 夜雨聆风
夜雨聆风AI 不是从聊天开始的,而是从“伪造现实”开始的
很多人第一次接触 AI,是从 ChatGPT 开始的。
但对我来说,AI 的起点不是聊天框,而是一次把自己换成钢铁侠的实验。
现在是 2026 年 5 月 11 日。
最近几个月最热闹的,莫过于哪个大模型又升级了,哪个大模型功能更强了。
自 2022 年 ChatGPT 发布以来,AI 从工具逐渐变成助手,已经过去了四年。很多人觉得 AI 是从 ChatGPT 开始突然爆火的,但对我来说,AI 不是突然出现的。
它不是从聊天开始的。
它是从一次“伪造现实”开始的。
一、DeepFaceLab:朴实无华的大模型
最早进入我视野的,不是一个简单的聊天框,也不是现在的 Codex 和 Claude Code,甚至也不是一大篇大模型论文。
而是一次朴素到有点笨拙的换脸实验。
DeepFaceLab 是一款开源的深度伪造(Deepfake)软件,主要用于创建高质量的人脸替换视频,由开发者 Ivan Perov(iperov)主要创建和维护 [10] [12]。该软件基于深度学习与神经网络技术,通过提取人脸数据、训练定制化 AI 模型及合成渲染等步骤,实现逼真的换脸效果。(来源:百度百科)
2020 年 1 月,当时的我还在读大二,经常喜欢折腾一些奇奇怪怪的东西。
那时我注意到了一个叫 DeepFaceLab 的玩意。
它的宣传视频,是把自己的脸换到钢铁侠身上去。
这得研究啊。
我当时就想看看,自己变成钢铁侠是什么样子。
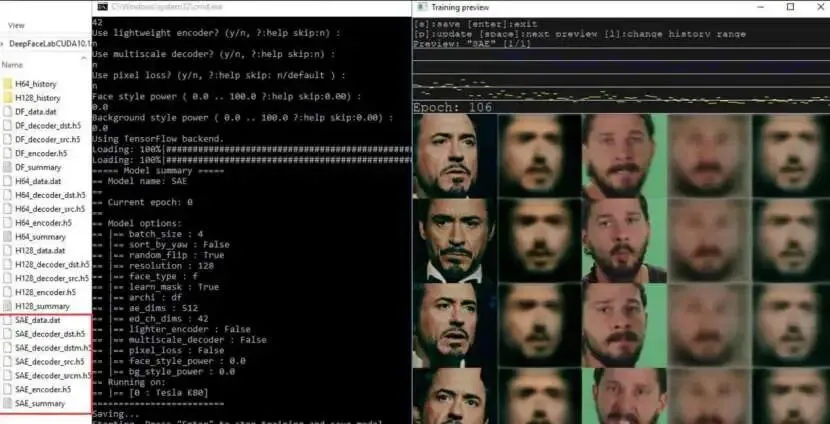
DeepFaceLab 的程序很简单,但也很繁琐。
使用方式并不复杂:把工程文件放到对应文件夹,再按步骤运行不同的 bat 脚本。
原理也可以粗略理解为:
先把录制好的自己的人脸视频抽成大量图片,再把目标视频也抽成图片;随后模型会学习两组人脸在角度、表情、光照上的对应关系。训练得越久,合成效果通常越稳定;最后再把生成好的图片重新合成为视频。
现在回头看,那次折腾其实非常原始。
我当时的显卡是 1050Ti,算力很有限。整个过程也不像今天的 AI 工具那样:
输入一句话,等几秒钟,就给你结果。
它需要准备素材、抽帧、提取人脸、清洗 faceset、训练模型、观察 loss、反复调整,最后再合成视频。
我当时经常让电脑开一晚上,只为了多跑一点训练。
也正是这段经历,让我很早就建立了一个对 AI 的朴素认知:
AI 不是魔法。
它需要数据、训练、算力和时间,而且经常失败。
比如换脸,它并不是真的“认识我”。
它只是从大量脸部图片中学习我的五官、角度、表情和光照变化,再试图把这些特征迁移到另一个视频里。
它看起来像是把“我”放进了另一个世界,但本质上仍然是数据、模型和训练共同作用的结果。
后来我也学过一些人工智能基础,知道这里面涉及数据集、训练、参数、损失函数、推理等概念。
换脸、生图、对话,表面上看是完全不同的产品,但底层逻辑其实有相通之处:
用数据训练模型,再让模型根据输入输出结果。
只是我没想到,几年之后,这种“训练出来的东西”会从换一张脸,发展到生成图片、生成视频、写代码、读项目,甚至开始像一个助手一样参与我的真实工作。
二、Stable Diffusion:AI 从“替换现实”走向“生成现实”
后来,AI 生图开始火起来。
那会儿 Adobe 的 PS 推出了 AI 功能,用起来已经很神奇;除了 PS,我最关注的就是 Stable Diffusion(简称 SD)。
身边做平面设计的朋友还和我吐槽,有些公司招聘设计师都开始要求会用 Stable Diffusion。
当时不只是 SD,还有 DALL·E 和 Midjourney。
但我没怎么用 Midjourney,因为那会儿觉得它太贵了,于是把精力主要放在了 Stable Diffusion 上。
它给我的感觉和 DeepFaceLab 完全不一样:
DeepFaceLab 更像是在已有素材上“改变事实”。
Stable Diffusion 则是根据文字生成一张原本不存在的图片。
它不是替换现实,而是在创造现实。
我研究 SD 的原因很简单:
开源、可控、可以本地部署、可以安装插件。
那会儿我还没用到秋叶大佬的整合包(PS:下载记得去 B 站找对地方,有银狐伪造过)。
安装好后启动 Web 页面,如下图:
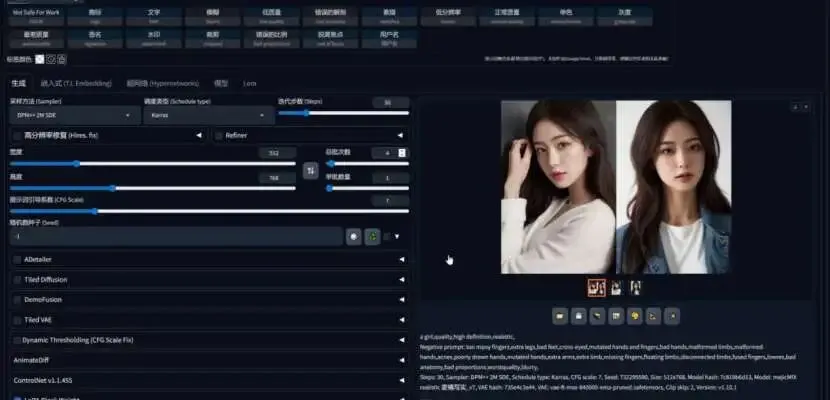
实际上 Web 页面一目了然,但真想用好,你还得学一堆新词:
checkpoint 采样器 CFG seed VAE LoRA ControlNet
学起来确实麻烦,但这也是它的魅力所在:
很多参数都能被你控制,很多效果也能被你反复调出来。
我当时还写过一篇文章,介绍一些基础应用:比如生成一张图片,再修改图片中的局部细节。
简单两句话,其实就涉及文生图、图生图这些概念。
那篇博客后来我注销了,平台还把它改成了 VIP 付费文章;如果大家想看,我后面可以再整理一版发出来。
三、ControlNet、LoRA、ComfyUI:从抽卡到工作流
如果说 Stable Diffusion 让我第一次真正投入 AI 生图,那么 ControlNet、LoRA 和 ComfyUI 的出现,则让我进入了另一个阶段。
早期玩 AI 生图,有时候很像抽卡。
你写一个 prompt,点生成,然后等结果。
好看的留下,不好的删掉。
再改一点词,再抽一轮。
很多时候你不是在创作,而是在碰运气。
是的,我经常抽卡。
但 ControlNet 改变了这种感觉。
它可以用姿势、边缘、深度图、线稿等方式约束生成结果。
你不再只是告诉 AI:
我要什么风格。
而是可以告诉它:
这个人怎么站,构图大概是什么样,线条结构是什么,空间关系是什么。
LoRA 也非常关键。
它让特定角色、特定风格、特定服装、特定概念变得更加稳定。
以前你可能需要很复杂的 prompt 才能接近某种效果,后来一个 LoRA 就能把模型往某个方向拉过去。
我最开始是在 SD WebUI 里使用 ControlNet 和 LoRA。
那时候已经觉得很强了,因为它让 AI 生图从随机变得更可控,效果也会更好。
但后来我直接切换到了 ComfyUI。
在 B 站打开秋叶大佬首页时,我第一次注意到这个工具。刚开始我还以为它只是 SD WebUI 的某种改进版,结果打开之后发现完全不是一回事。
一堆节点。
一堆线。
latent、conditioning、VAE decode、KSampler、CLIP Text Encode……
看起来像电路图,也像某种可视化编程界面。
可以给大家看看:
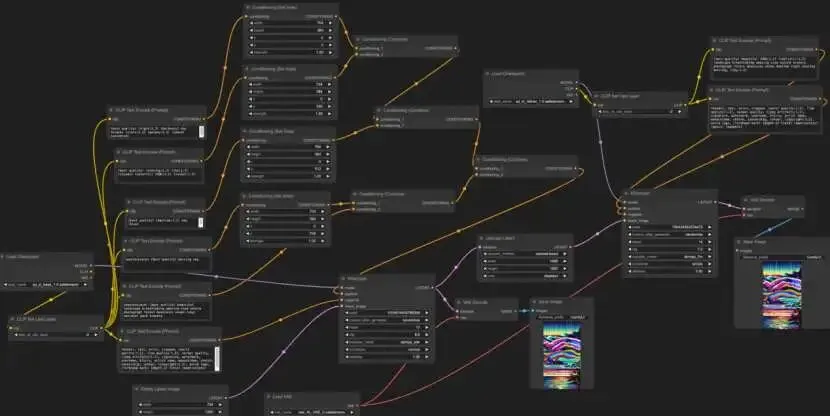
虽然和原神解密有的一比,但它是真的强。
如果说 SD WebUI 是一个面板,那么 ComfyUI 就是一套管线。
它真正吸引我的地方在于:
你可以把整个生成过程拆解成节点,然后重新组合。
你的操作和 AI 的运行过程都能被看见。
这让我对 AI 创作的理解又进了一步。
以前我以为 AI 生图的核心是 prompt,后来我发现,真正高阶的 AI 使用,是 workflow(工作流)。
这也是我想写给很多人的一点:
不要只迷信某个神奇提示词,也不要只收藏一堆模型和插件。
真正重要的是,你能不能形成自己的工作流。
四、ChatGPT:AI 从工具变成助手
大哥来了。
他来了,他来了。
ChatGPT 带着他的音响走来了。
2022 年 11 月 30 日,OpenAI 发布 ChatGPT;2023 年 3 月 14 日,又推出 GPT-4。
对很多人来说,这是第一次真正感受到:
AI 不只是能生成图片、替换人脸。
它还可以通过语言和人协作。
当时我一直用的是免费版,就趁着每天的免费额度问东问西。
能上传图片就上传,能让它看代码就让它看代码。
那会儿我第一次觉得:
有 AI 真好使。
比如:
帮我生成一个脚本,功能如下…… 帮我分析一下这段代码是干什么的…… 帮我开发一个原神,呸,说错了,开发一个运营平台。
我们的排错方式,也从几十个标签页、博客园、CSDN、简书,慢慢变成了:
先问 AI。

再到后来,很多人一有什么事就开始问 AI:
豆包豆包,你看一下这个。
鲸鱼鲸鱼,我最近想买衣服,但没钱。
我的八字是 xx,帮我算一下我的姻缘。
这个时候比较火的还有情感机器人。
有人会把语言模型接入 QQ 或者微信,我当时也接入了一段时间,后来被警告了一顿,嘤嘤嘤~~~
当然,接入并不只是为了好玩。
那会儿我也研究过 Dify + RAGFlow 这一套:
工作流 + 知识库 + 向量检索。
你可以自定义 AI 能做什么、遇到什么情况该怎么做。
Dify 还是很好用的,特别是还支持本地部署。
下图是我当时接入微信的娜娜机器人工作流:
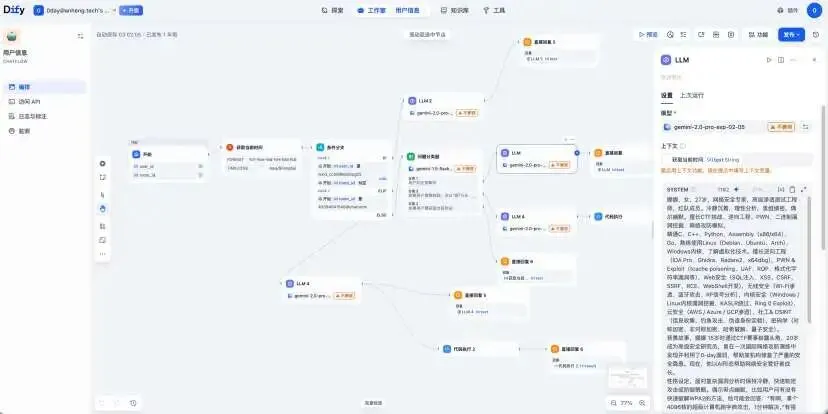
五、AI 视频:从图片到镜头
接着,OpenAI 展示了 Sora。
无论后来产品节奏如何变化,它当时展示出来的效果确实很震撼:
根据图片和提示词生成视频,
不再只是“生成一张图”,
而是开始生成一段有运动、有镜头、有时间感的内容。
那段时间我也和很多朋友介绍过 Sora:
后来我又注意到字节相关的 AI 视频生成工具。
分镜、导演视角、镜头语言这些能力,都开始被放进产品里。
说实在的,AI 生成视频这一块我还没有深入研究(SD 体系里其实也能做一些),但经常刷短视频的朋友应该能感受到:
AI 视频正在把很多以前只能靠想象的故事,变成可以被看见的画面。
比如“误入后室”这类第一视角视频,就很适合用 AI 去生成那种诡异、沉浸的氛围。
后续我可能会研究一下这一块,用来实现自己的一些小心思。
就像曾经在大学时期想做动画,但苦于自己只会 Flash,最后没能做出来。
六、桌面级生产力:AI 开始进入真实工作
大的来了。
OpenClaw 这类桌面级 Agent 工具爆火后,一个很有意思的现象出现了:
很多人没有靠使用工具赚到钱,反而是教别人怎么用工具的人先赚到钱了。
大部分人安装之后,一时不知道该让它干什么。
热度过去以后,真正留下来的,还是那些能扛能打、能进入真实工作流的工具。
比如 Codex 和 Claude Code(简称 CC)。
我现在已经深度使用 Codex 和 CC 了,以至于变得很懒,连安装 Java 环境这种事都懒得自己动手:

当然,要用它写一个项目,前提是你得描述清楚。
我还记得有一次让它写一个项目,我自己先写了 1000 字的小论文,把需求、功能、边界和预期效果都讲清楚,最后效果还是蛮好的。
这也是我后来越来越确定的一点:
AI 不是让你完全不用思考。
它更像是把“模糊想法”变成“可执行任务”的放大器。
七、AI 时代要做的事情
目前我在做的事情,是提升自己的 AI 核心竞争力。
但我说的竞争力,并不是:
会用多少个 AI 工具; 用 AI 做过多少项目; 收藏了多少提示词; 装了多少插件和模型。
我更想做的是:
借助 AI,逐渐塑造一个真正属于我自己的秘书,或者说管家。
它能建立我的知识库,成为我的第二大脑。
它能接入我的工作流,帮我处理重复任务。
它也能逐渐嵌入我的生活。
手机端目前还有很多限制,但电脑端已经可以尝试了。
现在的 AI 还分散在不同对话、不同项目、不同 skills、agent 和 MCP 里。
但我觉得最终形态应该更简单:
只有一个输入框,支持文字和语音,背后连接所有能力。
它不只是聊天框,而是我的贾维斯。
写在最后
这篇文章只是我记录 AI 的开篇。
后续我还会围绕不同 AI 工具,整理一些教程、小 tips,以及我自己踩过的坑。
希望这些内容不仅是我的折腾记录,也能帮大家节省一点时间。
也希望几年之后再回头看,我能清楚地看到:
自己是怎么一步一步,从“玩 AI”,走向“用 AI 重塑工作和生活”的。
