 夜雨聆风
夜雨聆风我们打开agent,输个问题,按回车。需要等半秒。然后字开始往外蹦——越来越快。有没有想过:为什么第一个字要"愣"一下,后面又突然变快?
其实AI这时候根本没在思考——它只是在接龙。而且用了两套完全不同的方式来完成这件事。今天我用最朴素的话,跟大家聊一聊。
超级猜词器
 。
。我们输入"法国的首都是",它猜"巴"。把"巴"接上去,变成"法国的首都是巴"——再猜"黎"。再接上,再猜。一次一次猜下去。
听起来很蠢对吧。但它猜得确实很准。
怎么做到的?就三个步骤。
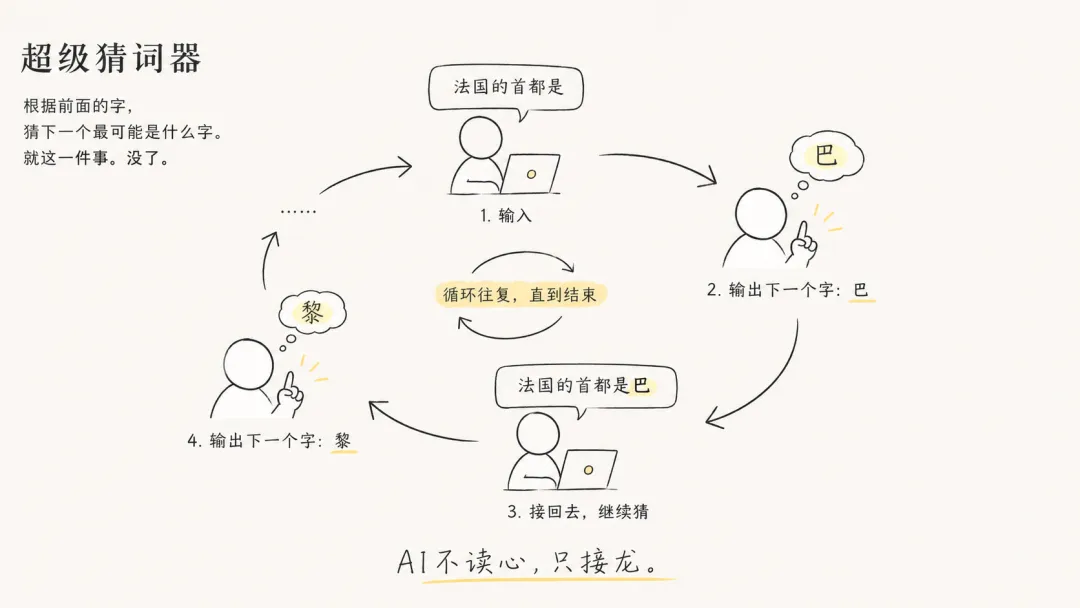
[猜词循环示意图——"法国的首都是"进入模型→输出"巴"→接回去→"法国的首都是巴"→输出"黎"→循环箭头标注]
三步把猜词做到极致
1. 切菜
AI不认汉字,只认数字。你输入的内容,它先切成小块——"法国""的""首都""是"。每一块你可以理解成乐高积木块。
别以为切菜无所谓。切法直接影响你花多少钱。有些非主流语言切得稀碎,同样一句话,积木块数是英文的两三倍——又贵又慢。
看到这里是不是意识到我之前这篇文章里面,讲的中英文token对比?就是这么个道理 公众号:epoch2023我教老婆用AI(一):从只会豆包,到拥有自己的AI大脑
2. 查字典
每块积木分配一个数字编号,去一张巨大的"含义地图"里找位置。"法国"离"巴黎"很近,离"北京"远。"好吃"挨着"美味",离"难吃"老远。
这一步让AI明白词跟词之间的关系。
3. 前后对照
这是最厉害的一步。
AI读"小明把苹果给了小红,她很高兴"——它得搞清楚"她"是谁。怎么做?让每个词去"看"句子里所有其他词,问一句:你跟我什么关系?
"她"看到"小红"——关系极强。"她"看到"小明"——关系弱。所以"她"=小红。
这个"互相看"的机制堆了几十层。一层层对照下来,几千字之间的复杂关系全追踪得到。
这三步,每回答一个字都要跑一遍。那你可能会问——为什么第一个字那么慢,后面的字哗哗出?
这恰好是我觉得整个推理过程最精彩的部分。
同一个工人,两套完全不同的干法
你按回车后,工人把你输入的全部内容一次性读完。所有字同时算,一锅全出。这时候工人累到冒烟——手脚并用,能跑多快跑多快。
你看到的是什么?屏幕空白的那半秒。第一个字还没出现。
阶段二:一个字一个字往外蹦
第一个字出来了。工人换姿势。要算出第51个字,他只需要算新字的意思。前面50个字已经算过了——不重算。工作量极小。
但有个麻烦:他每次都得从工作台上把之前存的东西全翻出来,算完新字那点东西,再全放回去。大部分时间花在搬东西上,不是算东西上。
同一个工人,同一个请求。前半段累死,后半段闲死。瓶颈完全倒过来了。所以你看,不是AI在装——它是真的忙了半秒。
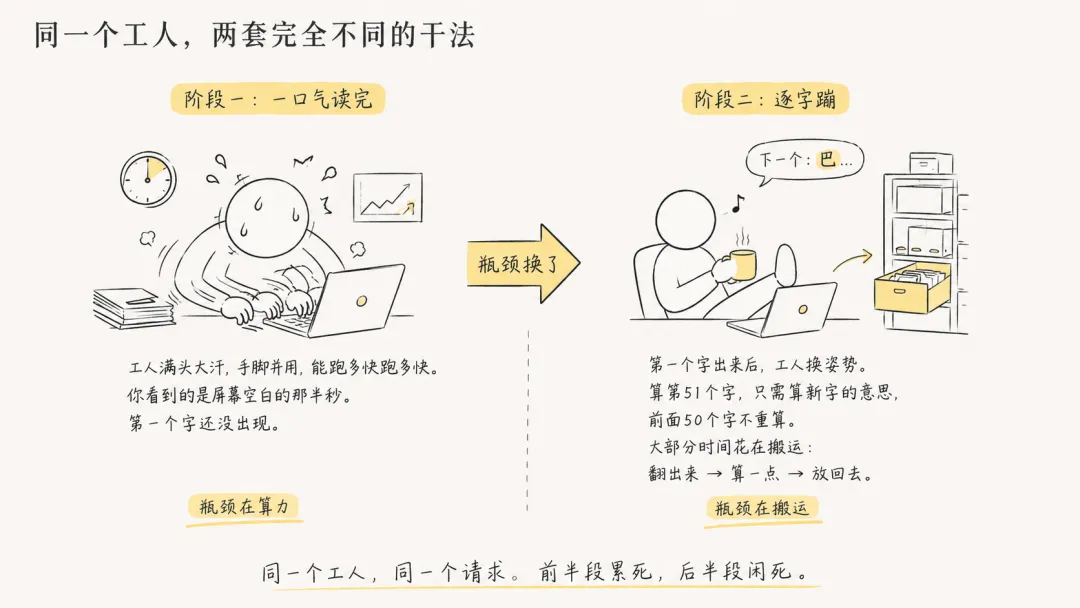
[两个阶段对比图——左边"一口气读完:工人满头大汗→瓶颈在算力",右边"逐字蹦:工人翘着腿喝茶→瓶颈在搬运",中间大箭头标注"瓶颈换了"]
有些工人,开口前会先打草稿
前面说的是普通工人:问啥猜啥,一个字一个字往外蹦。但你可能遇到过另一种情况——输入问题后,屏幕显示"正在思考…",或者空白好几秒甚至几分钟,才开始出字。
这是另一种工人。我叫它"先打草稿型"。
打个比方:
普通工人:嘴快。你问"356×789等于多少",他脱口而出——快是快,但复杂问题容易出错。
打草稿工人:不急。同一道题,他先在草稿纸上列竖式、一步一步算、算完再检查一遍。你等了好几秒,他才把答案抄给你——慢,但靠谱。
打草稿工人的核心区别:他在后台自己跟自己说了很多话。这些话你看不见,但他必须说完,才能给你最终答案。
什么话?比如:
"先分解一下问题……有三种解法……第一种可能不对……第二种简洁一些……好,就用第二种。开始算……完了检查一下……没问题,输出。"
这些"心里话"也要花时间——而且也会记在草稿纸上。
什么时候用哪个?
1. 日常聊天、查信息、写文案 → 普通快模型,够用了。
2. 数学题、写代码、逻辑推理、需要多步判断 → 打草稿型,答案质量高一大截。
小技巧:不想等太久?提示词里加一句"直接回答,不用分析过程"——它就会少想几步,快很多。
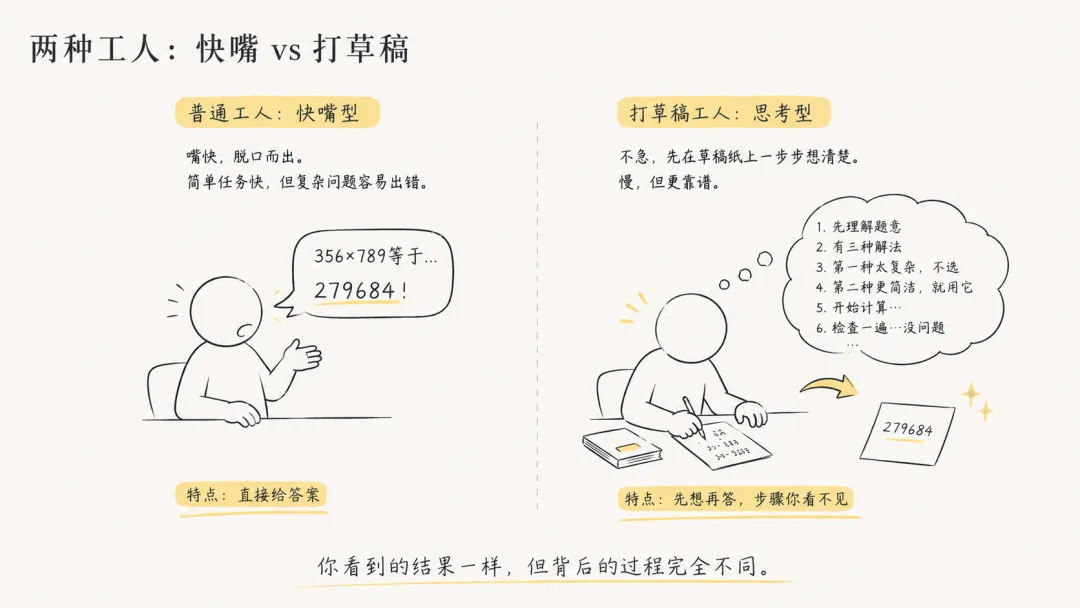
[两个工人对比——左边"快嘴工人:脱口而出,嘴巴比脑子快",右边"打草稿工人:先列提纲、算完检查、再抄到卷子上",标注"你看不见的思考步骤"]
草稿纸:KV缓存
刚才说了普通工人记草稿纸。打草稿工人更夸张——那些你看不见的"心里话",也全记在上面。聊几句难题,草稿纸膨胀得比普通对话快好几倍。
这个存放处有个专业名叫KV缓存。朴素点说就是:草稿纸。
每说一个字,顺手在草稿纸上记一笔。下次猜新字翻草稿纸就行,不用从头再想。
没有草稿纸会怎样?猜第1000个字的时候,得把前999个字全部重新理解一遍。那速度——你等它答完,可以去泡碗面再睡一觉。
有草稿纸:存一次,反复翻。速度提升5倍以上。
代价呢?草稿纸巨占地方。聊到4000个字的时候,光草稿纸能占掉4GB桌面空间——相当于你电脑同时开了几十个大型软件。
这就解释了一个你绝对遇到过的现象:跟AI聊久了,它越来越慢。
你以为网不好?AI累了?就是草稿纸堆满了桌面,工人每次都得在纸堆里翻。
前沿研究在干嘛?目前主要是:缩小草稿纸。让它用更少的空间记住更多东西。我关注的DeepSeek V4就在搞这事——直接把记笔记的方式重新设计了一遍,同样记住100万字,草稿纸只占原来的十分之一。这才是从根上解决问题。
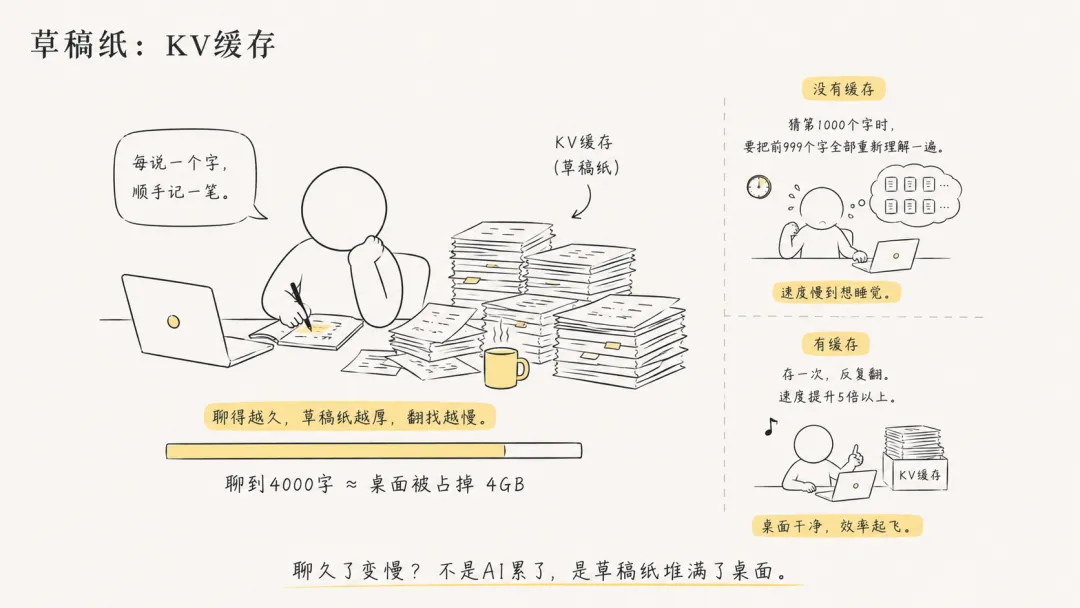
[草稿纸示意图——AI工人面前堆着越来越厚的草稿纸,标注"聊到4000字≈桌面被占掉4GB"]
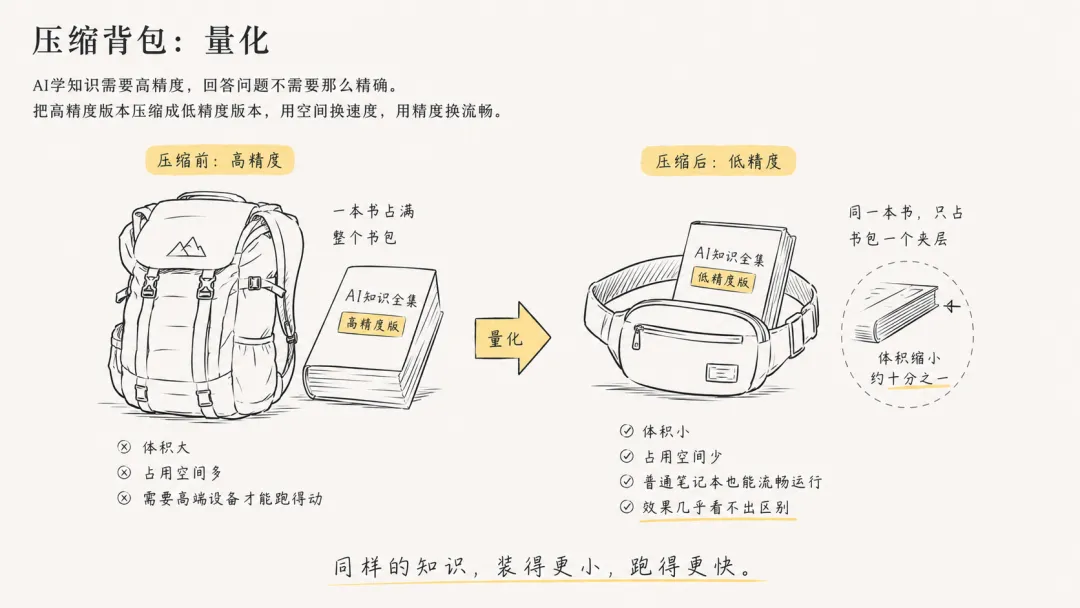
压缩背包:量化
AI学知识的时候需要高精度。就像实验室配药,毫克都不能差。但回答你问题的时候,不需要那么精确。就像你去菜市场买菜,家用秤够了。
把高精度版本压缩成低精度版本:
原版:一本书占满整个书包
压缩版:同一本书,只占书包一个夹层,内容几乎没变,你看不出区别
这就叫量化。用精度换速度,用空间换流畅。
关我们什么事
1. 问题长影响不大,回答长才是真影响很大。
问题长 → 第一个字出得慢(一口气读完费劲)
想让AI快,让它答短点。试试说"用3句话回答"——立竿见影。
2. 聊久了就开新的对话。
AI变慢了?新建窗口。草稿纸清零,满血复活。
3. 模型选对的,不用追参数大的。
日常聊天 → 普通快模型,够用。
复杂问题(数学、代码、逻辑推理)→ 切到"思考型"或"推理型"模型,慢但正确率高得多。
自己电脑跑 → 选"压缩版"模型,速度翻倍,效果你基本感觉不到区别。
4. 别被"第一个字多快"的宣传忽悠。
有些模型第一个字快,后面蹦得慢。有些反过来。看整体聊天体验,别盯单一数字。
AI愣那半秒,并没有在思考——它在让工人一口气读完你的话。然后换个姿势,开始逐字往外猜。碰上难题,它可能还要先打一遍草稿。
猜得准不准,看它读了多少书。猜得快不快,看它草稿纸管得好不好、背包压得够不够狠。
整个"人工智能"的神秘感,拆解开看就是:切菜、查字典、前后对照、打草稿、记草稿纸、压缩背包。
哈哈哈哈。是不是没想象中那么神秘高大上?
