 夜雨聆风
夜雨聆风上篇说,AI 工具链越用越乱的根源不是工具选错了,是工程系统没有边界。
三类症状我拆完了:输入没有边界、执行没有边界、输出没有边界。
但"有边界"和"没边界",代码里长什么样?
这篇我用一个可以跑通的 Demo 把三类边界的工程实现拆出来。
Demo 场景
一个工程报告分类 Agent。
工程师提交一条问题报告,Agent 负责:结构化提取信息 → 判断是否可操作 → 分类并给出处理建议。
技术栈:TypeScript + OpenAI SDK(接 DeepSeek)+ Zod。场景很普通,但足以演示三类边界的完整结构。
输入边界:两层门控,不满足就不进 AI
输入边界的核心问题是:什么样的输入才能进入 AI 处理流程?
答案不是"有内容就行",而是"满足结构要求才行"。
我的实现分两层。
第一层:前置规则检查(不调用 AI)
在任何 API 调用之前,先做基本验证。这些检查不消耗 token,不满足直接拒绝:
if (!rawText || rawText.trim().length < 20) { throw new InputBoundaryError( `输入过短(当前 ${rawText.trim().length} 字符,最少 20 字符)` )}第二层:AI 提取后的 Zod 验证
让 AI 把原始文本提取成结构化字段,然后用 Zod 验证提取结果是否符合 schema:
const result = StructuredReportSchema.safeParse(raw)if (!result.success) { const missingFields = result.error.errors.map((e) => e.path.join('.')) throw new InputBoundaryError( `结构化提取失败,以下字段缺失或无效:${missingFields.join(', ')}` )}Schema 明确了哪些字段必须有、允许哪些值:
export const StructuredReportSchema = z.object({ problemType: z.enum(['bug', 'performance', 'security', 'question', 'feature']), severity: z.enum(['critical', 'high', 'medium', 'low']), affectedSystem: z.string().min(1), description: z.string().min(10), reproductionSteps: z.string().nullable(), context: z.string().nullable(),})实际跑起来,"接口有时候报错。"这样的输入——8 个字符,直接在第一层被拦下,提取 prompt 根本没有发出去:
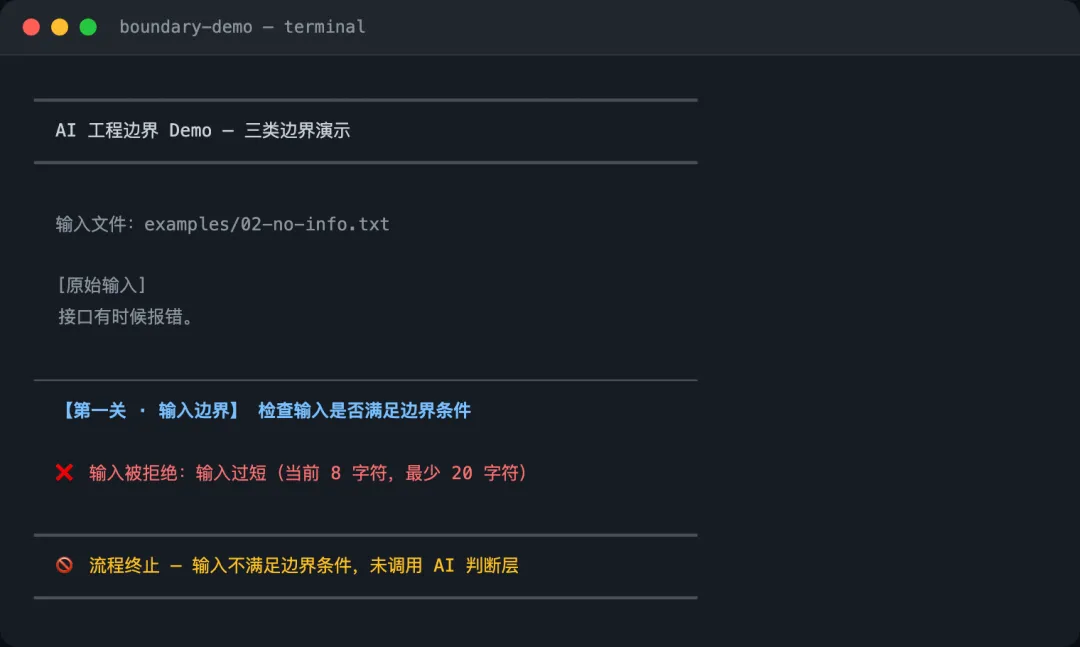
执行边界:判断层和执行层,必须分开
这是三类边界里最容易被忽视的一个。
常见的做法是把"判断能不能处理"和"决定怎么处理"写在同一个 prompt 里。逻辑上没问题,但一旦出了问题,你根本定位不了:是判断错了,还是决策错了?
我的做法是把两者完全拆开。
判断层:只负责一件事——这份报告有没有足够信息可以被处理?
content: `你是分流判断器。你的唯一职责是判断这份工程报告是否有足够信息可以被分类处理。返回 JSON:{ "actionable": true | false, "reason": "...", "missingInfo": [...] }`执行层:只在判断层确认 actionable=true 之后才被调用,只负责分类决策:
content: `你是分类决策引擎。给定一份已验证的、可操作的工程报告,输出处理决策。`两个独立的 LLM call,各自的 prompt 只做一件事。
直接的好处是:哪一层出了问题,立刻能定位。判断层返回 actionable=false 时,执行层根本不会被调用。
实际跑起来,"交易平台性能下降,但不知道具体在哪"这样的报告——输入边界通过了(能提取出结构化字段),判断层给出明确的拒绝理由,执行层没被触发:

这里有个值得注意的细节:severity 字段被 AI 猜成了 medium,Zod 没有拒绝它,输入边界通过了。但判断层没有放行。
输入边界回答的是"结构合不合法",判断层回答的是"信息够不够"。两个问题不同,两层各司其职。如果把这两层合并,就分不清是哪个维度出了问题。
输出边界:不验证,就没有可靠性
AI 的输出格式不是永远可信的。
没有输出边界,工具链就建立在"AI 大概会按格式输出"这个假设上。这个假设会在某个时刻失效,然后你会在下游某个地方看到一个奇怪的报错,不知道从哪里来。
我的做法是用 Zod 对执行层的输出做强校验:
const result = ClassificationResultSchema.safeParse(raw)if (!result.success) { throw new OutputBoundaryError( `输出被拒绝,schema 校验失败:${violations.join('; ')}` )}Schema 定义了所有允许的值域:
export const ClassificationResultSchema = z.object({ category: z.enum(['incident', 'task', 'investigation', 'documentation', 'wont-fix']), priority: z.enum(['P0', 'P1', 'P2', 'P3']), suggestedAction: z.string().min(1).max(200), estimatedEffort: z.enum(['< 1h', '1-4h', '4-8h', '> 1 day']), shouldEscalate: z.boolean(),})通不过验证,直接拒绝,不流入下游。下游收到的永远是结构确定的数据,而不是"大概对"的内容。
三类边界跑通之后
信息清晰的报告,四关全部通过,直接拿到分类结果:

三类边界建立之后,这个 Agent 有一个明显的特征:
出了问题,能知道在哪里出的。
输入边界拒绝了,是原始数据不满足条件。判断层拒绝了,是信息不够充分。执行层的输出被输出边界拒绝,是 AI 没有按格式输出。每一层的职责是清楚的,每一层的拒绝理由是可追踪的。
这和没有边界时完全不同。没有边界时,出了问题,你不知道是哪个环节错了,只能从头找。
边界不是在限制 AI。
边界是在给每一个组件一个清晰的工位:你负责什么,你拒绝什么,你的输出长什么样。
工位清楚了,工具链才能稳定运转。
如果这篇对你有用,点个 ❤️ 推荐给更多工程人。
关注「架构师的AI实验室」,持续记录 AI 进入工程系统的真实过程。
