 夜雨聆风
夜雨聆风你是不是也是这样。每天刷GitHub,看到别人分享的Claude Code skill就收藏。收藏了多久呢,大概从今年2月开始,到现在三个多月了。你猜我收藏了多少个,我自己都没数过,反正Star列表里一长串。
然后呢。
然后就没有然后了。
我从来没有认真研究过哪怕一个skill。不是不想研究,是总觉得「以后会用的」。这个「以后」,跟「我明天开始健身」一样,是一个永远不会到来的时间。
但这还不是全部。
我的Claude Code里面装了一堆skill。今天看到有人说这个skill好,装一个。明天看到另一个也不错,再装一个。装完之后,用的时候就是东一榔头西一棒子。这个项目用一下plan-eng-review,下一个项目用一下qa,再下一个可能什么都不用,就裸奔。
用了三个月Claude Code,我的效率跟第一天用的时候没有任何区别。
这不对吧。
后来我仔细想了一下,问题到底出在哪。是我的prompt不够好?还是我选的模型不够强?还是我这个人就不适合用AI?
都不是。
直到我最近读到了Garry Tan写的一系列文章。
Garry Tan是谁,YC的CEO,就是那个投了Coinbase、Instacart、Flexport的人。他开源了一个叫gstack的框架,GitHub上75000多颗星。他自己60天兼职交付了3个生产服务、40多个功能,日产出是2013年的408倍。
但让我有感触的,不是他的数字,而是他说的几句话。
差距不在模型,在你用AI的方式
说真的,我之前用AI的方式,就跟所谓的「裸模型」一样。什么叫裸模型,就是什么都没有,就一个对话框,你跟它聊天,它回答你。这跟用锤子钉钉子没什么区别,能用,但效率极低。
有一个叫Kingsbury的人,写过一篇32页的论文,系统性地论证裸LLM有多不可靠。浴室渲染忘了马桶,股票数据生成的是随机数字,让模型数字母它数不对,但它能做多变量微积分。他的结论是,AI就是这么不靠谱。
但这里有个关键问题。Kingsbury测的是引擎,不是汽车。
你把一个引擎放在台架上,发现它不能跑,然后宣称汽车不安全。这不是引擎的问题,是你没有给它装上轮子、方向盘、刹车系统。
这让我想到了一个类比。你买了一把很贵的吉他,但是从来不学乐理,也不练指法,就每天瞎弹。弹了三个月,你觉得这吉他有问题。其实不是吉他有问题,是你从来没有系统性地学过怎么弹。
AI也是一样。
大多数人用AI的方式是,遇到一个问题,打开对话框,把问题描述扔进去,看它回答得好不好。回答好了,开心一下。回答不好,换个说法再问一遍。
这种用法有个名字,叫「vibes-based」。就是凭感觉来。
这有一个根本性的问题。你今天调好了prompt,明天换了个问题,prompt又不灵了。你永远在调prompt,永远在试错,永远没有积累。
说真的,我自己就是这么用的。三个月了,没有任何进步。
但这些文章让我意识到,问题根本不在prompt,也不在模型。问题在于,你没有给AI搭建好基础设施。
有个数据让我注意到了。他自己的CLAUDE.md曾经膨胀到20000行,差不多是一本小书的长度。结果模型的表现越来越差,响应变慢,注意力退化,经常答非所问。
他把20000行压到200行之后,系统立刻变好了。
不是模型变聪明了,而是停止用噪音淹没它。
我自己的Claude Code其实也有这个问题。装了一堆skill,每个skill都有自己的prompt,全部塞进上下文窗口。模型要同时处理所有这些信息,注意力早就被分散了。
就像你同时打开50个浏览器标签页,你的电脑还能流畅运行吗。
这个问题叫「上下文膨胀」,agent系统的头号杀手。
还有一个数据。
有人做了一次可达性审计,发现系统里40多个skill中,有6个是完全不可达的。什么叫不可达,就是这些skill存在,但系统永远不会调用它们。相当于系统15%的能力处于黑暗状态。
这个问题在哪。不是这些skill不能用,而是你以为它们能用。关键时刻你指望它,它不响应,你才发现从来就没有连上线。
这让我想到了我自己。我收藏了一堆skill,但从来不研究、从来不配置。这不就是「不可达skill」吗。我自以为我的工具箱很丰富,实际上能用得上的寥寥无几。
gstack的设计逻辑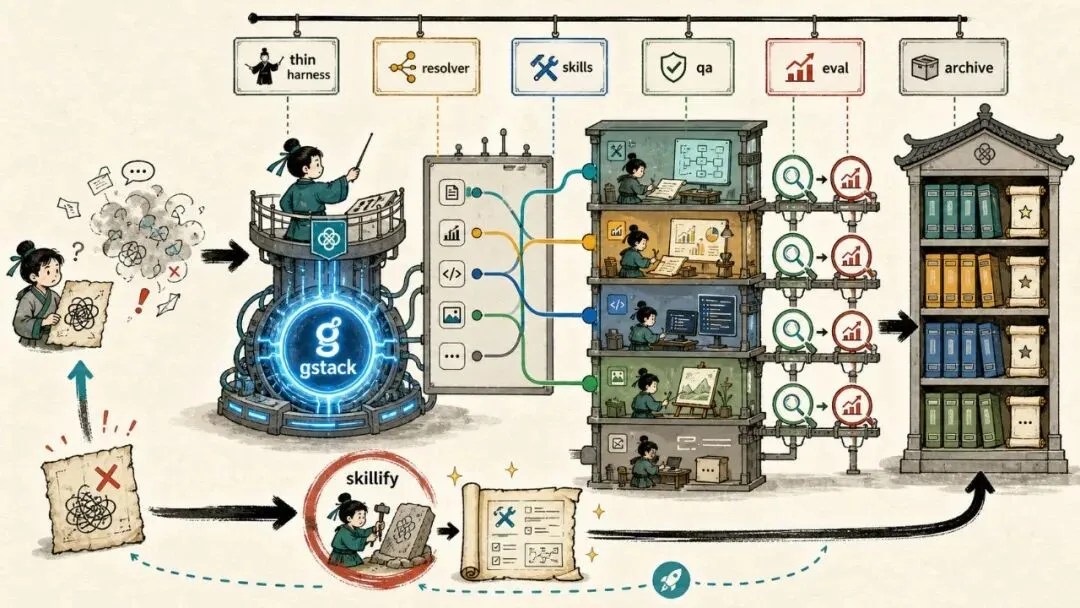
说到这里,我想聊聊gstack。
我一开始看到gstack的23个skill,第一反应是,这也太多了吧,谁能用得过来。但后来我理解了,这23个skill不是功能堆砌,每个都对应一个具体的AI使用问题。
比如/qa,为什么要有这个。AI生成的代码你永远不能直接信任。有一句话说得很直白,「高速生成自信的垃圾」。他自己从1月的大约100个测试增长到了2000多个,测试覆盖率从0到了关键路径100%。没有测试层的AI辅助编码,你只是在用更快的速度制造bug。
比如resolver,这是gstack里最核心但也最容易被忽视的机制。你可以把它理解成一个路由表,当任务类型X出现时,先加载文档Y。听起来很简单对吧。
但审计了13个写入知识库的skill,发现只有3个引用了resolver,其余10个各自硬编码了归档路径。这导致什么,信息缓慢漂移到错误的位置,知识库逐渐变成垃圾抽屉。
没有管理层的组织只是一堆有才华的员工和模糊的协调期望。skill是你的员工,resolver是你的组织架构图。没有架构图,员工再多也只是一盘散沙。
这完美解释了我自己的问题。我装了一堆skill,东用一个西用一个,完全没有积累。因为我从来没有想过,这些skill之间应该怎么协作,什么时候该用哪个,什么任务应该路由到什么skill。
我不是缺少工具,我是缺少管理层。
说真的,你有没有过这种感觉。每次开一个新的AI对话,感觉就像重新开始。上次踩过的坑,下次继续踩。上次的灵感,下次完全想不起来。这不是AI的问题,是你从来没有把经验codify下来。
这个方法叫「Skillify」。就是把你每一次失败转化为一个永久性的结构修复。不是改个prompt就完了,而是写成skill文件,加上确定性代码、单元测试、集成测试、LLM eval,然后注册到resolver里,最后归档。
他甚至把这变成了一个动词。在对话里说一句「skillify it」,agent就会把临时方案变成永久的基础设施。
具体来说,一个skill要经过十步才算真正完成。skill合约定义,然后写确定性代码,再写单元测试,接着集成测试,再跑LLM eval验证agent是否走了正确的流程,然后注册resolver触发器,再eval resolver的路由准确性,再做可达性审计看有没有dead skill,最后E2E smoke test和归档规则。
听起来很繁琐对吧。但有一句话我觉得说到了点上,「不允许做一次性工作」。
这不是提示技巧,是架构原则。如果你一件事需要做两次以上,就必须codify成skill文件。
我自己呢。说实话,我做了太多一次性工作了。每次遇到问题就临时解决,解决了就过去了。下次遇到同样的问题,又是从头开始。没有任何积累。
这不就是我用AI的真实写照吗。
好的skill到底基于什么
顺着这个思路再往下想。还有一个反直觉的观点。skill文件本质上是方法调用。同一个skill,指向不同参数就能产生完全不同的结果。比如一个匹配skill,1200人按行业聚类是一个效果,600人跨行业随机匹配是另一个效果,200人实时最近邻配对又是另一个效果。同一个流程,不同的世界。
这就回答了我之前一直想不通的一个问题。好的skill到底是基于什么。
不是基于某个神奇的prompt模板,不是基于某个大神的独家秘方。是基于你自己的工作流。你反复做的事情,你踩过的坑,你总结出来的最佳实践,把这些codify下来,就是你的skill。
所以答案很清楚了。我能不能做出适合自己的一套skill。当然可以。但前提是,我得先有积累。我得先「不允许自己做一次性工作」。每次踩坑,就写一个skill。每次发现一个好方法,就写一个skill。时间长了,这就是我自己的体系。
skill是永久升级的。写一次,永不降级,永不遗忘。当下一个模型发布,所有skill立刻变好。
这个「立刻变好」怎么理解。就是说,skill文件里需要模型判断和推理的部分,会随着模型升级而自动提升。而确定性执行的部分则保持稳定可靠。
这就好比你的操作系统升级了,所有软件自动变快了,但底层硬件接口不变。你不需要重写任何代码。
回到我自己的情况。我现在用的gstack就是这种架构。thin harness加fat skills。harness只负责编排,不承载任何领域知识。所有的智能都在skill里。
这种架构的好处是,我不需要每次都重新教AI怎么做事。我只需要写好skill,然后通过resolver告诉系统什么时候该用哪个skill。AI会按照我预先定义好的流程来执行,而不是每次都从零开始瞎猜。
说真的,这改变了我对AI的看法。
以前我觉得AI就是一个聪明的助手,你告诉它什么,它就做什么。你告诉得越好,它做得越好。所以我一直在追求更好的prompt,更好的模型。
但现在我觉得AI更像是一个组织。你是CEO,模型是你的员工,skill是标准操作流程,resolver是组织架构图,测试是质量管理体系。
没有这些基础设施的CEO,就是一个光杆司令,什么事都亲力亲为,累个半死但效率极低。
有了这些基础设施的CEO,才能真正实现「从想法到可用产品的周期从3周缩短到3小时」。
这个数字让很多人质疑。有人说LOC是垃圾指标,有人说AI膨胀了代码量。都对。但做了双重deflate之后,去空行去注释再打2折,仍然有408倍。即使取极端的10倍deflate,也有81倍。
系数大小的争论不改变结论。
但也有最诚实的steelman。如果两年后80%的代码对应的产品死了,那「你造了一堆没人用的东西」这个批评就成立了。他接受这个现实检验。
我觉得这种坦诚很难得。不是说我的方法完美无缺,而是说我知道它不完美,但我愿意用时间来验证。
回到我们每个人身上。其实我们不需要做到100x。甚至不需要10x。
只要你开始系统性地使用AI,开始把每一次踩坑变成积累,开始建立自己的skill体系,你就已经比90%的人走得更远了。
我自己也还在摸索中。说实话,这篇文章写的过程,就是我第一次认真研究gstack设计原理的过程。之前我也只是装了gstack,东用一下西用一下,跟大家一样。
但写完这篇文章之后,我至少明白了一件事。
我之前的问题不是AI不够好,是我没有给AI搭建好基础设施。
接下来我要做的第一件事,就是清理我的Claude Code。把不用的skill删掉,把核心的skill研究透,然后建立自己的resolver。
一步一步来吧。
