 夜雨聆风
夜雨聆风05. nanobot 源码解读:LLM API 调用
文档内容基于 HKUDS/nanobot: "🐈 nanobot: The Ultra-Lightweight Personal AI Agent" 的 main 分支 3c20d16 提交进行说明。
目录
• 05. nanobot 源码解读:LLM API 调用 • 目录 • LLM API 规范 • OpenAI Chat API(chat/completions) • OpenAI Responses API • Anthropic Messages API • LLM API 调用抽象 • LLMProvider 抽象类 • AnthropicProvider 实现 • 参数构造细节 • OpenAICompatProvider 实现 • OpenAI Chat API 参数构造 • LLMProvider 实例创建
nanobot 作为超轻量级个人 AI Agent 框架,其 Agent Loop 的核心能力依赖于 LLM API 调用。自出现 litellm 供应链投毒攻击事件后,许多框架都倾向于自行实现 LLM API 调用逻辑,而不是依赖第三方库以降低安全风险。nanobot 也不例外,它自行封装了一套 LLM API 调用机制。
LLM API 规范
一般讨论意义上的 LLM API 规范主要有以下几种:
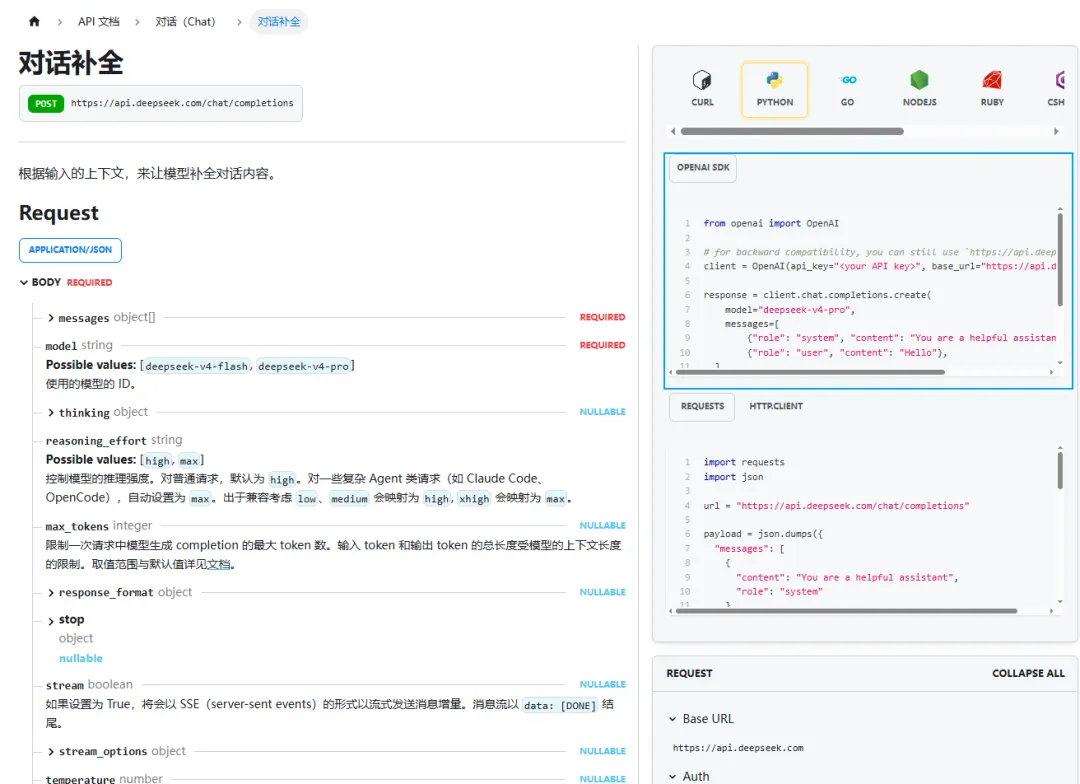
OpenAI Chat API(chat/completions)
当前业界的事实标准,大多数模型提供商都会兼容这种格式。以 DeepSeek 为例:
OpenAI Responses API
对比 OpenAI Chat API 主要有以下区别:
1. 带状态:入参如果提供 previous_response_id,后续对话则只需要提供增量消息,而不是像OpenAI Chat API一样每次调用接口都要拼接历史消息2. 内置工具:如果大模型认为需要调用工具且工具是 OpenAI Responses API内置的,则在大模型服务端完成工具调用
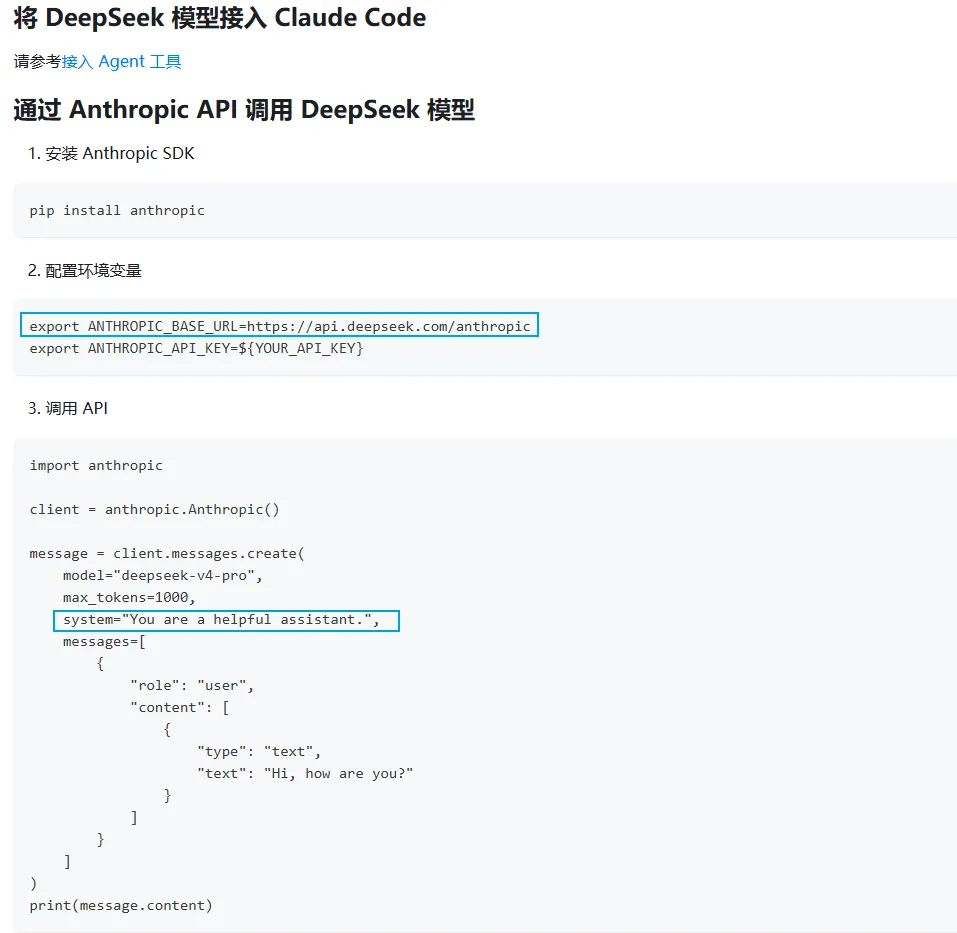
Anthropic Messages API
URL、鉴权、请求结构、响应结构都与 OpenAI Chat API 存在差异。模型厂商也可能会兼容这种格式,如 DeepSeek:
关键要点:不同的 LLM API 规范在参数格式、鉴权方式、响应结构等方面存在显著差异,nanobot 需要提供统一的抽象来处理这些差异。
LLM API 调用抽象
nanobot 使用了 Provider 来抽象 LLM API 调用逻辑(相关源码位于 nanobot/providers/ 包)。
Provider,即 LLM 服务提供商。
nanobot 在配置文件 config.json 有两个设置:
• 配置 provider• 为 agent.defaults指定model+provider
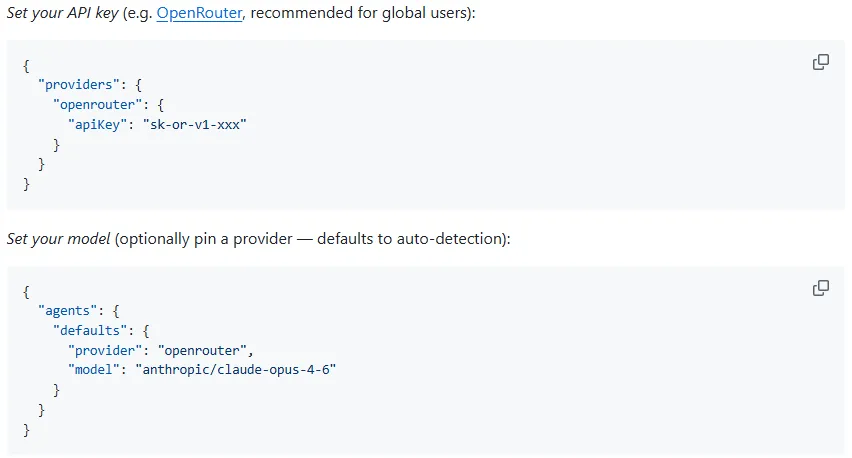
这里的 provider 配置对应了 LLM API 调用逻辑。
nanobot 会根据
provider配置匹配到内部的ProviderSpec。
nanobot/providers/registry.py 文件中预定义了许多 ProviderSpec。这些 ProviderSpec 在 nanobot 启动时被加载到内存,读取 config.json 后再进行 provider 匹配操作。
下面是预定义的 zhipu(智谱)provider:
# Zhipu (智谱): OpenAI-compatible at open.bigmodel.cn ProviderSpec( name="zhipu", keywords=("zhipu", "glm", "zai"), env_key="ZAI_API_KEY", display_name="Zhipu AI", backend="openai_compat", env_extras=(("ZHIPUAI_API_KEY", "{api_key}"),), default_api_base="https://open.bigmodel.cn/api/paas/v4", ),关键字段说明:
• env_key:env_key对应的环境变量值会被设置成 api_key• backend:backend对应 nanobot 内部的LLMProvider实现类,此处的openai_compat是兼容 * OpenAI Chat API* 规范的实现• env_extras:env_extras是一个 key-value 列表,表示 key 对应的环境变量要被设置成 value (占位符会替换为具体值)• default_api_base:没有在config.json对应provider显示指定api_base时,就会使用这个默认值
匹配到 ProviderSpec 后,会根据 backend 字段决定使用 LLMProvider 抽象类的具体实现类,然后用其它字段辅助创建 LLMProvider 实例。
LLMProvider 抽象类
nanobot/providers/base.py 中定义了抽象类 LLMProvider承载LLM API 调用逻辑。该类定义了两个抽象方法:
• chat:LLM API调用流程,包括参数构造、接口调用、结果解析等步骤,返回类型是 nanobot 设计的LLMResponse• get_default_model:获取默认模型名称
class LLMProvider(ABC): # 其它代码略 @abstractmethod async def chat( self, messages: list[dict[str, Any]], tools: list[dict[str, Any]] | None = None, model: str | None = None, max_tokens: int = 4096, temperature: float = 0.7, reasoning_effort: str | None = None, tool_choice: str | dict[str, Any] | None = None,) -> LLMResponse: """ Send a chat completion request. Args: messages: List of message dicts with 'role' and 'content'. tools: Optional list of tool definitions. model: Model identifier (provider-specific). max_tokens: Maximum tokens in response. temperature: Sampling temperature. tool_choice: Tool selection strategy ("auto", "required", or specific tool dict). Returns: LLMResponse with content and/or tool calls. """ pass @abstractmethod def get_default_model(self) -> str: """Get the default model for this provider.""" passLLMProvider 实现类说明:
不同的 LLM API 调用流程,就需要实现一个专门的 LLMProvider 子类。nanobot 提供了五种实现:
AnthropicProvider | anthropic_provider.py | ||
AzureOpenAIProvider | azure_openai_provider.py | ||
OpenAICodexProvider | openai_codex_provider.py | ||
OpenAICompatProvider | openai_compat_provider.py | ||
GitHubCopilotProvider | github_copilot_provider.py |
下面以 AnthropicProvider 和 OpenAICompatProvider 为例,详细说明不同 API 规范的实现细节。
AnthropicProvider 实现
直接查看抽象方法 chat 的实现:
async def chat( self, messages: list[dict[str, Any]], tools: list[dict[str, Any]] | None = None, model: str | None = None, max_tokens: int = 4096, temperature: float = 0.7, reasoning_effort: str | None = None, tool_choice: str | dict[str, Any] | None = None,) -> LLMResponse: # 构造符合 Anthropic Messages API 规范的参数 kwargs = self._build_kwargs( messages, tools, model, max_tokens, temperature, reasoning_effort, tool_choice, ) try: # self._client 是 AsyncAnthropic 实例,直接通过 Anthropic 官方库调用接口 response = await self._client.messages.create(**kwargs) return self._parse_response(response) except Exception as e: return self._handle_error(e)实现要点:
1. 使用 Anthropic 官方 Python 库( AsyncAnthropic)进行 API 调用2. 通过 _build_kwargs方法构造符合Anthropic Messages API规范的参数3. 异常处理通过 _handle_error方法统一处理
参数构造细节
def _build_kwargs( self, messages: list[dict[str, Any]], tools: list[dict[str, Any]] | None, model: str | None, max_tokens: int, temperature: float, reasoning_effort: str | None, tool_choice: str | dict[str, Any] | None, supports_caching: bool = True,) -> dict[str, Any]: model_name = self._strip_prefix(model or self.default_model) # Anthropic Messages API 的 system prompt 是独立于 messages 字段 system, anthropic_msgs = self._convert_messages(self._sanitize_empty_content(messages)) # tools 参数需要调整成符合规范的 json 格式 anthropic_tools = self._convert_tools(tools) if supports_caching: # prompt caching 功能:给 messages 和 tools 参数加上 cache_control 字段 system, anthropic_msgs, anthropic_tools = self._apply_cache_control( system, anthropic_msgs, anthropic_tools, ) max_tokens = max(1, max_tokens) thinking_enabled = bool(reasoning_effort) and reasoning_effort.lower() != "none" # claude-opus-4-7 完全废弃了 `temperature` 参数,若传该参数会报错 omit_temperature = "opus-4-7" in model_name kwargs: dict[str, Any] = { "model": model_name, "messages": anthropic_msgs, "max_tokens": max_tokens, } if system: kwargs["system"] = system if reasoning_effort == "adaptive": # Adaptive thinking:模型自主决定何时以及如何思考 # 支持 claude-sonnet-4-6 和 claude-opus-4-6 # 同时自动启用工具调用之间的交错思考 kwargs["thinking"] = {"type": "adaptive"} if not omit_temperature: kwargs["temperature"] = 1.0 elif thinking_enabled: budget_map = {"low": 1024, "medium": 4096, "high": max(8192, max_tokens)} budget = budget_map.get(reasoning_effort.lower(), 4096) kwargs["thinking"] = {"type": "enabled", "budget_tokens": budget} kwargs["max_tokens"] = max(max_tokens, budget + 4096) if not omit_temperature: kwargs["temperature"] = 1.0 elif not omit_temperature: kwargs["temperature"] = temperature if anthropic_tools: kwargs["tools"] = anthropic_tools tc = self._convert_tool_choice(tool_choice, thinking_enabled) if tc: kwargs["tool_choice"] = tc if self.extra_headers: kwargs["extra_headers"] = self.extra_headers return kwargs参数构造关键点:
1. System Prompt 分离: Anthropic Messages API的system prompt是独立于 messages 字段的,需要通过_convert_messages提取2. Prompt Caching:支持 prompt caching 功能,给 messages 和 tools 参数加上 cache_control字段3. 思考模式支持: • reasoning_effort == "adaptive":Adaptive thinking,模型自主决定思考程度• reasoning_effort为low/medium/high:启用 thinking 并设置 budget_tokens• reasoning_effort为None或"none":不启用思考4. 温度参数兼容:claude-opus-4-7 废弃了 temperature参数,需要特殊处理5. Tool 转换:通过 _convert_tools和_convert_tool_choice转换工具相关参数
OpenAICompatProvider 实现
OpenAICompatProvider 是一个更复杂的实现,它同时支持 OpenAI Chat API 和 OpenAI Responses API,还要针对各模型服务提供商的 API 进行额外处理。
直接查看 chat 方法实现:
async def chat( self, messages: list[dict[str, Any]], tools: list[dict[str, Any]] | None = None, model: str | None = None, max_tokens: int = 4096, temperature: float = 0.7, reasoning_effort: str | None = None, tool_choice: str | dict[str, Any] | None = None,) -> LLMResponse: try: # 判断是否需要使用 OpenAI Responses API if self._should_use_responses_api(model, reasoning_effort): try: # 构造符合 OpenAI Responses API 规范的参数 body = self._build_responses_body( messages, tools, model, max_tokens, temperature, reasoning_effort, tool_choice, ) # self._client 是 AsyncOpenAI 实例,使用 OpenAI 官方库调用 Responses API result = parse_response_output(await self._client.responses.create(**body)) self._record_responses_success(model, reasoning_effort) return result except Exception as responses_error: if self._spec and self._spec.name == "github_copilot": # Copilot 网关仅通过 /responses 暴露 GPT-5/o-series # 降级到 /chat/completions 无法成功,会隐藏真实错误 raise if not self._should_fallback_from_responses_error(responses_error): raise self._record_responses_failure(model, reasoning_effort) # 构造符合 OpenAI Chat API 规范的参数 kwargs = self._build_kwargs( messages, tools, model, max_tokens, temperature, reasoning_effort, tool_choice, ) # self._client 是 AsyncOpenAI 实例,使用 OpenAI 官方库调用 Chat API return self._parse(await self._client.chat.completions.create(**kwargs)) except Exception as e: return self._handle_error(e, spec=self._spec, api_base=self.api_base)实现要点:
1. API 自动选择:通过 _should_use_responses_api判断是否使用Responses API,满足特定条件时自动切换2. 降级策略: Responses API调用失败时,根据错误类型判断是否降级到Chat API(GitHub Copilot 例外)3. 成功/失败记录:通过 _record_responses_success和_record_responses_failure记录 API 调用结果,用于后续优化判断4. 统一错误处理:所有异常通过 _handle_error统一处理
OpenAI Chat API 参数构造
def _build_kwargs( self, messages: list[dict[str, Any]], tools: list[dict[str, Any]] | None, model: str | None, max_tokens: int, temperature: float, reasoning_effort: str | None, tool_choice: str | dict[str, Any] | None,) -> dict[str, Any]: model_name = model or self.default_model spec = self._spec if spec and spec.supports_prompt_caching: model_name = model or self.default_model if any(model_name.lower().startswith(k) for k in ("anthropic/", "claude")): # Anthropic 模型需要通过此方法启用缓存功能 # 这里应该是通过 OpenRouter 之类的网关调用了 Anthropic 的模型 messages, tools = self._apply_cache_control(messages, tools) if spec and spec.strip_model_prefix: model_name = model_name.split("/")[-1] # DeepSeek 模型开启思考模式后,要求 tool_calls 消息必须携带 reasoning_content 字段 # 如果没有 reasoning_content 字段,模型调用会返回错误 # 此处针对这种情况,丢弃了部分消息 messages = self._drop_deepseek_incomplete_reasoning_history( messages, reasoning_effort, ) kwargs: dict[str, Any] = { "model": model_name, "messages": self._sanitize_messages(self._sanitize_empty_content(messages)), } # GPT-5 和推理模型(o1/o3/o4)在启用 reasoning_effort 时会拒绝 temperature 参数 # 仅在安全时包含该参数 if self._supports_temperature(model_name, reasoning_effort): kwargs["temperature"] = temperature if spec and getattr(spec, "supports_max_completion_tokens", False): kwargs["max_completion_tokens"] = max(1, max_tokens) else: kwargs["max_tokens"] = max(1, max_tokens) if spec: model_lower = model_name.lower() for pattern, overrides in spec.model_overrides: if pattern in model_lower: kwargs.update(overrides) break # 将 reasoning_effort 标准化为语义形式(OpenAI 词汇) # 用于内部决策,以及实际发送的线形式 # "minimum" 被接受为 DashScope 原生的 "minimal" 别名 semantic_effort: str | None = None if isinstance(reasoning_effort, str): semantic_effort = reasoning_effort.lower() if semantic_effort == "minimum": semantic_effort = "minimal" wire_effort = reasoning_effort if spec and spec.name == "dashscope" and semantic_effort == "minimal": # DashScope 接受 none/minimum/low/medium/high/xhigh;"minimal" 会返回 400 wire_effort = "minimum" if wire_effort and semantic_effort != "none": kwargs["reasoning_effort"] = wire_effort # Provider 特定的思考参数 # 仅在明确配置 reasoning_effort 时发送,以保留 provider 默认值 # 映射由 ProviderSpec.thinking_style 驱动,因此添加新的 provider 永远不需要修改此函数 if spec and spec.thinking_style and reasoning_effort is not None: thinking_enabled = semantic_effort not in ("none", "minimal") extra = _THINKING_STYLE_MAP.get(spec.thinking_style, lambda _: None)(thinking_enabled) if extra: kwargs.setdefault("extra_body", {}).update(extra) # Kimi 思考模型的模型级思考注入 # 在进行模型名称判断之前去除任何 provider 前缀(如 "moonshotai/") # 这样 OpenRouter 风格的完整名称(如 "moonshotai/kimi-k2.5")与裸模型名称(如 "kimi-k2.5")能够被一致处理 if reasoning_effort is not None and _is_kimi_thinking_model(model_name): thinking_enabled = semantic_effort not in ("none", "minimal") kwargs.setdefault("extra_body", {}).update( {"thinking": {"type": "enabled" if thinking_enabled else "disabled"}} ) if tools: kwargs["tools"] = tools kwargs["tool_choice"] = tool_choice or "auto" # 在旧的 assistant 消息上回填 reasoning_content # DeepSeek V4(以及其他可能的模型)会拒绝包含没有 reasoning_content 的 assistant 消息的思考模式请求 # 即使在没有工具调用的轮次上也是如此。这通常发生在会话中途切换思考模式的场景: # 会话以普通模式启动(或使用非思考模型),用户后续切换到思考模式时,历史 assistant 消息缺少 reasoning_content 字段 # 注入空字符串满足 API 要求而不改变语义(模型将其视为"该轮没有思考") thinking_active = ( (spec and spec.thinking_style and reasoning_effort is not None and semantic_effort not in ("none", "minimal")) or (reasoning_effort is not None and _is_kimi_thinking_model(model_name) and semantic_effort not in ("none", "minimal")) ) if thinking_active: for msg in kwargs["messages"]: if msg.get("role") == "assistant" and "reasoning_content" not in msg: msg["reasoning_content"] = "" # 最后合并用户配置的 extra_body,以便它可以覆盖或扩展 provider 特定的默认值 # (如 chat_template_kwargs、guided_json、repetition_penalty) # 使用递归合并,以便嵌套字典(如 {"chat_template_kwargs": {"enable_thinking": false}}) # 不会破坏已经由 thinking-style 逻辑设置的兄弟键 if self._extra_body: existing = kwargs.get("extra_body", {}) kwargs["extra_body"] = _deep_merge(existing, self._extra_body) return kwargs参数构造关键点:
1. 模型名称处理: • strip_model_prefix:去除模型名称中的 provider 前缀(如从 "moonshotai/kimi-k2.5" 提取 "kimi-k2.5")• model_overrides:模型级别的参数覆盖2. Prompt Caching:通过网关调用 Anthropic 模型时,启用 prompt caching 功能 3. DeepSeek 兼容性: • 丢弃不完整历史:开启思考模式后,DeepSeek 模型要求所有 tool_calls 消息必须携带 reasoning_content字段。对于不满足此条件的历史消息,系统会将其丢弃以避免 API 调用失败• 回填 reasoning_content:为历史 assistant 消息注入空的 reasoning_content字段。这主要处理"会话中途切换思考模式"的场景——当会话以普通模式启动,用户后续切换到思考模式时,历史 assistant 消息缺少reasoning_content字段会导致 API 拒绝。注入空字符串可以满足 API 要求而不改变消息语义4. 思考模式处理: • 统一 reasoning_effort参数语义(如将 DashScope 的 "minimum" 转换为 "minimal")• Provider 特定的思考参数通过 thinking_style配置映射• Kimi 模型的思考功能通过模型名称判断并启用 5. 温度参数兼容:GPT-5 和推理模型(o1/o3/o4)在启用思考模式时会拒绝 temperature 参数 6. 额外参数合并:通过 extra_body支持用户自定义额外参数,使用深度合并避免覆盖已有参数
LLMProvider 实例创建
nanobot/providers/factory.py 提供了 make_provider 方法,用于根据配置创建对应的 LLMProvider 实例。
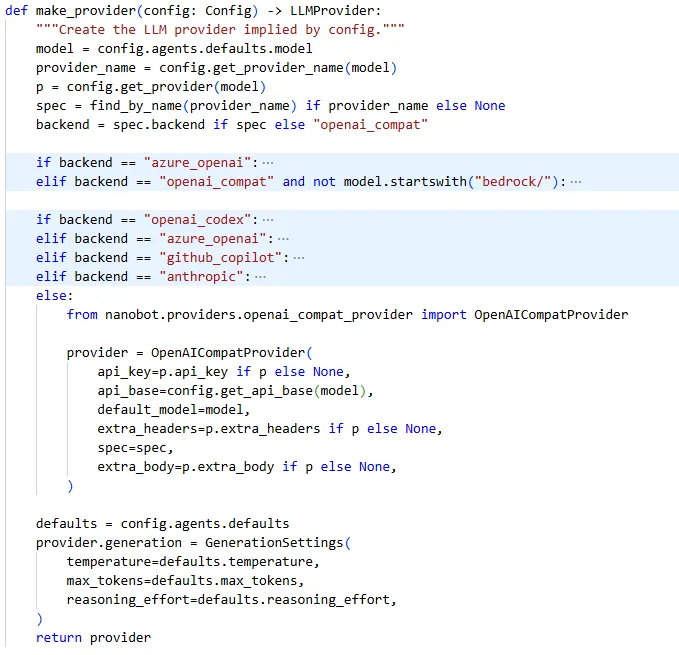
创建流程:
1. 根据 provider配置查找对应的ProviderSpec2. 根据 backend字段选择具体的实现类(如openai_compat→OpenAICompatProvider)3. 传入必要的参数(如 api_key、api_base等)创建实例
核心优势:
• 易切换:通过配置文件即可切换不同的 LLMProvider• 易扩展:新增 LLMProvider 只需实现 LLMProvider接口并在 nanobot/providers/registry.py 中注册
