夜雨聆风
夜雨聆风
很多人第一次用 AI 写长文,都会经历一个相似的过程:刚开始很惊艳,标题像样,开头顺滑,分段也整齐;可读到中后段,就会发现它在绕圈。观点看似丰富,其实没有推进;资料看似很多,其实只是堆叠;整篇文章像一个会说话的人,但不像一个真的研究过问题的人。这就很像我读卢克文的文章,典型的羊肉串式的风格。
我们常说这是“AI 味”,什么是AI味?或许AI 味不只是措辞问题。它更深层的来源,是文章缺少真正的研究过程。最近看过的一篇Stanford OVAL 的论文 《Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models》提出的 “STORM”,正好切中了这一点:长文写作的关键,不是让模型更会写,而是让模型在写之前先学会研究。
STORM 的全称是 “Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking”。翻译得直白一点,就是通过检索、多视角提问和资料综合,先生成一个高质量大纲,再写长文。这件事听起来并不复杂,但它击中了 AI 写作里最容易被忽略的问题。
一、好文章不是从写作开始的
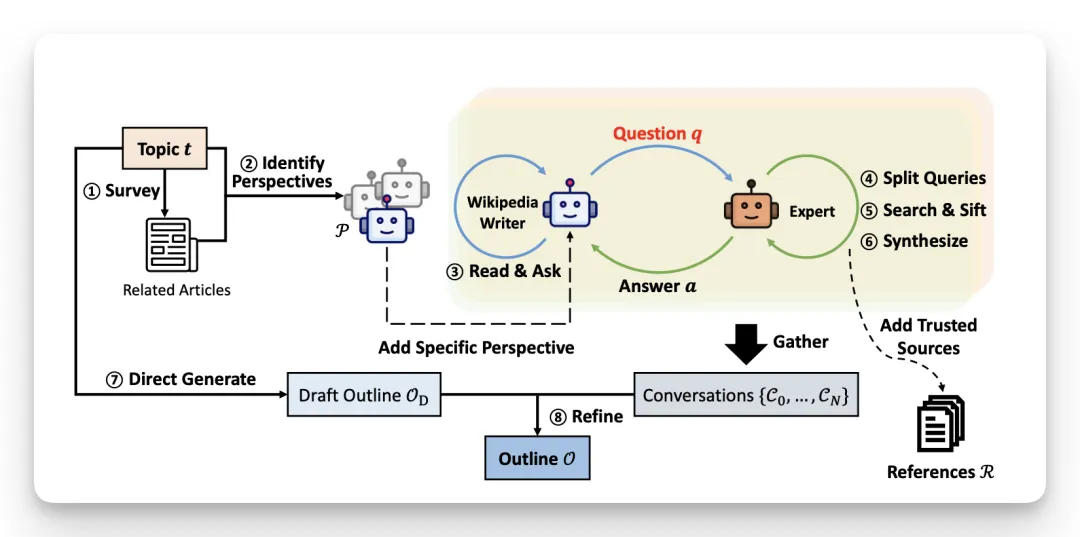
我们人写一篇有深度的长文章,通常不是打开文档就开始输出。真正耗时间的部分,往往发生在动笔之前:构思选题搭框架,查资料收集信息、判断信息源是否可靠等等,这就是写作经常踢到的“预写作”阶段。 STORM 的理论起点就在这里。它把长文生成拆成两个阶段:第一段是预写作,负责研究主题、收集资料、形成大纲;第二段才是写作,根据大纲和资料生成文章。这看起来只是流程拆分,但意义很大,因为大多数 RAG 写作系统的问题,恰恰在于它把信息的“检索”误当成了“研究”。
搜索一些网页,不等于理解一个主题;把资料塞进上下文,不等于形成文章结构;让模型带引用写作,也不等于它真的知道每条信息该放在哪里。STORM 想解决的不是“怎么写得更流畅”,而是“怎么在写之前知道该写什么”。
二、为什么“视角”比“提示词”更重要
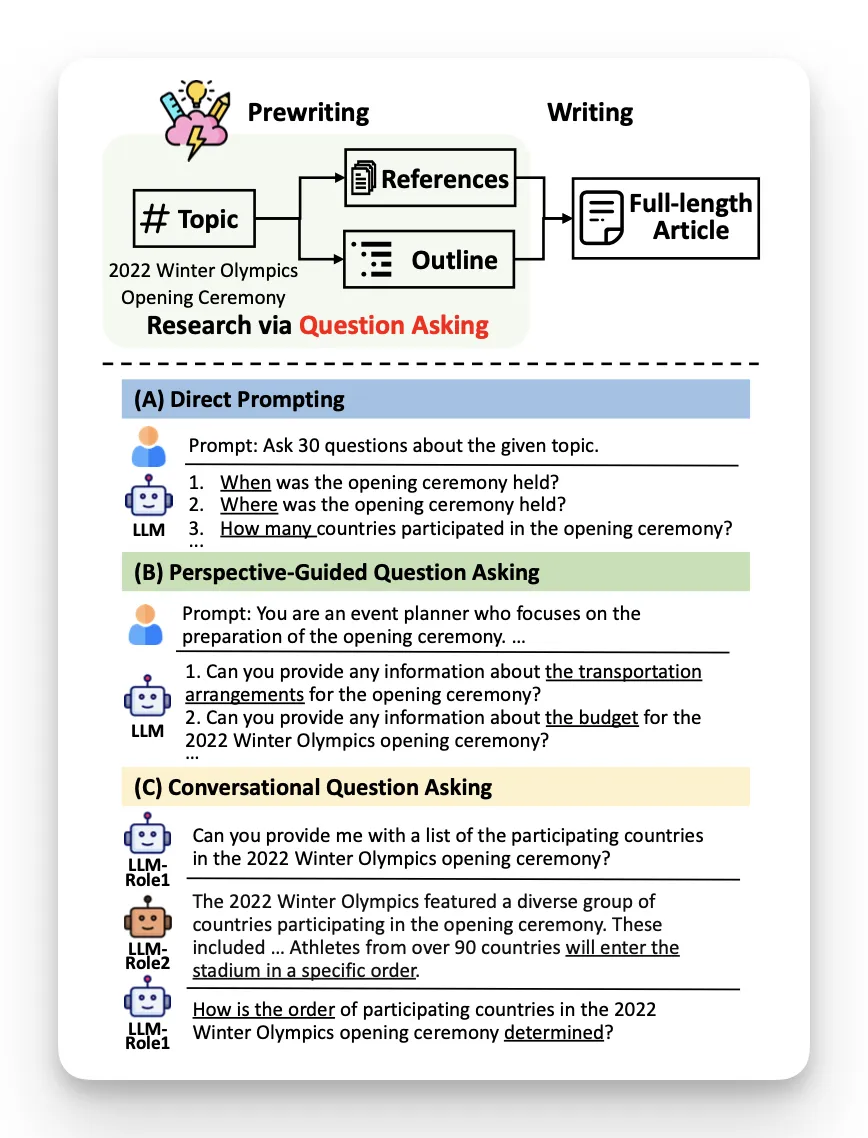
STORM 这套框架最有关键的地方,是它不让模型直接列问题。因为直接列问题,很容易变成常识问答。你给一个主题,模型通常会问:是什么、什么时候发生、在哪里发生、有什么影响。这些问题不是没用,但很浅。
我们人类研究一个主题时,真正让问题变深的,往往是视角。文章里面例到同样研究一个音乐节,观众会关心体验,主办方会关心预算和组织,城市管理者会关心交通和安全,组织者会关心赞助和收入。视角不同,问题就不同;问题不同,搜到的资料也不同;资料不同,最后文章的结构和深度也会不同。
这就是 STORM 的第一层理论逻辑:“多视角带来多样化问题,多样化问题带来更完整的信息覆盖。” 它会先查找与目标主题相似的维基文章,分析这些文章的目录,再让模型根据这些目录总结出若干个适合研究该主题的视角。然后,每个视角都变成一个“虚拟作者”,分别去提问。
三、真正的研究,是被答案不断改变问题
STORM 框架的第二个关键设计,是多轮对话。它不是让模型一次性问完 30 个问题,而是让“作者”和“专家”对话:作者提出一个问题,专家基于可信互联网资料回答;作者读完答案后,再继续追问。
这件事听起来简单,但它很接近真实人类的研究状态。很多好问题,一开始是问不出来的。你必须先读到一些真实信息,才会发现里面的矛盾、不足和线索。一个答案不是终点,而是下一个问题的入口。
这也是为什么普通 AI 长文经常显得“平”。它有知识,但缺少被资料推动的过程;它会总结,但没有经历过追问;它能把信息排整齐展现出来,却不一定知道哪里值得深挖。STORM 的多轮对话,实际上是在模拟一种研究中的认知循环:提出问题,检索资料,综合答案,发现新线索,然后继续追问。这套循环,比单次检索更接近人的研究方式。
四、大纲不是形式,而是理解的骨架
这个框架里还有一个很关键的环节:大纲。
论文专门评估了大纲质量,而且发现了一件事:如果去掉大纲阶段,直接把研究问题和对话资料丢给模型,让它写完整文章,效果会明显变差。这其实很符合我们自己的写作经验。人在面对大量资料时,最容易出问题的地方,往往不是“不知道写什么”,而是“什么都想写”。模型也是一样。信息越多,就越需要结构来约束。没有结构,材料之间就会互相抢位置,最后文章很容易变成资料拼贴,看起来什么都有,但读起来很散,像一串内容羊肉串。
STORM 的处理方式是:先让模型根据已有知识生成一个粗略大纲,再把多视角问答得到的信息交给模型,最后让模型根据这些新信息修订大纲。这个设计很有意思。模型自己的知识,负责先搭一个大体框架;外部检索来的资料,负责补充这个主题里的具体内容。前者提供稳定性,后者提供新信息。也就是说,STORM 既不是完全相信模型自己瞎写,也不是把搜索结果简单堆进去,而是让模型知识和外部资料互相校正。
五、STORM 真正超过 RAG 的地方
普通 RAG 的思路比较直接:先把相关资料搜出来,再让模型基于资料写答案。STORM 的思路要多一步:它不是一上来就搜,而是先判断这个主题应该从哪些角度去问,再围绕这些问题检索资料,继续追问,最后再整理大纲、进入写作。差别就在这里。RAG 主要解决的是“模型不知道外部事实”的问题;STORM 想解决的是另一个问题:模型不知道该怎么研究一个主题。前者是补知识,后者是搭研究过程。
如果只是查一个具体事实,RAG 已经很好用。但如果要写一篇接近维基百科长度和信息密度的文章,光有资料远远不够。你还得知道哪些内容必须写,哪些内容可以略过,材料之间怎么组织,哪些关系不能随便建立,哪些来源还需要再核查。论文里的实验也说明了这一点。 研究者请了 10 位有经验的维基百科编辑,对比 STORM 和当时最强的基线方法 oRAG 生成的文章。结果显示,STORM 写出来的文章在结构和覆盖面上都更好。其中,被认为“组织良好”的文章比例比 oRAG 高 25%,被认为“覆盖充分”的比例高 10%。
不过,论文也说得很清楚:即使用了 STORM,生成文章的质量仍然比不上经过充分修改的人类文章。STORM 会引用资料来源,但引用了来源,不代表文章就完全可靠。作者发现了两个比较典型的问题。
第一个问题是语气和立场会被带进去。网上的资料并不总是中立的,很多内容本身就带有宣传口吻、情绪词,或者某种隐含立场。模型在综合资料时,可能会把这种语气也一起带进文章里。于是文章虽然看起来有来源,但读起来不像百科,更像一篇宣传稿。第二个问题更麻烦:模型可能会过度关联。也就是说,它没有编造事实,两个事实本身可能都是真的,但它会把它们强行连在一起,写出一种原资料并没有明确支持的关系。
这类问题比单纯的“事实有没有错”更难查。因为很多误导不是来自假事实,而是来自错误连接。一个事实是真的,另一个事实也是真的,但它们放在一起,不一定能推出文章暗示的结论。所以,STORM 的意义不只是提出了一种更好的写作流程,也暴露了 AI 写作接下来真正难解决的问题:未来不能只做事实核查,还要做关系核查、语气核查和立场核查。
六、SKILL实现STORM方式写作
这篇文章写于 2024 年。那时,人类与 AI 的互动基本还停留在 Prompt 时代:大家总希望写出一句足够完美的提示词,让模型一次性生成理想结果。但复杂任务很难靠一句话解决,长文写作尤其如此。它并不是“输入一个主题,输出一篇文章”这么简单,而是包含选题、研究、提问、检索、筛选、结构化、写作、核查和修订等多个环节。STORM 的价值正在于,它把这些原本隐藏在写作过程中的步骤显性化了。
而到了今天,Skill 已经可以在很大程度上承接这类复杂流程。它不再依赖单一 Prompt,而是让 AI 按照一套相对完整的工作路径去执行任务:从前期研究、提出问题,到资料整理、结构搭建,再到写作、核查和修改。一个好的写作 Skill,不应该只是把几句提示词打包起来,而应该是一套稳定的认知流程设计:先问哪些问题,如何查找资料,怎样判断视角是否充分,什么时候生成大纲,什么时候进入写作,什么时候必须回到事实核查。
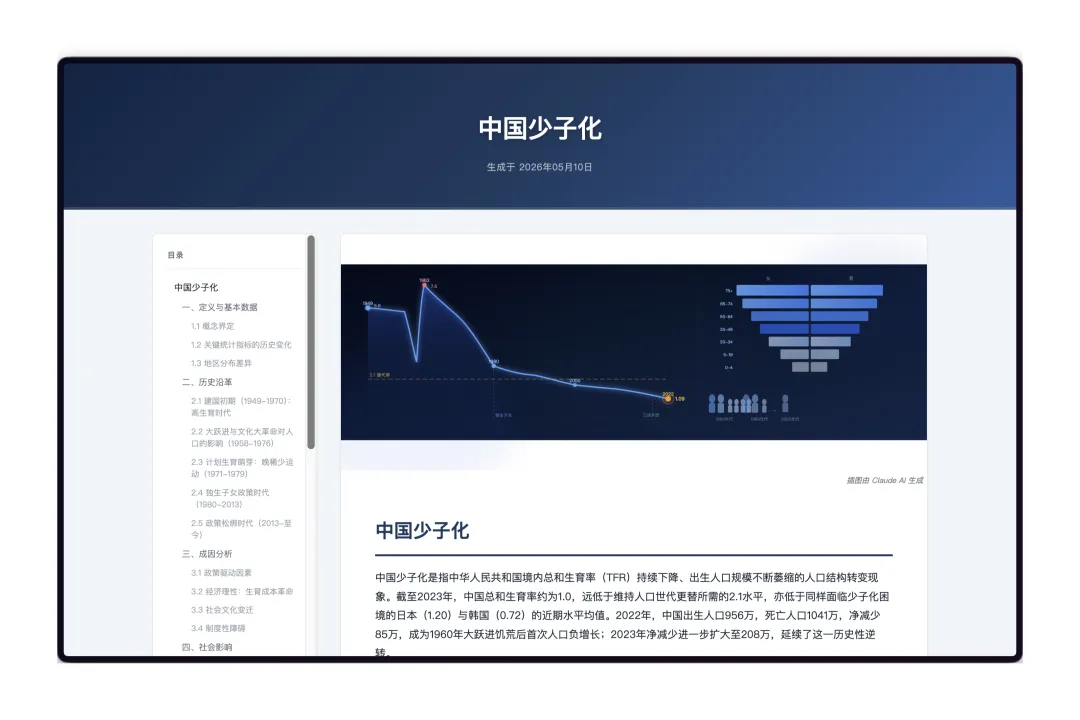
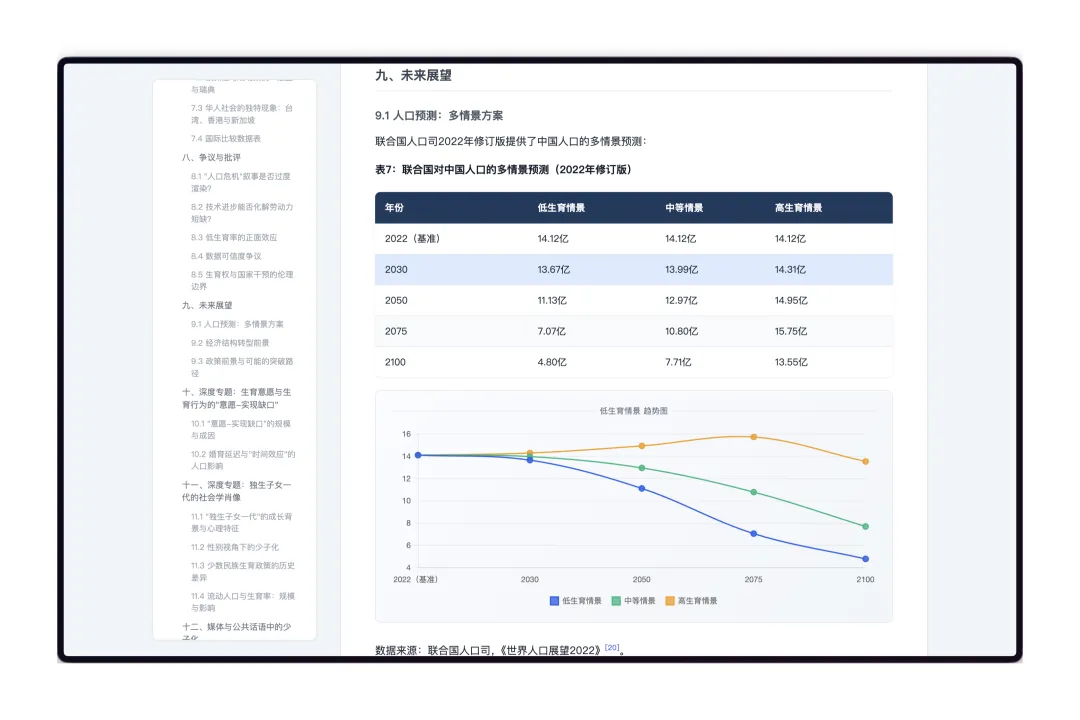
基于这篇论文我写了一个Skill,可以明显的看到调用这个SKILL写的文章质量很高。让他对中国少子化现象进行研究,给出了一篇15000字的维基百科式的文章。