夜雨聆风
夜雨聆风今年5月13号,Anthropic 在 GitHub 上公开发布了一个叫 claude-for-legal 的项目:12个法律实践领域插件、80多个技能模块、5个自动化 Agent、20多个对接法律软件的连接器。
这不是某家法律科技公司的产品,是 Anthropic 自己写的。
名义上是给想用 Claude 构建法律工作流的人看的。但仔细读下去,你会感觉 Anthropic 是在对整个行业说一句话:法律 AI 应该是什么样的,这是我们的答案。
我花了一些时间把这个项目拆开来研究。有几个设计决策让我印象很深,不是因为技术有多复杂,而是背后的判断太清醒了。
文章最后也会附上安装方法。
先问来者何人,摸清底细再动手
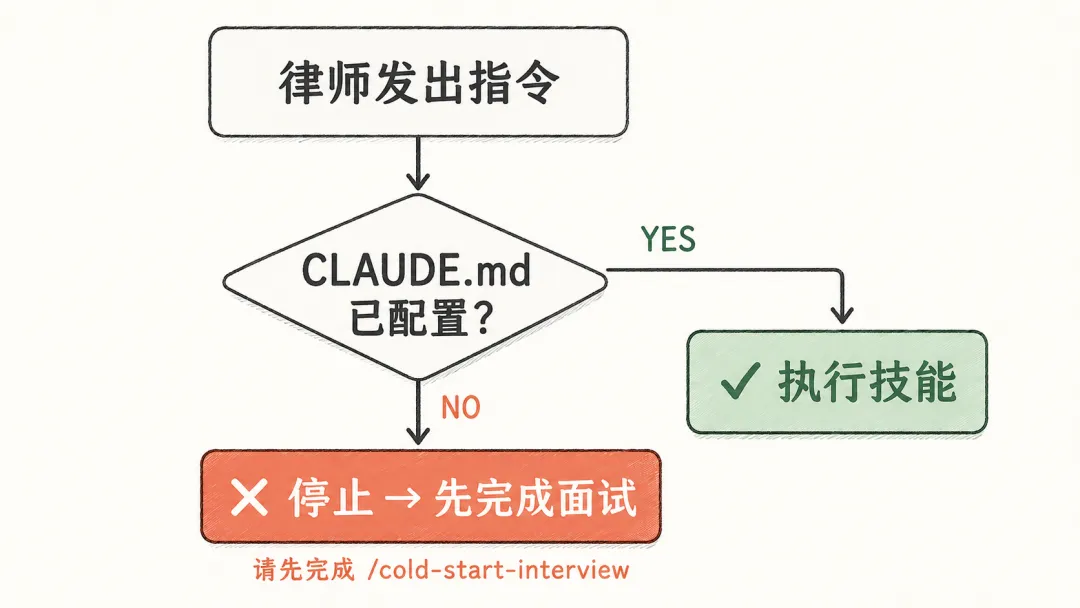
打开 claude-for-legal 里任何一个插件,第一步都不是直接干活,而是一个叫"冷启动面试"(cold-start interview)的环节。
面试问什么?你的执业领域、管辖范围、客户类型、风险偏好、常用文书格式、哪些情形需要升级处理……每个插件有自己的问题清单,回答完之后,信息会写进一个专属配置文件,之后所有技能调用都从这个文件里读取你的背景。
如果你还没完成冷启动,插件会直接拒绝工作。不是报错,是明说:先去做 /cold-start-interview,做完再来。
很多人可能觉得这多此一举。我第一反应也是:为什么不直接问呢?
但 Anthropic 在文档里把理由说得很清楚:"没有配置的法律 AI 输出是危险的——管辖错误、标准不一。"
这句话值得多想一想。我们平时遇到的 AI 法律助手,大多数是你说什么它就答什么,从不主动问你是在哪里执业、面对什么类型的法院、当事人是什么背景。它给出的答案,可能是美国法律框架下的,可能是通用教科书标准,可能和你实际处理的案件没有半点关系。
冷启动面试的本质,是强制在开始工作之前建立一个"我知道在为谁服务"的前提。没有这个前提,所有输出都是在赌运气。
但这个设计还道破了一件事,Anthropic 没有明说,但逻辑上清楚:法律人的专长,本来就只能是某一领域的顶尖专家。一个刑辩律师对劳动法的理解,和一个劳动法律师对刑法的理解,都不可能同时达到顶级水准。通用大模型没有这个限制,但它恰恰因此缺乏定向深度。冷启动面试做的事情,是把律师的专业边界告诉 AI,让 AI 在这个边界内深度配合,而不是在所有领域都浅尝辄止地给你一个"差不多"的答案。承认专长有边界,才能把边界以内的事情做到极致。
来源诚实,不知道就说不知道
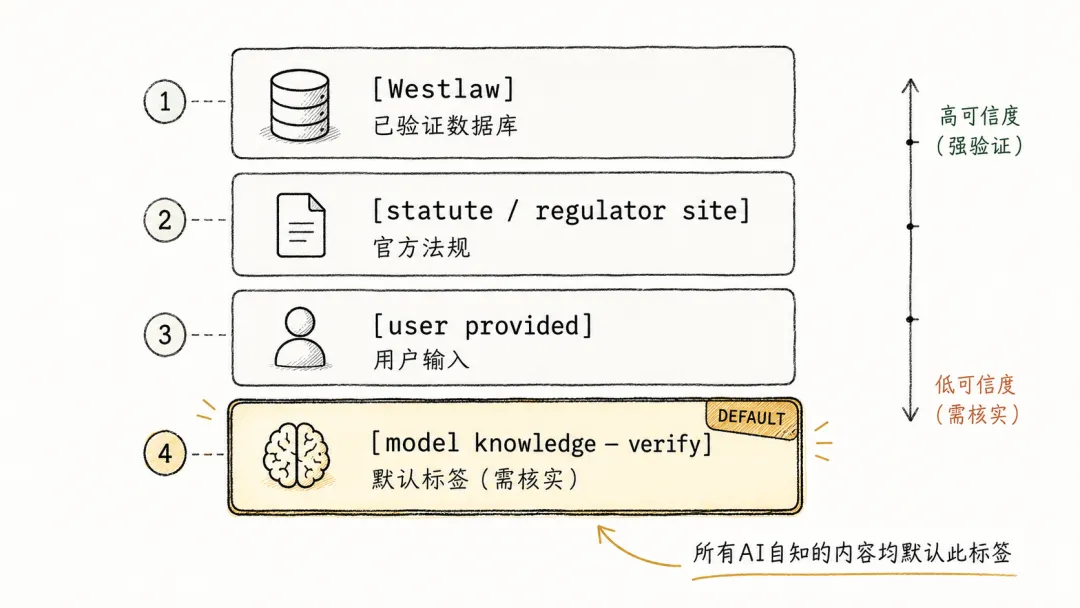
claude-for-legal 里有一套来源标注系统。每一条法律引用,都必须带标签:
从 Westlaw 或 CourtListener 这类数据库里检索到的,标 [Westlaw]或[CourtListener]从官方法规网站获取的,标 [statute / regulator site]用户自己粘贴进来的,标 [user provided]模型训练数据里的,标 [model knowledge — verify]
最后这个标签是默认标签。凡是 AI 自己"知道"的东西,只要没有经过外部数据源确认,一律打上"请核实"。
有一条规则写得很直接:标签描述的是来源,不是置信度。不允许因为"看起来对"就升级标签。
与标注系统配套的,是一套叫"三值响应"的机制。当某个技能执行到一半,发现缺信息了,它面临的不是"是否往下走"的二选一,而是三条路:补充并标记来源;停下来问用户;或者标注风险但不改变分析。
第三条值得单独说。就算 AI 知道自己引用的某条信息可能有问题,它也不会悄悄删掉这条引用,而是保留并明确标注风险。文档里有一句话说得很准:沉默等于误导,已知的怀疑不标注等于确信。
这对中国律师来说应该有共鸣。AI 生成的法律文书里最危险的不是明显的错误,是那些"看起来没问题"的引用——条号对的,内容不对;法律对的,施行时间搞错了;司法解释存在,但适用范围不对。这些错误之所以能蒙混过关,正是因为 AI 选择了沉默而不是标注。
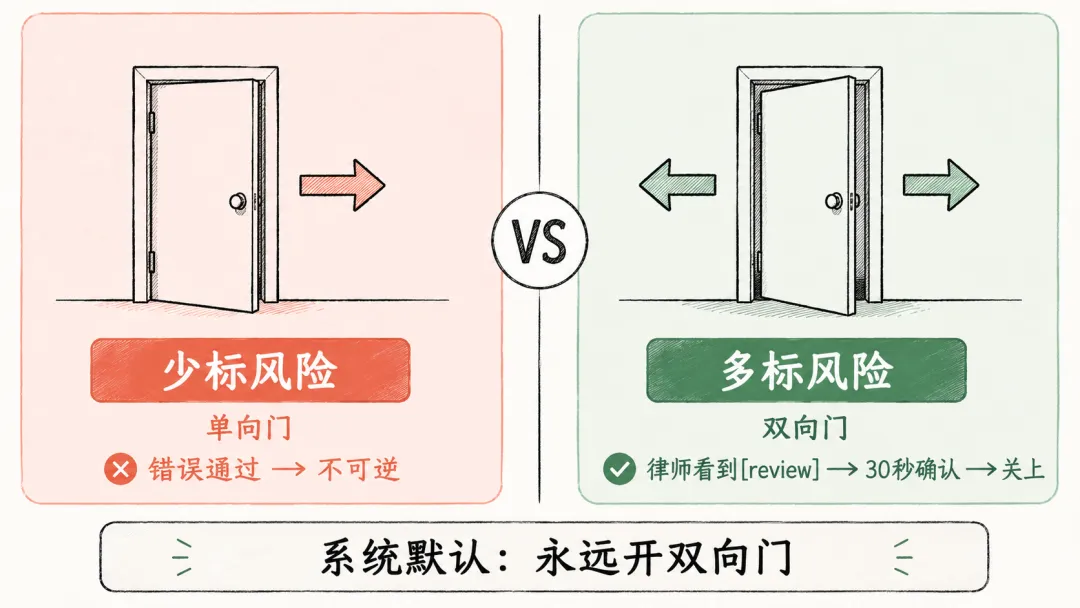
宁可多标,不可少标
这是 claude-for-legal 里我觉得最值得学的一个判断。
项目文档里有一段话,用了一个很直白的比喻。
少标风险是一扇单向门:律师看不到标注,就不会去核实,错误通过了就通过了。
多标风险是一扇双向门:律师看到了 [review],花30秒确认没问题,然后关上这扇门。
两者的代价不对等。少标一次风险,可能是不可逆的;多标一次风险,顶多让律师多看一眼。所以系统的默认选择是:永远开双向门。
这条规则还有一个延伸。上游技能标记的风险,不能在下游静默降级。如果某个分析步骤标出了一个红色风险点,后续的汇总报告不能把它自动降成黄色,除非明确说明为什么降级。
目前很多法律AI产品为了让输出"看起来更有用",会主动过滤掉不确定性表述,删掉"可能"、"有待核实"之类的标注,让答案显得更干净、更确定。这是在帮律师,还是在给律师挖坑?
Anthropic 的答案是:那是坑,不要挖。
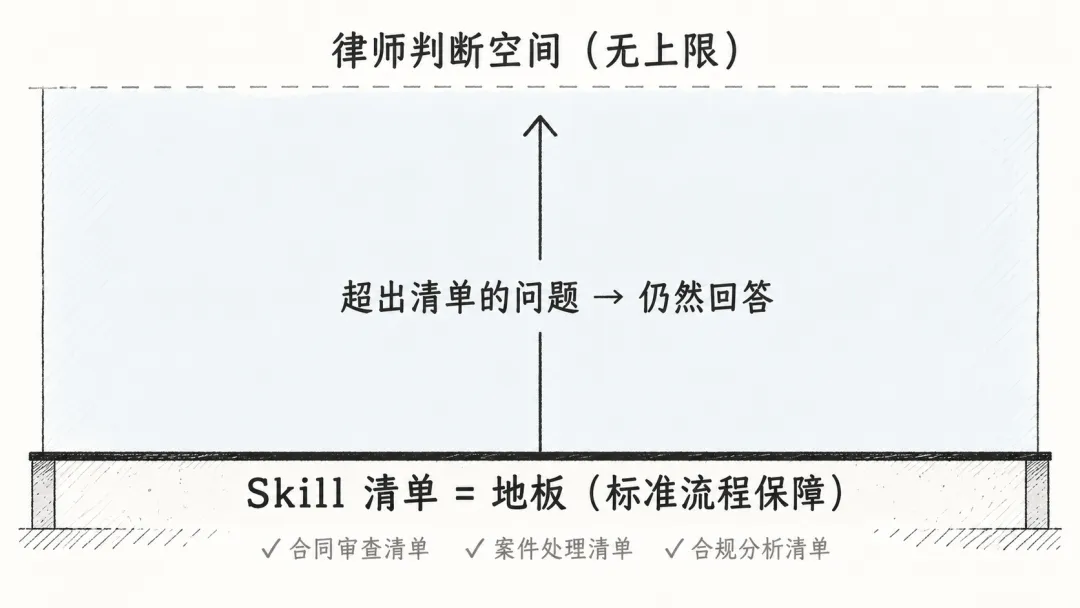
清单是地板,不是天花板
最后一个原则,是关于 Skill 自身边界的设计。
claude-for-legal 里每个插件都带着自己的操作清单:审查合同有清单,处理案件有清单,做合规分析有清单。但项目里有一条明确写入的设计原则:
这句"比裸 Claude 更差"是很重的话。给 Claude 装上一个法律插件,反而让它变笨了,这才是最坏的结果,比没有插件还糟糕。
所以 Skill 的存在是为了补充,不是为了约束。清单保证了标准流程的覆盖,但当用户提出一个清单以外的问题,正确行为是直接回答,而不是说"这不在我的功能范围内"。
用中国律师的语境翻译一下:你给 Claude 配置了一个处理刑事案件的工作流,但今天客户临时问了一个关于民事赔偿的问题。AI 正确的做法是回答,而不是说"我是刑事专用助手,这个问题不在我的范围里"。那种回答是工具在管人,不是工具在帮人。
这套设计哲学说的是什么
四条原则,说的其实是同一件事:律师的判断权不能被 AI 替代掉。
先建立上下文,是为了让输出和律师的实际处境匹配,不是给一个通用答案让律师自己去套。来源诚实和多标原则,是为了让律师看到真实的不确定性。清单是地板,是为了不让工具反过来约束律师的思维。
claude-for-legal 是美国语境下的产品,很多具体功能直接照搬用不上。但它背后这套逻辑,和律师在用 AI 工具时真正担心的事是对得上的:我能信任这个输出吗?这个工具是在帮我还是在悄悄替我做决定?
这些问题的答案,要从工具的设计哲学里找,不是从功能列表里找。
Anthropic 把他们的答案公开写出来了。能不能用是一回事,值不值得看是另一回事,至少我觉得值得。
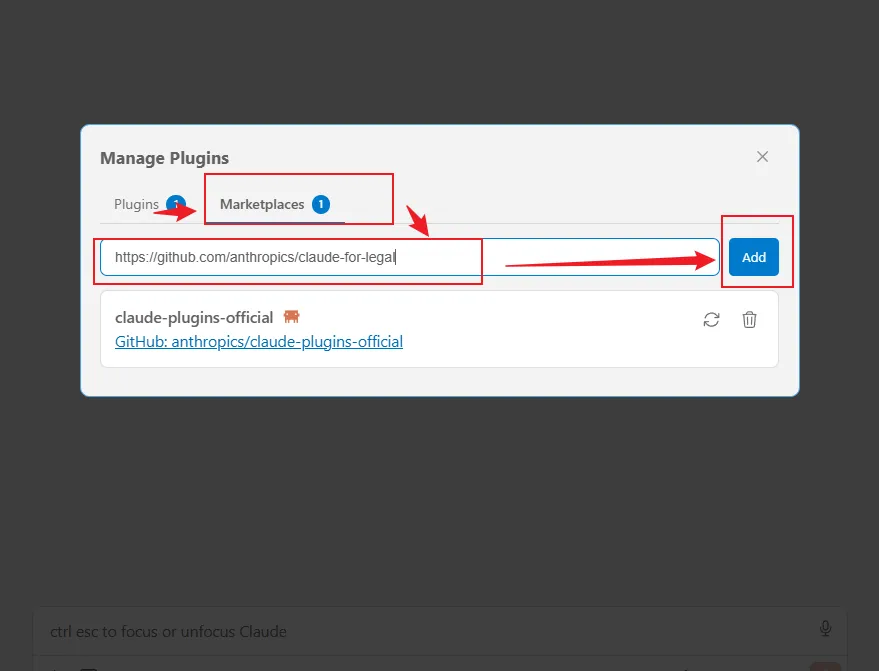
附安装方法
方法一:直接给Claude说帮我安装https://github.com/anthropics/claude-for-legal.git
方法二:
输入/plugin回车
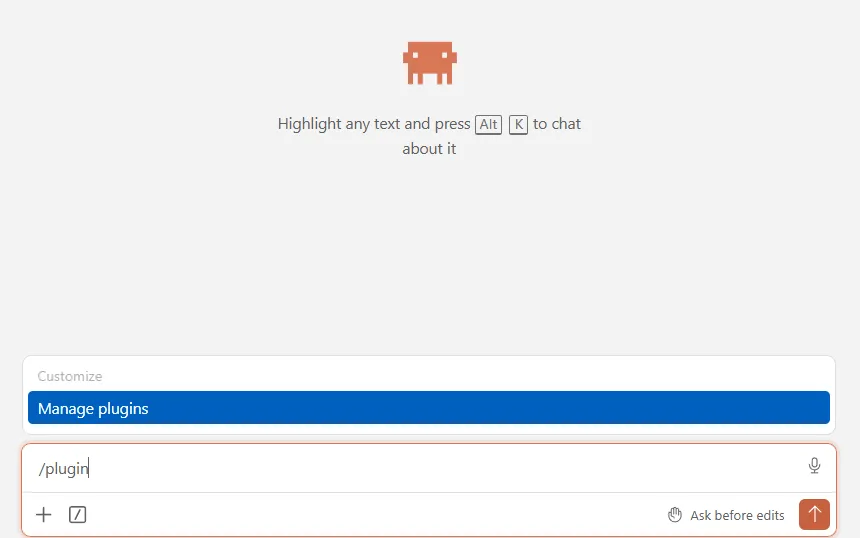
在输入框加入https://github.com/anthropics/claude-for-legal.git