工具最后用不下去,往往卡在两个地方:
信源管理混乱。 一百多个 RSS 全部塞进同一个池子里,OpenAI 官方博客和某个公众号搬运号在系统里地位完全一样。前者一年发不了几篇,每篇都重要;后者一天发八篇,几乎全是噪声。这种结构下,过滤器必然失灵。
信息过载下的筛选极难。 官方博客、论文、Twitter、公众号、媒体站全算上,AI 圈每天的新动态很快堆到看不完。怎么从里面挑出今天值得花十分钟读的那五条?这是个判断问题,不是抓取问题。但大多数 DIY 工具——包括我做的两版——都把工程精力 90% 花在了抓取上,判断这件事几乎没认真做。
二、 卡兹克的 aihot 做对了什么
我打开 aihot 后,最先注意到的不是界面,而是它和我之前那些 DIY 工具的关键差别:它没有把重点放在"抓更多",而是放在"筛得更准"。 我观察到三件事,分别对应解决了上面两个痛点。
2.1 第一件事:信源被分了三层。
按卡兹克本人的复盘,aihot 目前持续监控 168 个信源,每个都是他亲手挑的。抓取手段包括 RSS 订阅、HTML 爬取、调用对方公开 API、自费买的三方数据接口等。
这 168 个信源被分成了 T1 / T1.5 / T2 三层:
- T1 是一手官方源——OpenAI 官方博客、Anthropic 工程博客、CMU 博客- T1.5 是官方社交账号——比如 OpenAI 的官方 Twitter,内容比官网杂一些,权重低一档- T2 是大佬个人号、KOL、媒体、综合资讯站这个分级不是装饰。同一件事,T1 源发的就是比 T2 源的分高,官方源就是比二手转述的分高。在精选页上,你能很清楚地感觉到不同来源的权重不一样——这不是一个把所有 RSS 一锅炖的系统。
2.2 第二件事:每条信息都有「精选分」和「推荐理由」。
这是我看到最关键的设计。打开 aihot 精选页,每条内容除了标题、来源、摘要、原文链接之外,还有两个关键字段:
精选 XX 分——我观察了这两天的精选页,绝大多数条目分数集中在 60-80 分之间,看得出有一套打分标准在背后把关。
推荐理由——一句话告诉你为什么这条值得看。
下面几条是我在 5 月 9-10 日 aihot 精选页上直接看到的原始推荐理由,保留它的表达方式:
"Garry Tan 这套个人 AI 系统不是 PPT 产品,是他每天用到凌晨 2 点的大脑外挂,开源且逻辑清晰,做 AI 工作流的值得立刻 fork。""Antirez 用几千行 C 代码把 DeepSeek V4 Flash 塞进 128G Mac,本地跑 1M 上下文 coding agent,这才是真正的 AI 民主化时刻。""Lee Robinson 总结的 11 条建议没有废话,尤其是「别用 AI 写简历」和「简历要提 AI」反直觉但很真实。"注意看这些推荐理由——几乎没有 AI 味,给的是”为什么值得你点进去“的判断,而不是再给一遍摘要。这一点上,aihot 比我自己用 Claude 跑出来的东西好太多。我做的工具会说“这是一篇关于 X 的文章,介绍了 Y”,aihot 会说“这条值得看,因为 Z”。
2.3 第三件事:日报把碎片化条目折成了五大板块
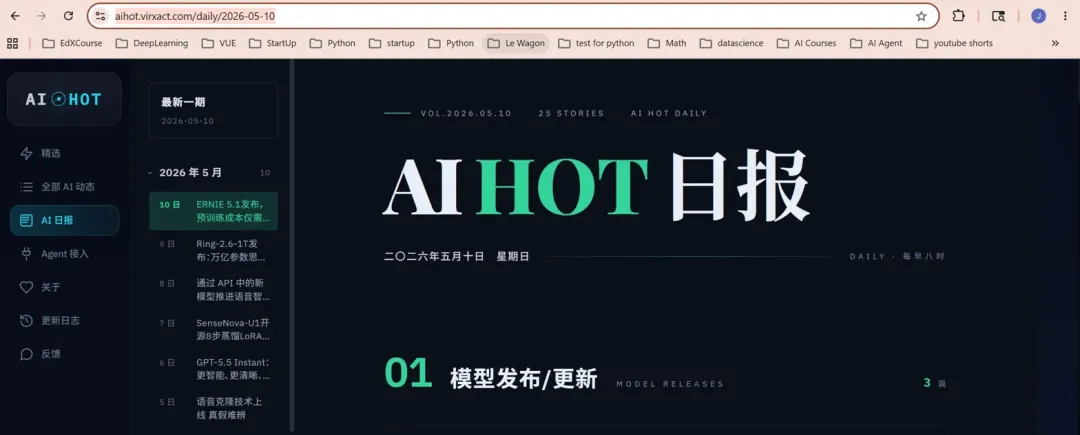
精选时间线是按时间倒序刷,刷起来像 Twitter。但真正可读性高的是日报。每天北京时间早上 8 点,过去 24 小时的精选会被自动归整成五块:
- 模型发布/更新- 产品发布/更新- 行业动态- 论文/研究- 技巧/观点板块化的好处是阅读节奏可以自己控:今天没空就只挑「模型发布」一块看,周末有时间就把「论文/研究」翻一遍。比纯按时间排列的时间线友好得多。
三、 这个产品最值得学的一课:能用代码就别用模型
到这里,对纯使用者来说信息已经够了。但接下来这一节,我想专门写给做 AI 产品的人看——因为 aihot 真正值得学的不是”它好用“,而是它怎么从”好用“走过来的。
卡兹克在复盘文章里讲了一个很坦率的故事。从今年 2 月开始做评分策略,到现在前后迭代了 11 版。最开始的版本是大多数人都会想到的做法:写一个 Prompt,让大模型给每条新闻打分,过阈值的就进精选。
跑出来一塌糊涂。硬核论文动不动 90 分但他自己看不下去;Sam Altman 转发实习生鸡汤推文模型给 87 分;同一件事被七家媒体报道,七条全进精选。
然后他往 Prompt 里加规则——大佬转发降分、重复事件降分、营销软文降到 50 以下,加着加着 Prompt 涨到 600 行。3 月份还配了人类反馈标注、500 条历史新闻的回归测试。"模型 + 人类反馈 + 自动评估 + 持续迭代",听起来非常教科书。
但是规则加得越多,模型反而越笨。V7 到 V8 那次直接是负向优化。最后他全面回滚,推倒重来。
转折点是他想起自己写过的一篇文章,标题叫《能用脚本就别用 Agent》。
你不能把所有事情都交给模型。打分是它、权重计算是它、打标是它、判断精选不精选还是它——什么都交给模型,模型就什么都干不好。
重构之后的架构变得非常干净:
- 大模型只做一件事:根据 Prompt 对每条信息打 5 个维度的分。不打最终分、不判断精选、不做任何其他事- Prompt 从 600 行砍到 200 行,模型职责被压到最纯粹- 打分之后所有逻辑都用代码写:信源权重、类型加权、是否过精选阈值,全部是明确的公式- 是否精选不由模型判断,而是用代码根据最终质量分判断有没有过该类别的精选阈值- 事件聚类用 embedding 实现——昨天 GPT-5.5 Instant 发布,OpenAI 官方加各路媒体可以刷出十几条;aihot 用 embedding 把语义相近的条目聚到一个事件簇里,簇里选一条最权威的当主条(官网 > 官方推特 > KOL),其他折叠还有一个我特别佩服的细节:每天早上 8 点的 AI 日报,完全不需要大模型实时生成。因为精选、分类、翻译在信息入库时就已经做完了,日报的工作只是把处理好的条目分桶排序——每天 1 秒钟搞定。
这才是这个产品最值得学的地方。把能提前算好的全提前算好,把能用代码做的全用代码做,模型只在它真正擅长的那一步出现。这套思路我准备直接搬过来用在我自己的几个工具上。
四、 怎么用:三种接入方式
aihot 提供三种接入方式(目前都是测试版):
- Skill: 装进 Claude Code、Cursor、Codex CLI 等支持 SKILL.md 标准的 Agent(SKILL.md 可以理解成 Agent 的"使用说明书",告诉它什么时候调用这个工具、怎么调用)- RSS: 丢进 Feedly、Inoreader 这类 RSS 阅读器- REST API: 自己集成进工作流的开发者用我自己用的是 Skill。在 Claude Code 里发一句话就装好了:
帮我安装这个 skill:https://aihot.virxact.com/aihot-skill/不需要配 MCP server、不需要 API Key、匿名免费。装好之后每天早上一句中文自然语言就能拿到当天的 AI 日报:
"今天 AI 圈有什么新东西" —— 默认走精选 "看一下今天的 AI 日报" —— 走日报端点 "最近 OpenAI 有什么发布" —— 走关键词搜索
GitHub 仓库地址是 KKKKhazix/khazix-skills,里面除了 aihot,还有 khazix-writer(卡兹克的公众号写作 skill)和 hv-analysis(横纵分析法深度研究 skill)。
关于安全: 不要因为它是开源项目,或者因为仓库 star 很高,就跳过最基本的安全检查。Skill 本质上是给 Agent 的一份操作说明,它会告诉 Agent 什么时候访问接口、怎么组织请求、如何返回内容。安装第三方 Skill 之前,最好先打开 SKILL.md 看一眼,确认它访问了哪些外部 API、是否要求写入本地目录、是否涉及命令执行。
aihot 这个 skill 的好处是 SKILL.md 公开可审,接入方式也比较轻——不需要 API Key,也不需要 MCP server。对普通用户来说风险不高,但安全习惯还是要养成。读源码本身也有附加价值:卡兹克的"意图驱动的端点路由"设计是个值得抄的写法,读 SKILL.md 顺便就学了。
五、 一个小遗憾:评分系统没开源
到目前为止这篇文章基本都是正面评价,老实说一条局限性。
aihot 把信源、Skill、RSS 都开源了,但精选评分系统的具体公式没公开。卡兹克在复盘文章里讲了架构思路(5 维打分 + 代码计算权重和阈值),但具体的 5 个维度是什么、每个维度怎么算、阈值是多少,这些外部不可见。
你只能感知到"它筛得不错",没法自己复核它是不是漏掉了你关心的方向,也没法把这套方法迁移到你自己的领域(比如做财经资讯精选、做学术论文精选)。对纯使用者影响不大,但对想把这套思路用到自己产品上的人来说,是个明显的缺口。
能理解为什么不开源——这套打分系统是卡兹克 11 版迭代换来的核心 know-how,开源等于送给所有竞品。但作为读者还是有点遗憾。
这也意味着,aihot 更适合作为一个高质量的资讯入口,而不是一个可完全复现的方法论模板。它能给你启发,但不能让你直接复制出另一个垂直领域(财经、医疗、学术)的 aihot——你只能看到它最终做对了什么,看不到它具体怎么算。 写在最后 aihot 真正提醒我们的是一件事:AI 产品最难的地方,往往不是调用模型,而是把人的判断拆成系统。
信源怎么分层、噪声怎么过滤、重复事件怎么折叠——这些问题想清楚了,模型只是其中一步。这套思路对企业 AI 落地、对自己做工具的人,都同样适用。
我会把 aihot 当成一个工具每天用,也会把它当成一个 AI 产品案例讲。如果你也在做 AI 产品,卡兹克这次的复盘文章值得认真读——它讲的不只是一个资讯工具怎么做,而是一个更普遍的问题:在 AI 产品里,哪些事该交给模型,哪些事必须回到工程、规则和产品判断。
参考资料
AI HOT 网站:https://aihot.virxact.com/ Agent 接入页:https://aihot.virxact.com/agent GitHub 仓库:https://github.com/KKKKhazix/khazix-skills aihot SKILL.md:https://aihot.virxact.com/aihot-skill/SKILL.md 数字生命卡兹克 公众号:「数字生命卡兹克」
