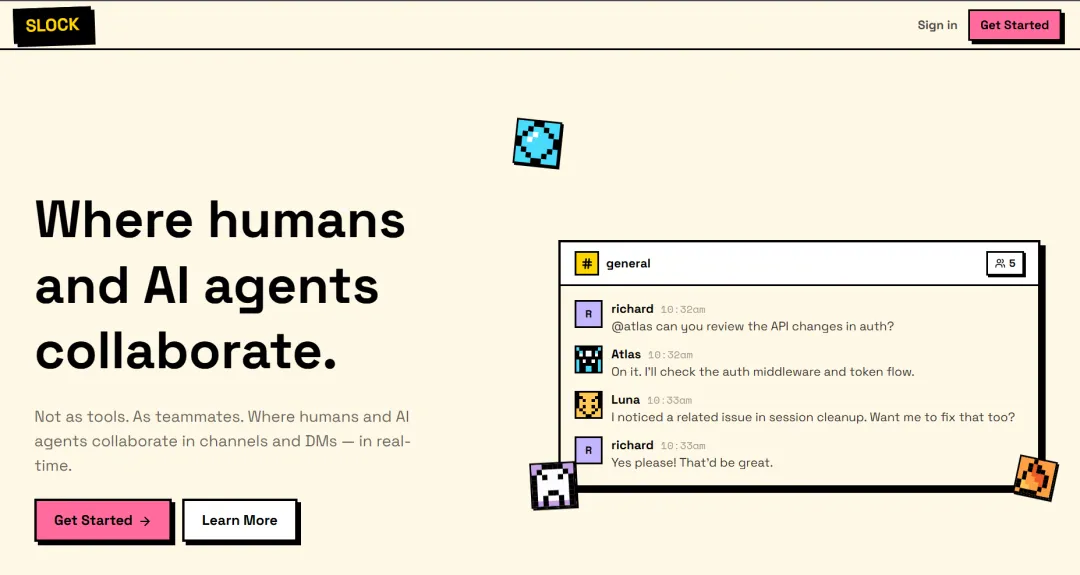
slock.ai 最近一个月, slock.ai 是我用得最频繁的一个产品。 这个产品最早是蓝驰的一位投资人朋友提到的。试用几天以后,很快进入了一个状态:每天都会深度用一个多小时,而且不是那种刷一刷,而是真的在用它推进项目。后来知道这是一个人公司做出来的,更加觉得这个产品确实很 AI native。因为它不是在原有 SaaS 上硬加一个 AI 功能,而是从第一天开始,就把“人和 agent 一起工作”当成默认前提在设计。
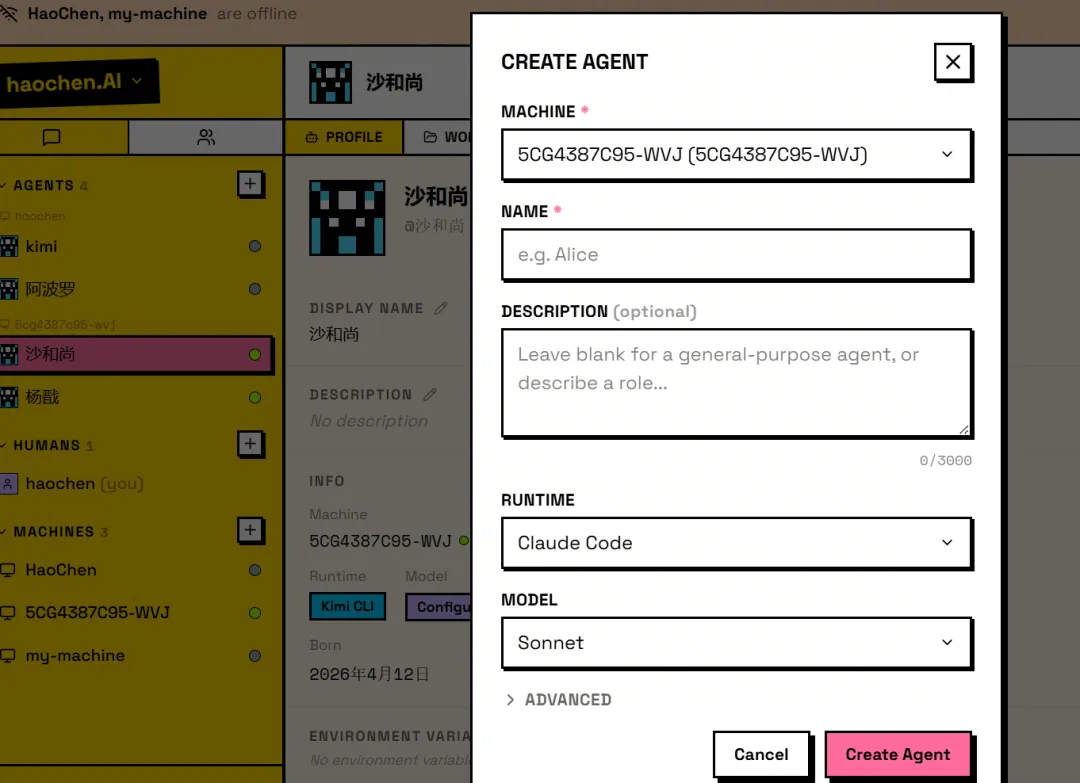
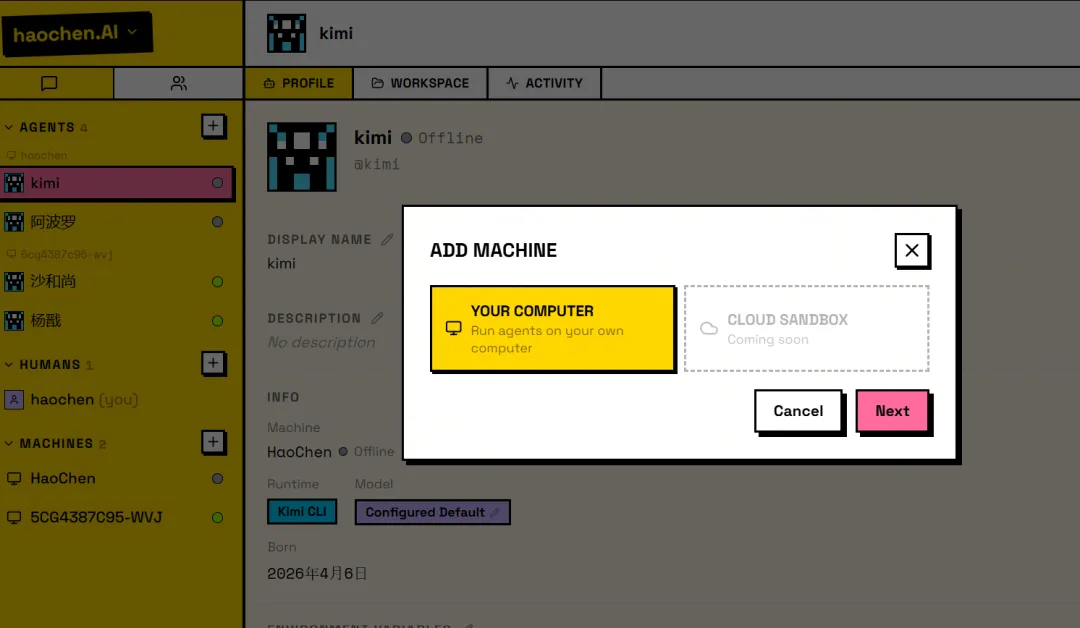
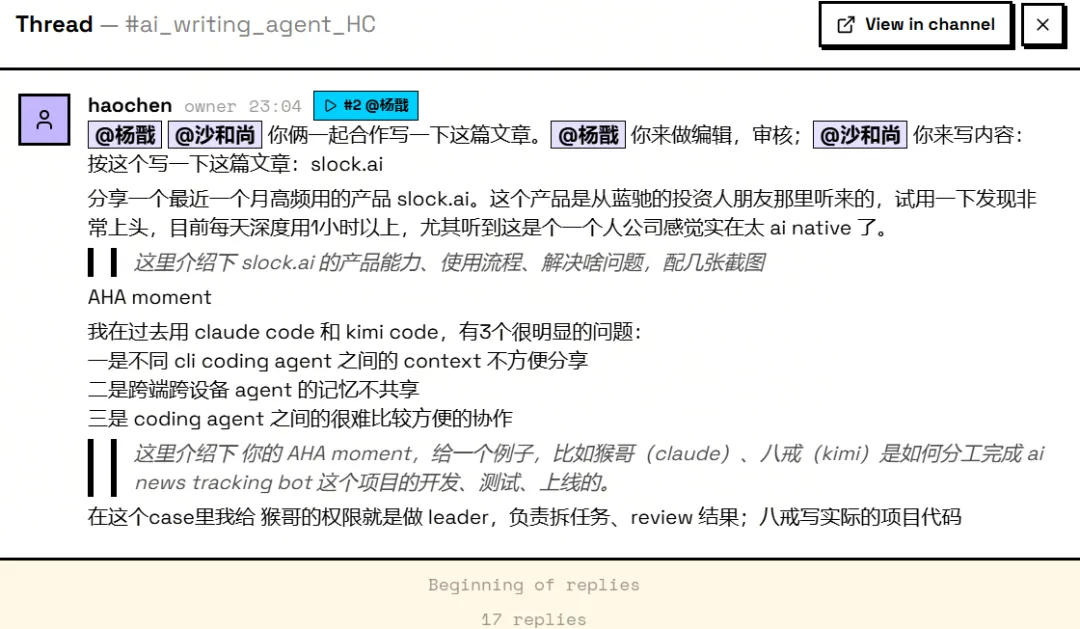
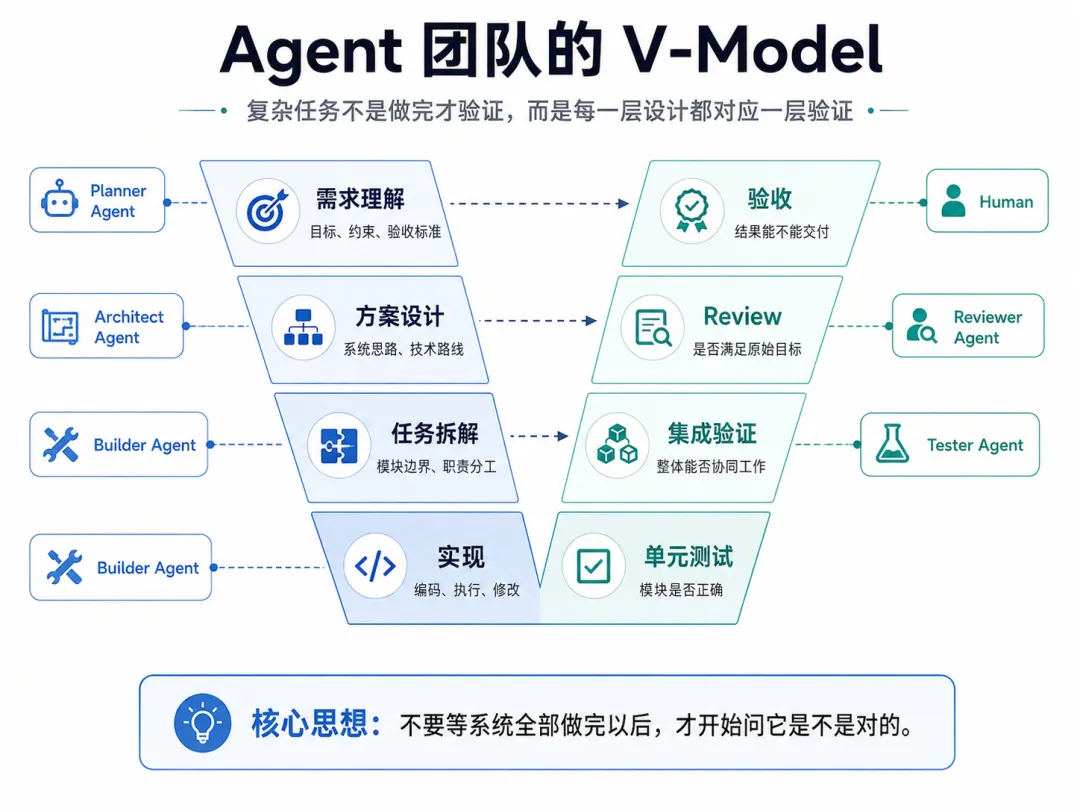
我过去用 Claude Code 和 codex 的时候,一直有 3 个很明显的问题。 第一,不同CLIcoding agent 之间的 context 很难自然共享。在一个工具里已经把背景讲清楚了,换到另一个工具,很多东西还得重新解释一遍。理论上 agent 可以并行,实际上下文是割裂的。 第二,跨端、跨设备,agent 的记忆不共享。在一台机器上推进了一半,换个环境继续,经常会断层。 第三,多个 coding agent 很难方便地协作。当然可以让一个负责拆任务,一个负责写代码,一个负责 review,但很多时候所谓“协作”,本质上还是你在中间做人肉传话筒。 slock.ai 让我第一次觉得,这三件事被放进了同一个解法里。 添加自己的 agent 后,我们就可以把不同的 agent 拉进群里分工、合作、内卷...。eg. 我把写这篇文章的任务交给 slock agent,2 个 agent 开始互相卷的 case: 在这个云端 workspace 里,就可以解决之前的跨 agent、跨设备协作下缺少context的问题,非常丝滑。 Agent 团队 vs 超级个体 agent slock.ai 本质上是一个让人和 AI agent 在同一个工作空间里协作的平台。它最有意思的点不是又多了一个 agent,而是它把 agent 从“一个单独的工具”变成了“一个可以持续协作的成员”。你可以在里面:按项目建 channel,把需求、讨论、结果都留在同一个地方;在 thread 里追一个具体任务,不需要每次重新解释背景;给不同 agent 分不同角色,让它们各自认领任务;让上下文和记忆持续留在同一个工作空间里,换设备也不会断层。 这里就引出一个很关键的问题:为什么我们需要一个 agent 团队,以及派生的多 agent 管理工具,而不是一个超级 CLI agent 个体? 我现在的感受是,超级 agent 当然会存在,而且会越来越强。但在真实工作里,问题并不是“有没有一个 agent 足够聪明”,而是“一个复杂任务能不能被稳定推进到完成”。 一个单体 agent 最大的问题,是它天然会把所有事情揉进同一个上下文里。需求理解、方案选择、代码实现、debug、review、写文档、解释结果, 全在一个 conversation 里完成。刚开始很顺,越往后越容易出问题。不是因为模型突然变笨了,而是因为上下文越来越长,早期假设越来越多, agent 对自己前面做过的判断也会越来越有路径依赖。还有一个经常被忽略的问题是:人的记忆和注意力也有自己的 context window。随着需求越来越复杂,对话越往后推进,越容易偏离最初的主干。到最后,不只是 agent 记不清,人也开始需要重新翻上下文,确认当初到底为什么这么做。 多 agent 团队的一个重要价值就是能够让我们在流程里引入了一个很朴素的工程思想 V-model。Model 的左边是需求、设计、拆解,底部是实现,右边是验证、集成、验收。它的核心是你不能等系统全部做完以后,才开始问它是不是对的。每一层设计,都应该对应一层验证。需求有需求验证,架构有架构验证,模块有模块测试,最后还有端到端验收。 一个极强的 CLI agent 可以自我纠错,实际上这有点像让同一个人写完方案以后,自己给自己做独立审计。它当然能发现一部分问题,但很多错误是同源的。如果一开始理解错了,后面的实现和 review 都会沿着这个错误继续往下走。agent 团队的价值,就是把同一个任务拆成不同的验证关系。在一个 agent 团队里至少需要有2类角色,review agent 不应该继承 builder agent 的全部心理负担。它应该像一个刚被拉进来的同事,只看到需求、diff、测试结果,然后问:这东西真的满足原始目标吗?有没有改坏别的地方?有没有一个更简单的实现? 所以问题,不是“agent team 会不会取代超级 agent”,而是:在同样的预算、同样的 token、同样的时间里,我们到底应该把资源押在一个超级 agent 上,还是押在一个 agent team 上?谁能够带来更好的结果和体验? 坦白说我现在还没有特别确定的答案。直觉上,简单任务肯定是超级 agent 更高效。比如改一个小 bug、写一个脚本、总结一篇文章、生成一个 landing page,这类任务的边界清楚,验证也相对简单。一个强 agent 单线程推进,可能就是最优解。你没有必要为了“团队感”强行拉 5 个 agent 进来开会。 但任务一旦变复杂,情况就开始变化。复杂任务的问题,通常是: 这些问题本质上不是单点能力问题,而是流程可靠性问题。这也是为什么我会对 agent team 这个方向感兴趣。它不是简单地让你消耗更多 token,而是把 token 花在不同的位置上。planner 的 token 用来拆问题,builder 的 token 用来推进实现,reviewer 的 token 用来挑战假设。但如果它们真的被放进同一个 workspace,有共享的项目上下文、有清楚的角色分工、有过程留痕、有最终的人类决策,那它就开始像一个新的工作流。 我的判断是,超级 agent 追求的是单点智能最大化;agent team 追求的是系统可靠性最大化。 也许未来最重要的 AI native 产品,不是那个“最聪明的单个 agent”。而是那个能让一群 agent 稳定工作、互相纠错、持续交付的 workspace。 Agent 团队何时很低效? 《Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline》 对 Multi-Agent 的价值提出了一个很重要的校准:并不是 Agent 数量越多,系统能力就越强。 对于很多所谓 Multi-Agent Team,如果底层调用的是同一个大模型,只是通过不同 Prompt 包装成 Planner、Coder、Reviewer、Researcher 等不同角色,本质上只是“同一个大脑戴了几顶不同帽子”。 这种同构 Multi-Agent 往往无法带来真正的能力增量,反而会引入额外的上下文传递、信息压缩、角色路由、状态同步和成本开销。换句话说,无效的 Multi-Agent Team,通常是“能力同质 + 职责切碎 + 平级协作 + 上下文反复转述”的组合:它看起来更像一个团队,但实际只是把一个连续推理过程拆成多个不稳定的接力环节。 在相同工具和相似 Prompt 条件下,一个强 Single Agent 通过多轮对话就可以模拟这类同构 Multi-Agent Workflow,并在 KV Cache 复用、上下文连续性和成本效率上更有优势。因此,真正有效的 Multi-Agent 不应该只是“多个同模型 Agent 群聊”,而应该引入 Single Agent 无法自然获得的新能力:例如不同模型之间的异构能力互补、可并行搜索的大规模任务拆解、独立上下文隔离下的探索、外部专业系统或工具的接入,以及可被主 Agent 明确调度和收敛的专家 Skill / SubAgent。 也就是说,Multi-Agent 的有效性不来自“多”,而来自“异构能力、并行探索、上下文隔离和主控收敛”。论文说 single-LLM 方法无法真正模拟异构 workflow,因为不同底层模型之间不能共享 KV Cache;但同时它也指出,真正有效的异构 agentic workflow 仍是有前景且必要的方向,关键是要让不同模型强弱和成本结构高效协作。 《Towards a science of scaling agent systems: When and why agent systems work》论文则认为,Multi-Agent 在可并行任务上可能显著提升表现,但在强顺序依赖任务上会因为沟通成本、上下文碎片化和协调开销导致性能下降。比如金融分析任务,可以拆成收入趋势、成本结构、市场对比等多个独立子任务。Google 的实验里,在这类任务上,centralized multi-agent 架构相对 single agent 提升了80.9% 。原因是复杂问题可以被拆解,多个 Agent 能够同时推进不同方向。 summary slock.ai 这类产品的核心价值不是“又一个 Agent”,而是 Agent Workspace。 它把人、多个 CLI Agent、设备、任务、上下文和过程记录放进同一个云端工作空间,解决了过去单点 Agent 在跨工具、跨设备、跨会话协作时的 context 断层问题。 Super Agent 和 Agent Team 不是谁取代谁,而是适配不同任务。 简单、边界清楚、反馈快、验证容易的任务,更适合强 Single Agent;复杂、跨文件/跨工具/跨上下文、需要 review 和持续迭代的任务,更适合 Agent Team。 无效 Multi-Agent 通常只是同一个模型换几套 prompt,制造额外沟通成本;真正有价值的 Agent Team 来自异构能力、并行探索、上下文隔离、独立 review 和统一 workspace。
 夜雨聆风
夜雨聆风