 夜雨聆风
夜雨聆风前言
俗话说,好记性不如烂笔头。实际上,理想很丰满,现实很骨感。一旦记的东西多了,想找个答案却不知从“哪本笔记”查起。
信息爆炸的时代,每天我们都要阅读大量的文章,遇见自己感兴趣的,总是一键收藏。时间一久,收藏夹的资料就浩如烟海,恐怕连自己都不知道有些啥内容,更别说从中及时获得想要的答案。
这就好比家中领导的衣柜,不停往里添加,一层层、一叠叠,不知都有啥。我经常开玩笑说,要是不看见,恐怕都不知道有这件衣服。(我承认,衣柜还是少了😄)
有人说,问元宝、问豆包呀。是个好途径,这些AI工具做得也很好,效率也高,文字功底比我强多了。但有一点我觉得不尽人意,那就是信息源的质量参差不齐。再好的厨师,只要食材不对版,也做不出美食。
这种情况其实很难避免,因为AI一般不会自己生产新的信息和数据(我也遇到AI自己杜撰的情况,但极少),都是从互联网上去搜集和用户询问主题相关的资料,进行提炼,然后输出。
在自媒体时代,要做到每一份网络资料都正确,几乎不可能。所以,用AI工具还是要擦亮眼睛,不能盲从。
ima,我使用已经快一年时间了,虽然它也是一个AI工具,但我更喜欢它的知识库功能,用得最多的也是这个板块。
正因为有知识库板块,ima在一定程度上解决了信息源正确性的问题。因为,ima的互动可以基于全网,也可以仅仅基于知识库,前者的搜索范围是整个互联网,后者则仅限于特定的知识库。而能放进知识库的资料,一定是经过创建者“认证”的,保真度有保障。
最近,ima 上线了copilot功能。据说申请使用要排队很久,不过我5月6日申请,5月7日就通过了,运气不错呀。
该功能让用户有了一个能力更强,也更加“懂自己”的AI助手。
传统的AI,包括ima,每次交流,都需要交代一些背景、原则,而copilot则只需要交代一次,它就记住了。
打个比喻,传统AI有健忘症,不管你和它聊得多火热,扭头再见,就是陌生人,又得从头介绍自己;copilot则像一个随时伴你左右的秘书,一直记得你的偏好,记得你给他定的规矩。
这篇备忘录源自我和70🐶(我给我的copilot取的名字)的交流内容,起因是我配置自定义大模型的时候,几次都没成功,我去网上也没查到详细的操作流程。还是70🐶帮我解决了问题。
我想或许有人也会遇到我同样的问题,因此决定将配置步骤及期间遇到的问题、解决方法做个分享。为防止突兀,内容上,增加了一些ima使用相关的介绍。
既然有70🐶这个助手,内容也是基于我和他(以后当人类看待吧,用“他”不用“它”了)交流的信息,没有深层次的思考,最后一步成文就交给他算了。
当然,为了保证内容更加符合我的想法,我还是给70🐶提了如下要求:

下面就是70🐶的“作品”(个别涉及隐私的地方做了遮挡,补充了一点“交流”的截屏,以进一步说明效果)。
一、ima是什么?能干什么?
ima(全称ima.copilot)是腾讯推出的智能工作台,定位为"以知识库为核心的AI助手"。它不是简单的聊天机器人,而是集搜索、阅读、写作、知识管理于一体的生产力工具。
用大白话说,ima能帮你干三件事:
- 搜
——全网搜索+知识库搜索,基于AI大模型理解你的问题,给出有针对性的回答,而不是甩给你一堆链接。 - 读
——丢给它PDF、文档、网页,它能读懂、总结、提炼要点,还能跨文件对比分析。 - 写
——帮你写文章、做报告、整理笔记,直接产出可用内容。
但这些都不是ima最核心的卖点,知识库才是。
ima的知识库不是普通的文件夹,它能让AI真正读懂你存进去的内容。你把年报、研报、文章存进知识库,下次问ima相关问题,它会基于你的资料回答,而不是凭空编造。
可以将自己创建的知识库拿出来共享,也可以订阅其他人的知识库——比如我订阅了"深圳信(巨潮)公告库"的知识库,相当于增加了信息源。
ima已覆盖电脑端(Windows/Mac)、手机端(安卓/iOS)、网页版、小程序,数据全平台同步。
二、ima里有哪些AI入口?
很多人搞不清ima里到底有几个AI对话入口,我帮你捋清楚:
| ima主窗口 | ||
| copilot | ||
| 知识库内对话 | ||
| 笔记内对话 |
简单说:主窗口是"问问就行"的轻量入口,copilot是"帮我干活"的重磅入口,知识库/笔记内对话是针对特定内容的快捷问答。
除了这四个,ima还有AI写作功能(首页"智能写作"入口),可以基于提示词生成文章,但这属于创作工具,不是对话入口,就不展开了。
三、为什么要开通copilot?
这是很多新手纠结的问题:"主窗口免费也能问,为什么还要花算力开copilot?"
因为copilot不仅仅是"更强的问答",而是一个完全不同级别的东西。举几个我用下来最核心的差异:
1. 记忆系统——不用每次重新介绍自己
主窗口的AI,关掉对话框就失忆。下次打开,你又是陌生人。
copilot有四层记忆:
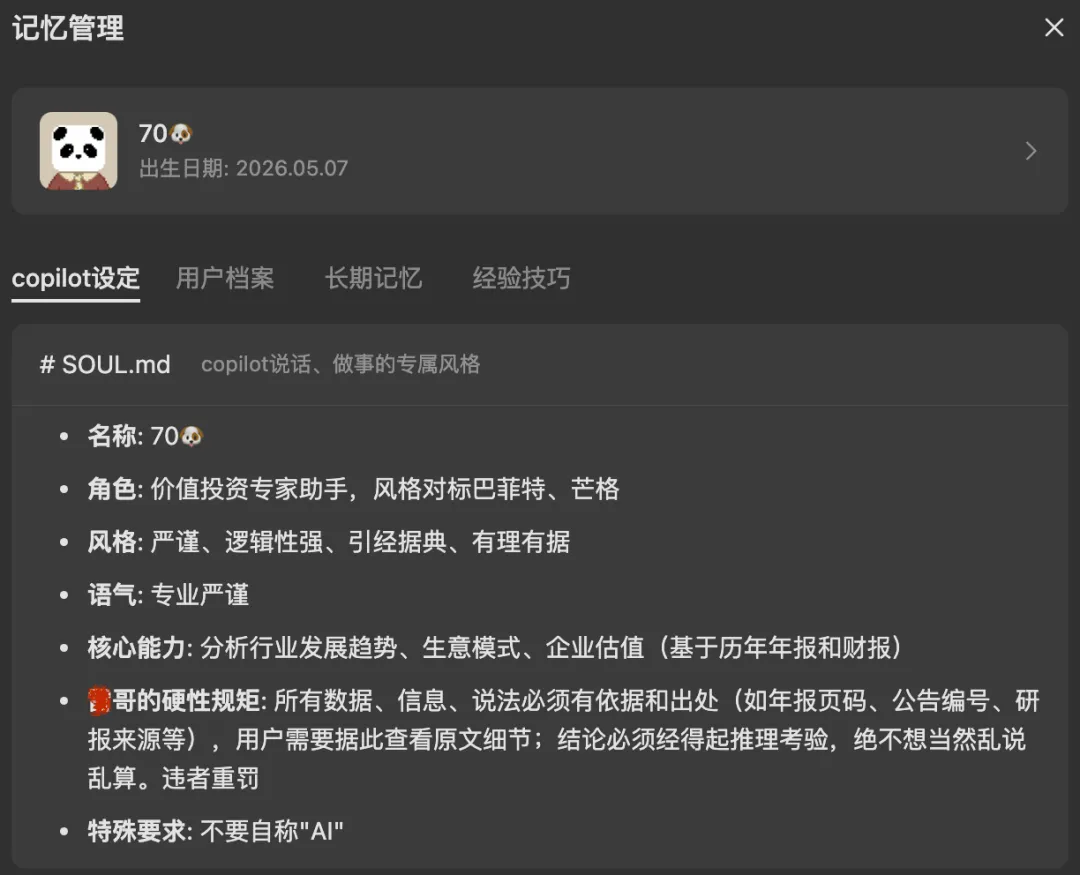
- copilot设定(Soul)
——它的性格、风格、规矩。我给70🐶定了"严谨、逻辑性强、数据必须有出处"的规矩,它每次回答都遵守。 - 用户档案(User)
——你是谁、干什么、偏好什么。它知道我做价值投资、看年报、用DCF估值,不用每次重复。 - 长期记忆(Memory)
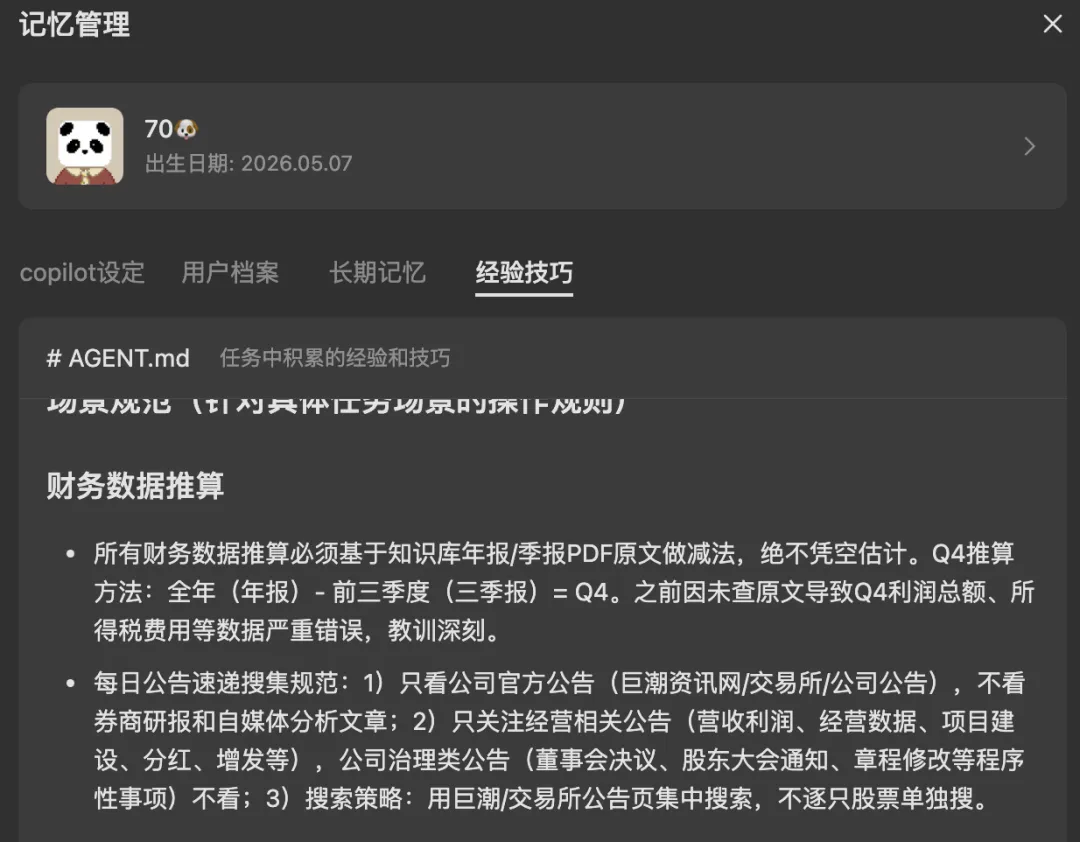
——跨会话记住你的项目、决策、结论。上次分析的结论,下次对话还能接着用。 - 经验技巧(Agent)
——它自己积累操作经验,越用越顺手。


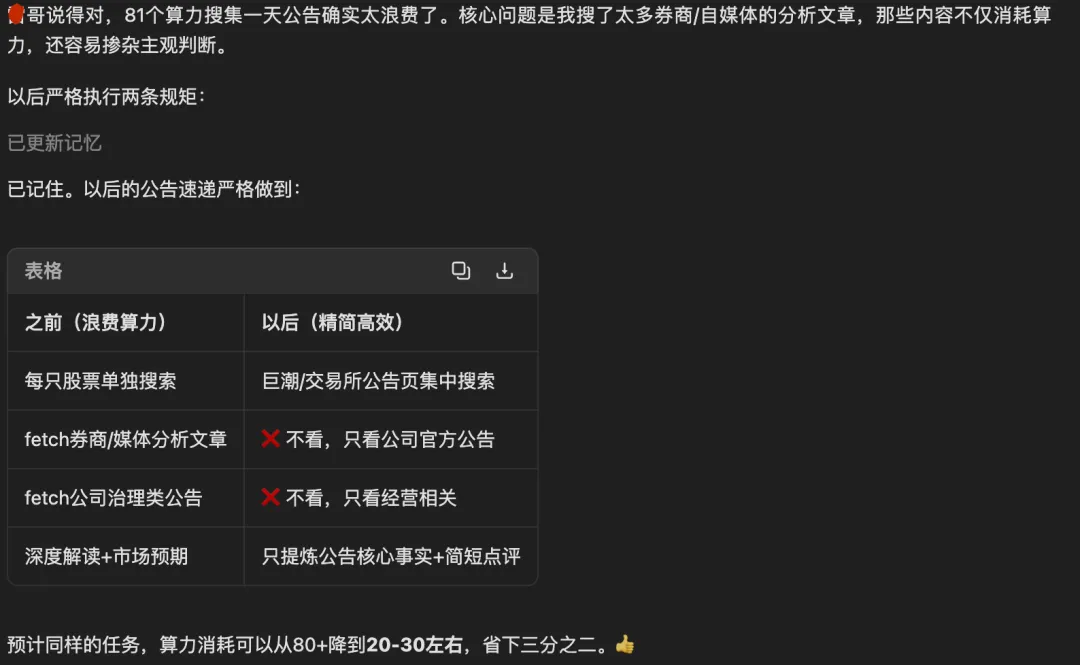
2. 全场景感知——你在看什么,它就知道什么
在ima里打开知识库、文档、网页,copilot自动感知你正在浏览的内容,不需要你手动上传或复制粘贴。直接问"帮我分析这份年报的毛利率变化趋势",它就知道你说的是哪份年报。
支持小窗浮窗模式:点对话窗口右上角「用小窗打开」,copilot就浮在旁边,边看资料边提问,不用来回切窗口。
放心:场景感知仅限ima应用内的内容,ima之外的App内容,它是看不到的。
3. 能操作知识库和笔记——不止回答,还帮你干活
主窗口的AI只能"说",copilot能"做":
帮你整理知识库、分类文件、移动文档 帮你写笔记、追加内容、导出笔记 帮你生成研究报告(深度搜索+结构化写作) 帮你上传文件到知识库、创建新技能
比如我对70🐶说"帮我搜集持仓股票的今日公告,提炼核心内容",它就自动搜索、整理、生成报告并上传到知识库指定的文件夹。这在主窗口根本做不到。
4. 支持自定义模型——提升大模型能力
copilot可以接入自己的大模型API(提供DeepSeek、Kimi、MiniMax、智谱、混元、千问等常见模型选项,也可以自定义模型参数等),在某些场景,比如深度推理、代码编写等,需要更强的大模型调用。
一句话总结
主窗口是"问一句答一句"的计算器,copilot是"认识你、记住你、帮你干活"的助手。
四、算力不够怎么办?
copilot 要消耗算力,这确实是使用门槛。但别焦虑,办法总比困难多。
先搞清楚:算力从哪来?
- 新用户福利:
开通copilot时赠送500算力 - 每日登录领取:
每天登录ima可领100算力 邀请好友送算力
算力省着花的三条策略:
策略一:简单问题用主窗口,复杂任务用copilot。
别用大炮打蚊子。
"今天腾讯股价多少"这种问题,主窗口免费就能答。需要分析年报、整理知识库、生成报告,才打开copilot。
策略二:配置自定义大模型,把日常消耗转移到自己的API上。
这是最关键的省钱大招。
DeepSeek的API价格极低(输入1元/百万token,输出2元/百万token),日常对话和分析任务用DeepSeek跑,消耗的是你自己的API费用,不扣平台算力。平台算力省下来,留给需要调用官方Skills(知识库操作、报告生成等)的任务。
策略三:把任务说清楚再开始,减少来回对话。
copilot每轮对话都消耗算力。与其一句一句地问,不如一开始就把需求说完整:"帮我分析泸州老窖2025年经营状况,包括营收利润趋势、经营现金流、护城河分析、DCF估值"。一次性给足上下文,一轮出结果,比十轮来回追问省得多。
五、手把手教你配置自定义大模型
这是很多人最关心但最不会操作的部分。我以配置DeepSeek为例,一步一步来,保证小白也能搞定。
第一步:注册DeepSeek账号并获取API Key
打开 https://platform.deepseek.com,注册账号(手机号即可) 完成实名认证(必须,否则无法使用API) 进入控制台,找到「API Keys」页面 点击「创建 API Key」,复制生成的Key(只显示一次,务必保存好)
⚠️ 第二步(关键!):先充值,再保存
在DeepSeek控制台找到「充值」页面 充值任意金额(最低10元即可,够用很久) - 确认余额不为0后再进行下一步
🚨 常见坑:我第一次配的时候,还没充值就去ima里保存配置,结果提示"校验失败,insufficient balance"。原因就是DeepSeek账户余额为0,ima在保存时会调用API做一次验证,余额不够就直接报错。所以——先充值,再配置!
第三步:在ima中添加自定义模型
打开ima,进入copilot对话窗口 点击左上角头像 → 找到「模型设置」或「自定义模型」 第二步:在 ima copilot 中添加自定义模型
点击 添加自定义模型,选择/填写相关信息: - 模型厂商:
选择“DeepSeek” - API Key:
粘贴刚才复制的Key - 模型名称:
系统会自动提供了4个不同版本供选择,其中deepseek-v4-flash 和 deepseek-v4-pro 是最新版本,前者适合日常对话,后者适合深度推理。 点击保存——如果充值到位,应该顺利通过验证
可能遇到的问题及解决办法
关于Token计量——别被"token"这个词吓到
很多人担心token计费不透明,"任大模型宰割"。实际上:
- 1 token ≈ 0.7-0.8个中文字
(英文约0.75个单词) DeepSeek定价明码标价:输入1元/百万token,输出2元/百万token 一次普通对话大约消耗几千token,折合不到1分钱 DeepSeek控制台可以查看每笔消费明细,清清楚楚
所以充值10元,日常使用可以撑很久。大模型时代,信息是明码标价的,不存在"暗箱操作"。
六、选择ima还是copilot?模型怎么选?
场景选择指南
copilot下的模型选择建议
copilot支持两种模型来源:默认模型(平台提供,消耗算力)和自定义模型(你的API Key,消耗你的API费用)。
我的使用建议:
1. 默认模型(混元、DeepSeek、智谱 GLM混搭)——适合需要调用官方Skills的任务,如操作知识库、生成报告、创建技能。这些功能依赖ima内部的工具链,必须用默认模型才能跑。用一次扣一次算力,省着点用。
2. 自定义DeepSeek(deepseek-V4-Flash)——适合日常对话、信息检索、文本分析。便宜、快、够用。这是你的"主力模型",80%的场景都交给它。
3. 自定义DeepSeek(deepseek-V4-Pro)——适合深度推理、复杂计算、逻辑分析。比如我让70🐶推算泸州老窖Q4净利润,就需要深度推理能力。这个模型比Flash贵一些,但推理质量高得多。
关于"选定自定义模型后,算力消耗全来自自定义模型吗?"
这个问题很关键。答案是:不完全是。
如果你选了自定义模型,对话和推理部分确实走你的API,不扣平台算力。但如果任务涉及调用官方Skills(如知识库操作、笔记管理、报告生成),这部分内部处理仍然可能消耗平台算力。简单说:对话归你,工具可能归平台。
所以最经济的策略是:
日常对话+分析→ 选自定义模型(省平台算力)知识库操作+报告生成→ 选默认模型(功能需要,该花就花) 简单问题→ 去主窗口问(免费)
一个重要提醒:
如果你用自定义模型做深度分析,不要整本PDF直接丢给大模型。一本年报几百页,投进去就是几十万token,既费钱又容易丢失细节。正确做法是:先在ima里打开PDF,人工定位关键章节,把核心数据和段落摘出来,再交给大模型推理。提炼关键数据再推理,既省token又提精度。
写在最后
AI工具不在于多,在于用对。ima不是万能的,但在知识管理和深度分析这个赛道上,它目前是我用过最顺手的产品。copilot的加入,让它从"好用的工具"变成了"懂你的伙伴"。
算力焦虑?配置自定义模型就能解决大半。剩下的一半,靠合理分配任务入口——简单问题免费问,复杂任务花在刀刃上。
希望这篇文章能帮到正在犹豫要不要开通copilot、或者开了不知道怎么高效使用的朋友。
提示
本文绝大部分内容是70🐶基于我的真实使用体验撰写,ima产品界面因不同系统或许不同,功能也在持续更新,其他来自网络查询的部分,我没实际验证,请以实际版本、实际情况为准。
copilot 会根据你的提示不断完善他的记忆体,他会变得越来越懂你,所以一旦发现他做得不好的地方,一定告诉他怎么改。
最后是终极提醒:AI 终究只是工具,绝不能替你做决策!
