 夜雨聆风
夜雨聆风【导读】AI 评测圈投下一颗重磅炸弹——Epoch AI 官方宣布,对旗下高难数学基准 FrontierMath 进行 AI 辅助审查后,发现约三分之一的题目存在致命错误,且初步认为多数标记有效。这意味着,过去基于这套评测集跑出的模型成绩,都将在修正数据集上重新计算。一个以「答案可验证」为核心卖点的顶级 benchmark,自己的题目先出了问题。
官方公告:约三分之一题目被标为致命错误
5 月 12 日,Epoch AI 在官方 X 账号发布了一条公告:
"We are conducting an AI-assisted review of FrontierMath: Tiers 1-4. This has flagged fatal errors in about a third of problems, and we believe most of these flags to be valid. We will release updated scores on a corrected dataset after completing a thorough human review."
「我们正在对 FrontierMath Tiers 1-4 进行 AI 辅助审查。审查已标记出约三分之一题目存在致命错误,我们认为其中多数标记有效。完成彻底的人工审查后,将在修正数据集上发布更新成绩。」

▲ Epoch AI 官方 X 公告,18 万次浏览
同一天,FrontierMath Tiers 1-4 的官方页面首屏也挂出了更新提示,标注日期为 2026-05-11,内容与 X 帖完全一致。
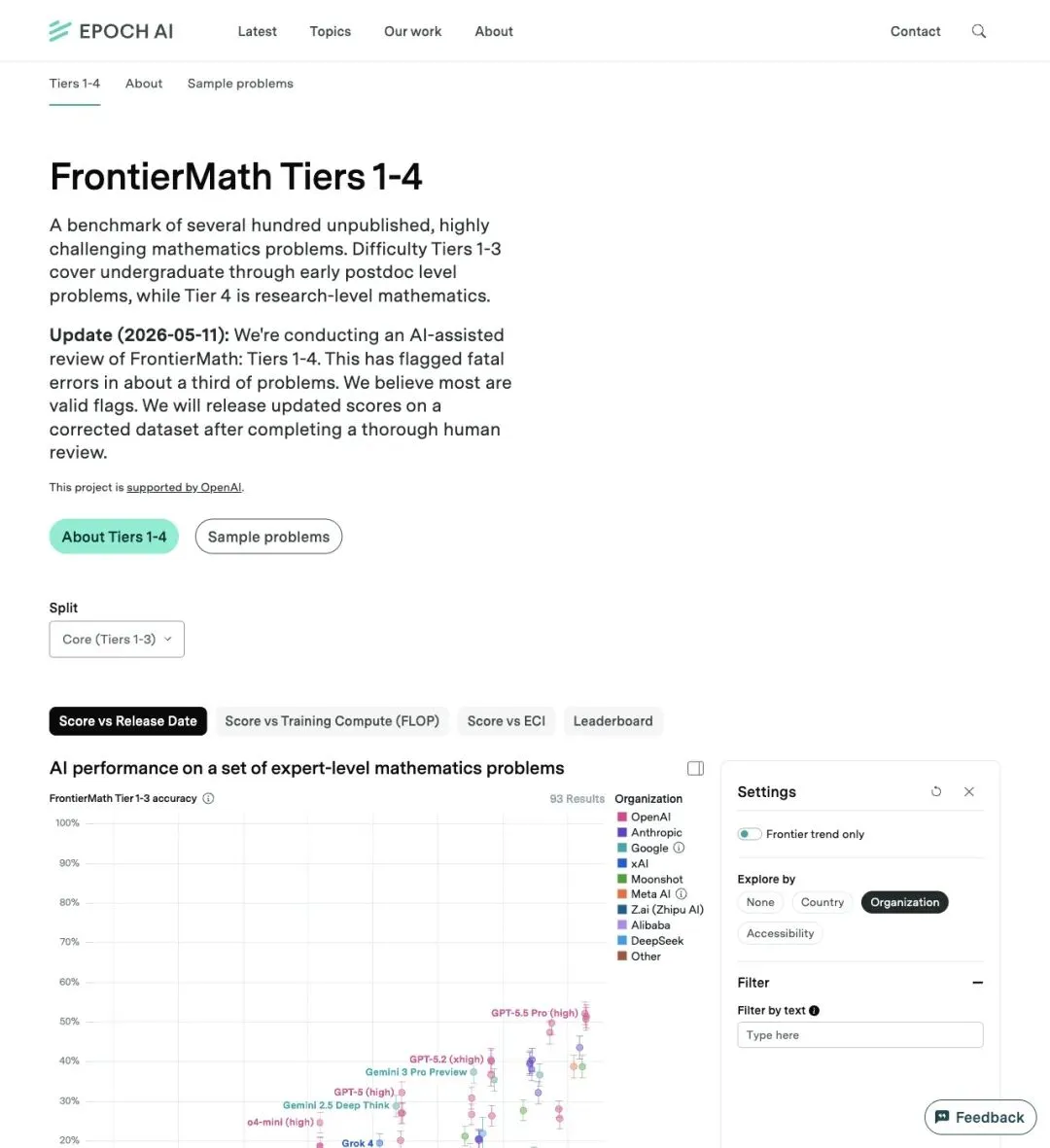
▲ FrontierMath 官方页面已挂出更新公告,旧排行榜后续将重算
两个渠道同步发布,说明 Epoch 团队经过审慎考虑,正式向社区摊牌。
这里有两个关键边界需要注意:第一,当前仍处于 flag 阶段,Epoch 用的词是「flagged」和「believe most to be valid」,最终审计报告尚未出炉;第二,Epoch 明确表示后续还要做 thorough human review,不会跳过人工复核。
但即便如此,「约三分之一」这个比例已经足够惊人。
350 道「最难数学题」,到底有多难?
要理解这件事的冲击力,得先了解 FrontierMath 在 AI 评测圈的地位。
FrontierMath 包含350 道原创数学题,覆盖从大学高阶到专家级难度,横跨代数、几何、数论、组合等多个领域。官方的设计理念很明确:
"FrontierMath comprises 350 original mathematics problems spanning from challenging university-level questions to problems that may take expert mathematicians days to solve, covering a wide variety of topics."
「FrontierMath 包含 350 道原创数学题,涵盖从高难度大学级别到可能让专家数学家花费数天解决的问题。」
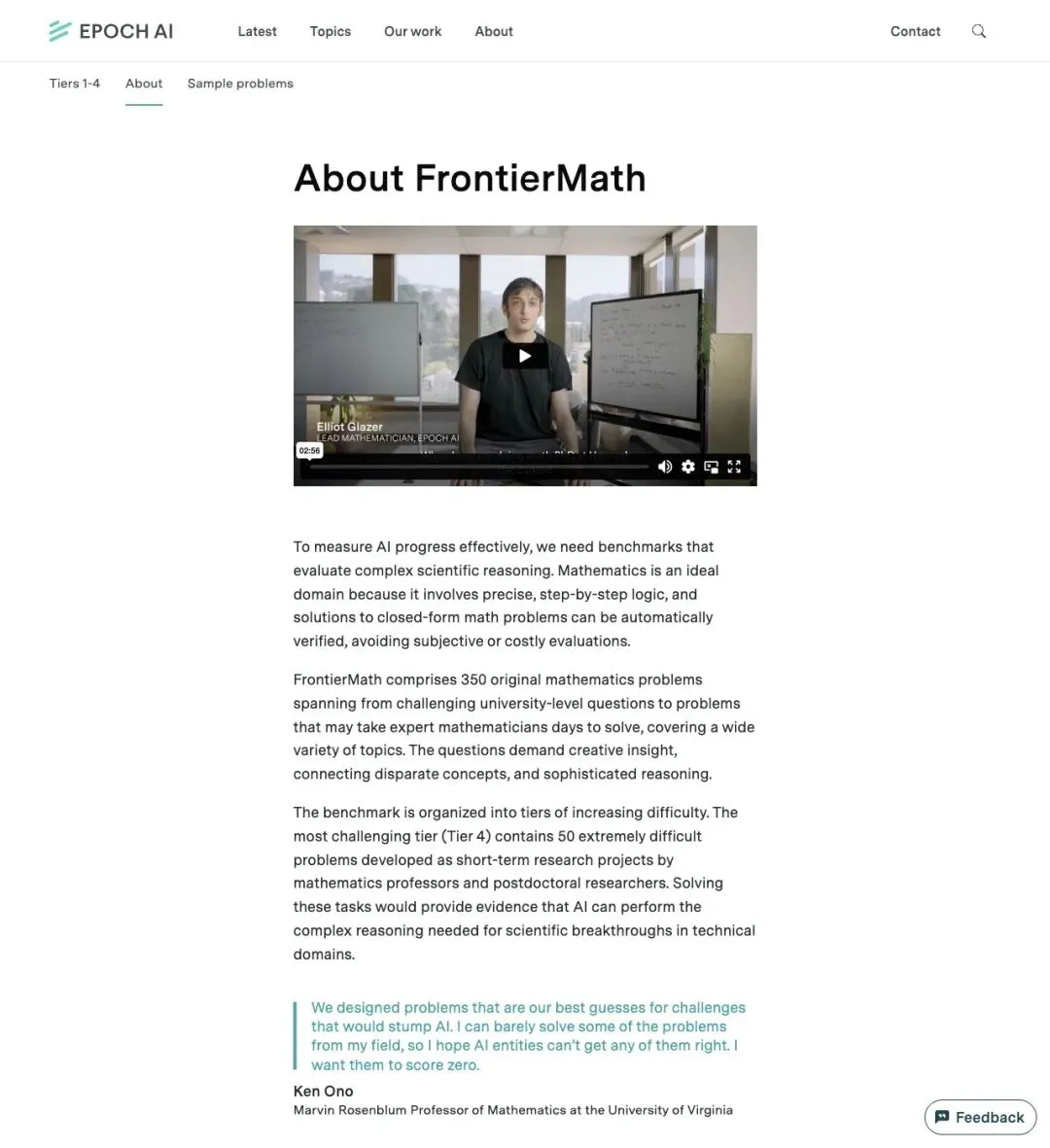
▲ FrontierMath About 页面:350 道原创题,分层递进,强调答案可验证
题目按难度分为四个层级。Tier 1-3覆盖本科到博士后早期难度,Tier 4最凶残——50 道极难题,全部由数学教授和博士后研究者以「短期研究项目」的形式开发。
官方还特别强调了三个特征:题目原创(novel)、未公开(unpublished)、答案可验证且难以猜测(verifiable, hard-to-guess answers)。
正因为这样的定位,FrontierMath 一度成为观察 GPT、Claude、Gemini 等前沿模型数学推理能力的核心坐标之一。各家模型在这套题上的得分,直接影响着业界对其推理能力的判断。
现在问题来了:如果题目本身有致命错误,过去的得分还能信吗?
「难解」和「难验」只隔一层纸
社区的反应很有意思。
X 用户 @deburdened 用一句英文精准概括了这件事的核心矛盾:
"hard-to-solve becomes hard-to-verify."
难以求解的题目,同时也难以验证。
这恰恰戳中了高难 benchmark 的结构性弱点。当题目难到「专家可能花数天解决」的程度,出题、验证、参考答案审核的成本也会水涨船高。题目越难,审错的概率越高;审错了,模型评分就跟着失真。
@simobis23 更直接,把整件事叫做「human hallucination benchmark」——人类自己出的题还自己弄错了,这和 AI 幻觉有什么区别?
也有更建设性的声音。@LechMazur 提出,也许标准需要转向 formalized theorems(形式化定理),也就是用 Lean 等形式化证明语言来写题目,让机器可以自动验证题目和答案的正确性,从源头堵住人工出错的可能。
@JasonRute 则追问了一个细节:「约三分之一」的分母到底是什么?是已解的题?未解的题?还是所有题?——Epoch 的后续报告需要回答这些问题。
而 @krasmanalderey 的评论带着一种黑色幽默:「AI 能发现 benchmark 里的错误,这说明它确实开始变强了。」
OpenAI 的影子:谁出的题、谁能看到答案?
这件事还有一个绕不过去的背景:FrontierMath 和 OpenAI 的关系。
2025 年 1 月,Epoch AI 曾专门发了一篇澄清博客,披露了一个关键事实:
"OpenAI commissioned Epoch AI to produce 300 advanced math problems for AI evaluation that form the core of the FrontierMath benchmark."
「OpenAI 委托 Epoch AI 制作了 300 道高级数学题,构成 FrontierMath 的核心。」
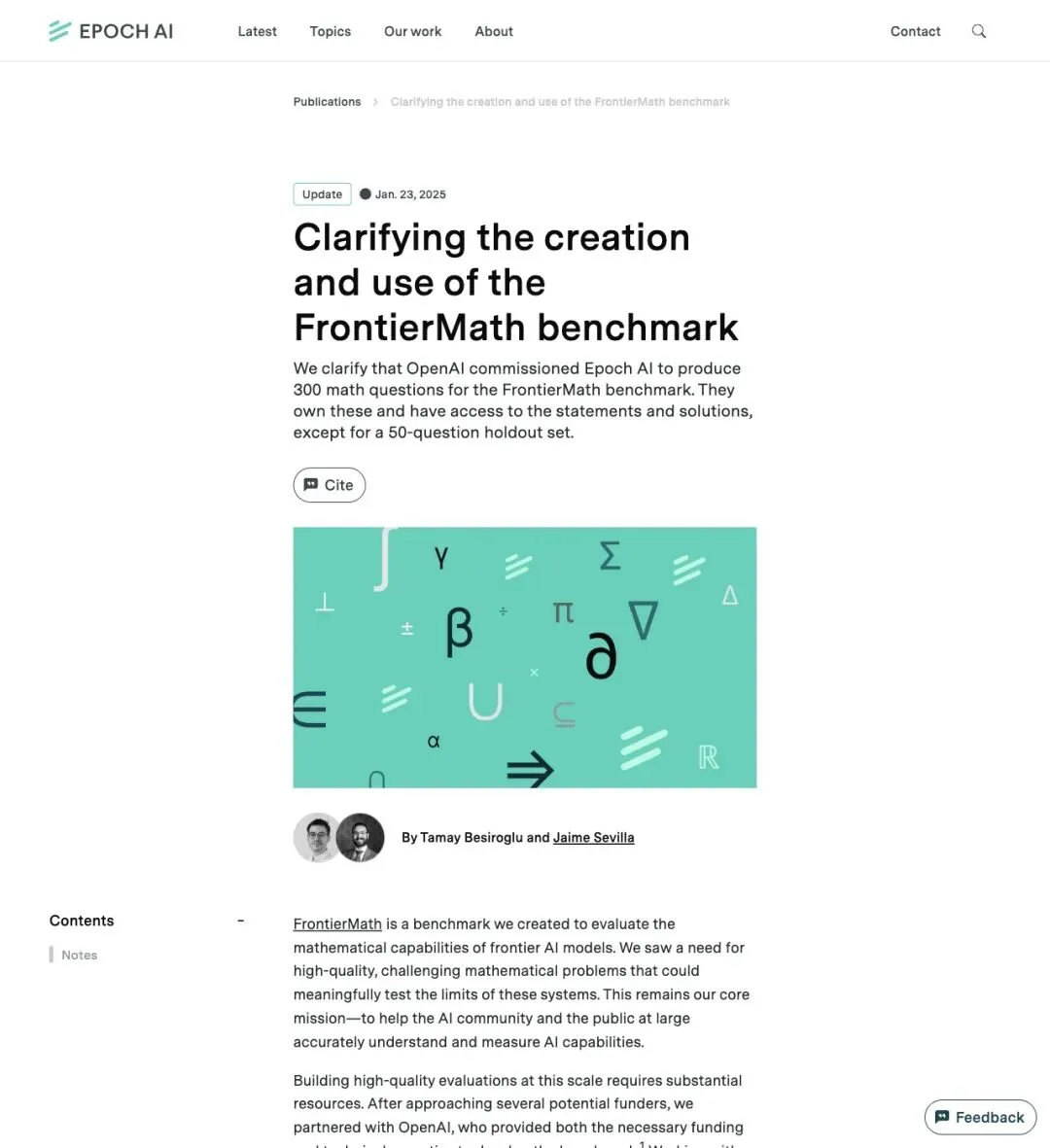
▲ Epoch 2025 年澄清博客:OpenAI 委托并拥有 FrontierMath 核心 300 题
更关键的是:OpenAI 拥有这些题目的所有权,并能访问题目和答案,唯一的例外是一个 50 题的 holdout set。
这次澄清的背景是,TechCrunch 在 2025 年 1 月曾报道,Epoch AI 因 OpenAI 资金来源披露时机问题遭到社区批评——部分 FrontierMath 的题目贡献者此前并不知道项目背后有 OpenAI 的资金支持。
现在「约三分之一 fatal errors」的公告一出,这些治理问题又被推回台前:
委托方能访问题目和答案,评测的独立性如何保证? 错误发现后,修正流程是否对外透明? 旧的评测结果如何标注、如何追溯?
要强调的是:OpenAI 的委托关系和当前的题目错误之间,目前没有任何因果证据。但治理透明度和评测公信力的讨论,会因为这次事件持续发酵。
模型排行榜怎么办?
回到最直接的影响:过去在 FrontierMath 上跑出的模型成绩,面临重新计算。
Epoch 的措辞是「release updated scores on a corrected dataset」——在修正数据集上发布更新成绩。注意,官方没有说「统一下调」或「全部作废」。
实际影响可能比想象的复杂:
如果某道错题的参考答案本身有误,而某个模型恰好「答对了错误答案」,修正后这道题的得分可能反而会变; 如果某些题因为题目陈述不完整导致多解,不同模型可能受到不同方向的影响; 在 Epoch 没有公布 fatal errors 的具体分类之前,谁涨谁跌都只是猜测。
唯一确定的是:在修正数据集发布之前,FrontierMath 当前排行榜上的所有成绩都带着一个问号。
最难的评测,也需要被评测
这件事最值得关注的,或许不只是某个 benchmark 出了错。
FrontierMath 的官方定位里反复强调「answers can be automatically verified」——答案可以自动验证。这是它区别于主观评测的核心卖点。但现在的情况是:答案的验证本身需要被验证,而且最先发现问题的还是 AI。
这提出了一个 AI 评测领域的深层问题:当 benchmark 的难度持续攀升,谁来保证 benchmark 本身的质量?
传统做法是同行评审、多人交叉验证。但当题目难到研究级别,能做审核的人本身就是稀缺资源。AI 辅助审查可能成为未来的标配——但最终的判断权,仍然要回到人类专家手里。
Epoch 在这件事上的处理方式值得观察:公开承认问题、明确后续动作(人工审查 + 修正数据集 + 重发成绩),没有选择悄悄改完当无事发生。
AI 评测正在进入一个新阶段:benchmark 的开发和维护,本身就需要严格的质量审计流程。越难的题目,越需要形式化验证、多重审核和透明的纠错机制。FrontierMath 的这次风波,给整个行业提了一个及时的醒。
— END —
