 夜雨聆风
夜雨聆风很多人用AI的方式,是这样的:
打开对话框,发一句话,等它回答,不满意,再发一句,再等,循环往复。
然后某一天你会发现:用AI半天,还不如自己直接干来得快。
但也有人用AI,像开挂一样——同一个问题,他们能拿到精准有用的答案,你只能拿到正确的废话。
差在哪里?不是提示词,是选马。
AI 是一匹马,你是骑手
先说一个认知:哪怕是目前全球最强的 AI 模型,也不是无所不知的完美大脑。
AI更像一匹马——有力气、能跑很远,甚至比人跑得快。但它不会自己决定去哪里。你的眼睛盯哪里,它的方向就在哪里;你松开缰绳,它就开始瞎晃。
你想得越清楚,AI 给你跑出来的结果就越好。你想得越糊涂,它给的答案就越平庸、越无用。
用好 AI 的上限,就是你思考能力的上限。
用 AI 久了,你大概遇过这五件事
① 它永远在夸你
你说"帮我挑问题",它说"思路很清晰,有几点小建议"。你换个方向,它立刻说"这个角度也很有价值"。你说什么,它都觉得好。
② 给你的全是正确的废话
"建议做好用户调研、建议打磨产品差异化"——每条都对,一条都没法用。
③ 越改越差,最后自己重写
让它写文案,不满意,让它改,改完更不对,折腾五轮,关掉对话,自己从头写。
④ 自信满满地瞎编
让它查个数据,它给你一个数字,口气笃定,来源写得有模有样。拿去一校验——假的。
⑤ 聊着聊着它失忆了
背景刚说清楚,它开始答非所问,之前说过的全忘了。开新窗口,一切归零,又要从头解释一遍。
这五种情况,不是 AI 能力的上限,是你和 AI 的对话方式还不对。
其中最容易被忽视、也最关键的一步,在对话还没开始之前:你有没有选对那匹马?
没有全能的模型,只有更合适的模型
我做过一个测试:
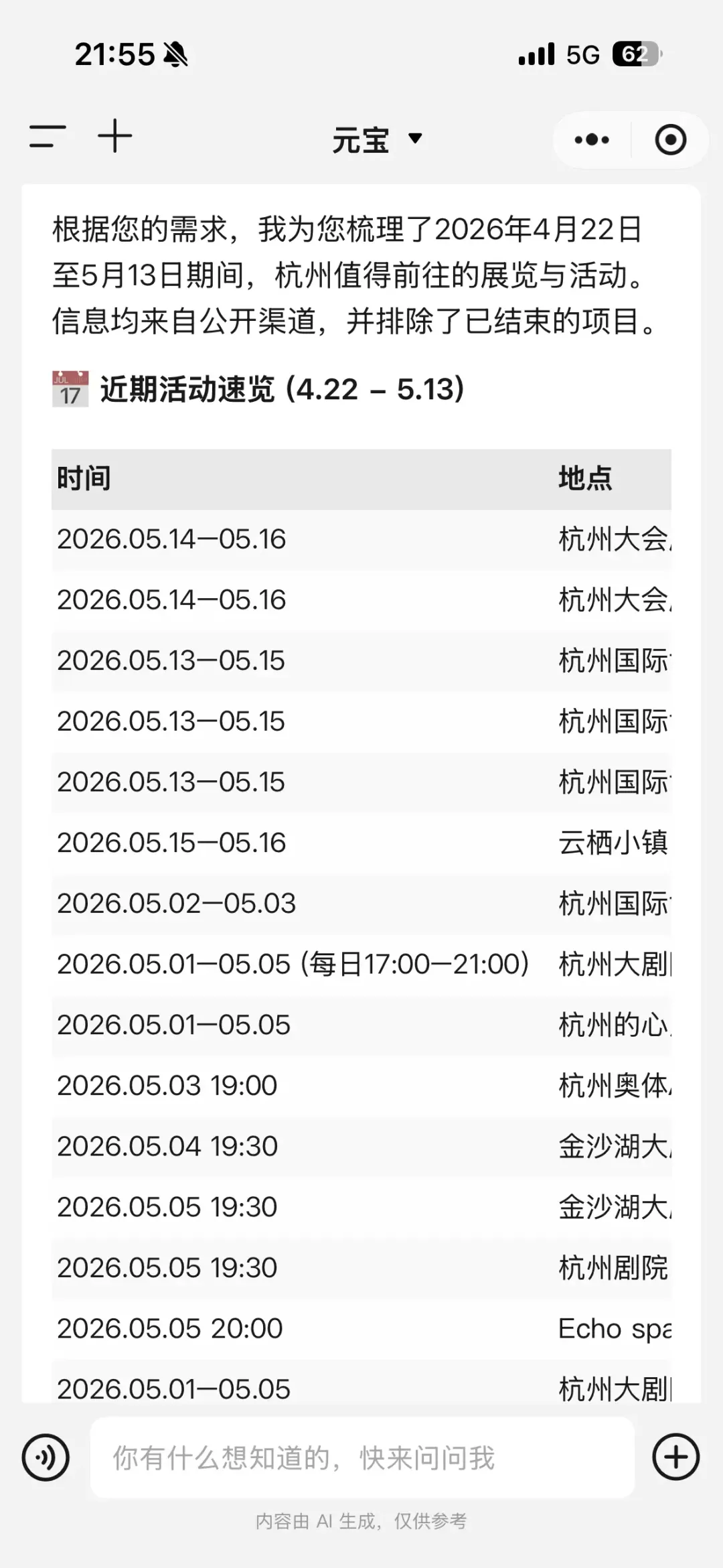
同一句提示词——"帮我找一下杭州最近三周有哪些值得去的展览"——分别问元宝和 ChatGPT。
结果差距很大。
元宝给出了一份数量丰富、时间精确、还能去的活动清单,信息来源主要是公众号和携程。
ChatGPT 给的榜单残缺,而且信息来源主要是搜狐、新浪财经,很多活动已经结束了。
 |  |
 |  |
问题不在提示词,在于 AI 手里有没有合适的数据源。
元宝作为腾讯的产品,有权限直接读取微信公众号的全量内容——这是它的天然长板。ChatGPT 再聪明,也拿不到这个权限。
这就是选马的意义:训练数据的差异,决定了每个模型的长板不一样。
一张速查表,帮你快速选马
没有全能的模型,只有更合适的模型。按任务选,而不是用习惯选。
| 元宝 | ||
| Claude | ||
| Gemini | ||
| 豆包 | ||
| GPT / Gemini |
交叉验证时,尽量选血统不同的两个 AI。
比如 Claude 主力 + 元宝校验,比 Claude + ChatGPT 效果更好——因为 Claude 和 ChatGPT 的训练语料重叠较大,异口同声的错反而更难被发现。
速查表半年更新一次,AI 进化很快,重要的不是记住这张表,是养成"按任务选模型"的习惯。
选好马之后,还要搭好挽具
选对模型只是第一步。真正决定对话质量的,是你给 AI 的上下文。
提示词决定怎么问,上下文决定怎么回答。
上下文 > 提示词。这是反直觉但反复验证的事实。
什么是好的上下文?三件事做好就够了:
① 先给它事实
AI 手里没事实,只能盯着你给的那段逻辑反复挑刺,给的建议听起来合理,但放到现实里根本跑不通。把你的真实背景、具体数据、实际处境给它,比任何提示词模板都管用。
② 再给它方向
告诉 AI 你要什么样的回答——多长、什么结构、必须包含什么、不要出现什么。不告诉它标准,它就按训练数据里最平均的形状,给你交一份 80 分的作业,这八成不是你需要的。
③ 让结果回传
按 AI 的建议去现实里跑一次,把真实结果喂回它。你做的越多次,它对你这个具体的人、具体的处境就越了解,下一轮的建议也就越准。
一个实用的对话习惯
最后分享一个让 AI 越用越好的小习惯:
一个窗口只做一件事,聊长了就开新窗。
AI 的"记忆"有上限,聊得越久,前面说过的东西越容易被它忘掉,答案开始打折、开始答非所问。
感觉它开始漂移了,就让它先写一份交接总结:
帮我总结下对话记录,包括:总目标 / 结论 / 待办 / 背景 / 核心事实
然后把这份总结发到新窗口,继续聊。
用好 AI,不需要背很多提示词模板。
你只需要在每次打开对话框之前,问自己一句:
我选对马了吗?
