 夜雨聆风
夜雨聆风明尼苏达大学最近发了篇论文,给当下最热的 Agentic EDA 浇了一盆冷水。
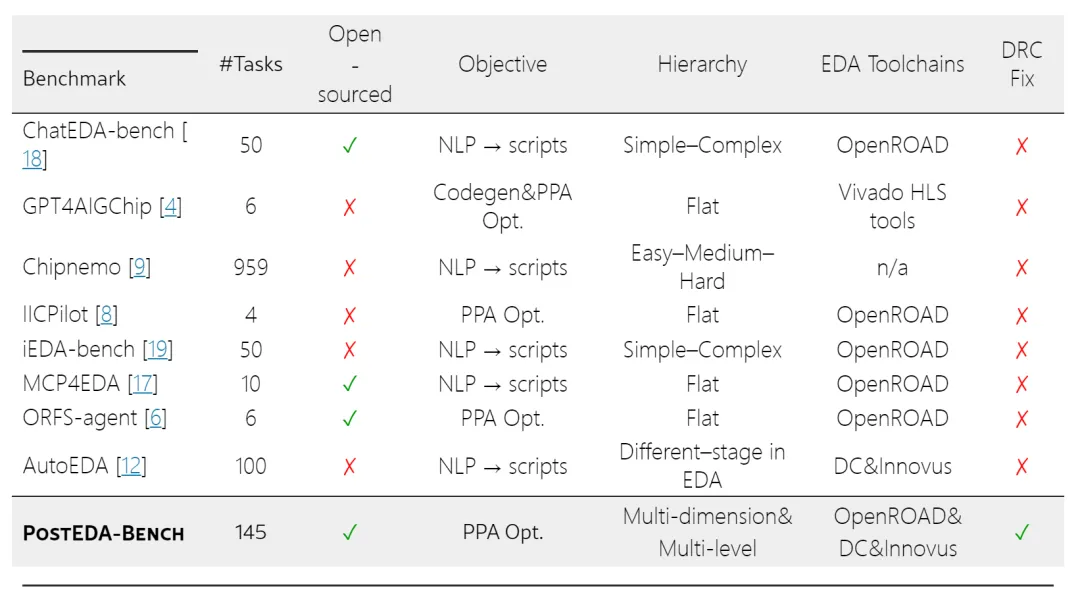
他们做了个叫 PostEDA-Bench 的基准测试,专门评估 LLM Agent 在芯片设计"最后一英里"的能力——修 DRC 违规、调 PPA 参数。结果不太好看:合成任务上 Agent 表现还行,一换到实际场景,成功率直接腰斩。多目标 PPA 优化更惨,最好的模型也就 20%。
这篇论文的价值不在于说"AI 不行",而在于它第一次给出了可量化的基线。之前大家都在喊 LLM 能改变芯片设计,但到底能改到什么程度,没人说得清。现在有数字了。
什么叫"最后一英里"?
芯片设计流程跑完自动布局布线,不会干净利落地吐出一个完美的 GDSII。实际情况是:sign-off DRC 还会残存一堆违规,PPA 指标也往往达不到目标。工程师得花大量时间手动迭代——改几何结构、调工具参数、重新跑流程,一遍一遍,直到签核通过。
这就是"最后一英里"。自动化走了 99%,剩下这 1% 最费人工、最耗时间。
LLM Agent 被看好,因为它们能理解工具文档、生成 TCL 脚本、分析错误日志。于是过去两年冒出来一堆工作:ChatEDA、AutoEDA、Chipnemo、iEDA-bench、MCP4EDA……
但问题是:这些 Agent 到底行不行?
PostEDA-Bench 做了什么?
明尼苏达大学给了个系统性答案。145 个任务,两个维度:
DRC-Bench:评估 Agent 修设计规则违规的能力。两条线——DRC-Essential 用合成场景测规则知识,DRC-Reasoning 用真实残存违规测几何推理。
PPA-Bench:评估 Agent 收敛 PPA 目标的能力。PPA-Mono 测单目标,PPA-Multi 测多目标权衡。
支持开源(OpenROAD)和商业(DC + Innovus)工具链,评估结果机器可检查。
结果有多难看?
合成任务和实际任务的落差,是论文最核心的发现。
DRC-Essential 上,最好的 Agent 成功率 85.50%。还行。但换到 DRC-Reasoning,最高只有 36.66%。
PPA 更夸张。PPA-Mono 最佳 64.56%,PPA-Multi 直接掉到 20.00%。
原因更值得琢磨:多目标 PPA 优化的瓶颈不是 Agent 不懂参数怎么调,而是它不会做权衡。多个模型在 PPA-Multi 上产生了负 NIS——为了优化一个指标,把其他约束搞得更差了。说白了,捡了芝麻丢了西瓜。
还有个好消息:给 Agent 加上视觉通道,让它能看到版图图像,对 DRC 任务从来没坏处,而且 consistently 提升成功率。纯文本模型最弱的场景,视觉增强带来的提升最大。
为什么合成和实际差这么多?
不奇怪。现有 EDA-LLM 基准几乎都是"文本到脚本"——给一段自然语言,让它生成 TCL 脚本。测的是 Agent 会不会说话,不是会不会做事。
PostEDA-Bench 的 DRC-Reasoning 不一样。给 Agent 的是真实跑完流程后的残存 GDS,违规是工具真实报出来的,不是人工标注的。Agent 得理解违规的几何含义、定位要修改的形状、执行编辑、重新跑 DRC、根据新结果继续迭代。这是闭环,不是开环的脚本生成。
合成任务像在考卷上做题,实际任务才是下车间。
"不会做权衡"是致命伤
多目标 PPA 只有 20% 成功率,比 DRC 修复还低。论文的分析很有意思:瓶颈不在参数知识,在权衡推理。
这恰恰是人类资深物理设计工程师最值钱的地方。新手知道某个参数会影响时序。资深工程师知道:调了之后时序会改善,但面积增加 3%,功耗增加 1.5%,对 setup 和 hold 的影响方向还相反——值不值得调,得看整个设计的约束优先级。
这种权衡需要对设计有整体理解,对各指标耦合关系有直觉。LLM Agent 离这个水平还有不小的距离。
这也是 IC Agent Hub 想做的事——让 Agent 不仅会执行单步操作,还能在设计流程里做更高层次的判断。结合行业知识库和工具链反馈,帮 Agent 建立对设计上下文的长期记忆,而不是每次都从零开始盲调。
视觉增强为什么管用?
DRC 本质上是几何问题。违规是形状之间的关系——间距不够、宽度不合规、通孔位置不对。纯文本模型只能通过坐标和规则描述来理解,相当于盲摸。给它看版图图像,等于给了它一双眼睛。
这指向一个趋势:多模态可能是 EDA Agent 的必经之路。芯片设计从 RTL 到版图,大量信息是视觉性的——原理图、时序图、版图热图、拥塞图。能看的 Agent,天然比只能读的更贴近工程师的工作方式。
Agentic EDA 现在什么段位?
拿自动驾驶做类比,大概还在 L2——辅助驾驶能用,复杂路况人还得接管。
看看这两年的进展:ChatEDA(TCAD'24)管 RTL 到 GDSII 全流程;AutoEDA(2025)基于微服务和 MCP 协议;Chipnemo(NVIDIA 2023)是芯片设计领域适配的 LLM;NVIDIA Marco 是多 Agent 协作框架;Cadence Agentic AI 号称能把设计周期缩短数月。
方向没错。但 36.66% 和 20.00% 说明,距离工业化可靠应用还有很长的路要走。
EDA 公司:窗口还开着
如果 Agent 在"最后一英里"确实只有这个水平,Synopsys、Cadence、Siemens EDA 三家巨头完全有时间把 AI 能力内化到工具链里。Cadence 已经在做了。
创业公司的机会在于:大厂 AI 集成速度一般不快,而开源社区(OpenROAD + PostEDA-Bench)提供了低门槛试验场。谁能先在某个细分场景把成功率从 36% 推到 80%,谁就拿到了入场券。
芯片设计公司:别急着裁人
有些管理者看到 LLM 能生成 EDA 脚本,就在盘算能不能用 Agent 替代初级物理设计工程师。数据给的答案是:至少目前还不行。
但 AI 不是没用。Agent 在单目标 PPA 上 64% 成功率,合成 DRC 修复 85%——这些场景已经可以当辅助工具用了。关键是把 Agent 放对位置:让它干擅长的事,复杂权衡交给资深工程师。
AI 社区:基线有了,方向也清了
PostEDA-Bench 最大的贡献是建了一个可复现、可量化、覆盖真实场景的评估基准。之前各论文各搞各的,任务不同、工具不同、评价标准不同,没法横向比。
现在有了统一标尺。论文指出的两个核心发现——合成与实际不对称、trade-off reasoning 是多目标瓶颈——直接标明了后续研究该攻什么山头。
写在最后
接下来盯三件事。
第一,多模态 Agent 在 EDA 的进展。视觉增强已经证明了价值,下一步会不会加入时序波形、拥塞热图、工艺角数据?多模态可能是突破 DRC-Reasoning 36% 天花板的关键。
第二,权衡推理能力的专项提升。这不是 EDA 独有的问题,是 Agent 通用短板。如果通用框架(ReAct、Proposer-Critic、ToT)能在多目标权衡上取得突破,对 EDA、对优化、对决策类任务都有溢出效应。
第三,工业级验证。PostEDA-Bench 目前用的是 ASAP7 工艺和公开 IP。真正的压力测试得在先进工艺(3nm、2nm)、大规模 SoC、真实项目约束下做。学术界和工业界的 Gap,往往这时候才会暴露。
PostEDA-Bench 不是一篇说"AI 在芯片设计上失败了"的论文。反过来,它是一个成熟信号——行业开始从"LLM 能不能做 EDA"的兴奋期,走向"到底能做到什么程度"的量化评估期。
36.66% 和 20.00% 不是终点,是起点。有了基线,才知道往哪追。
芯片设计的"最后一英里"可能是 LLM Agent 最硬核的挑战之一。但别忘了,难的事,才值得做。
作者:麒芯
参考来源:arXiv 2605.06936,SemiEngineering,NVIDIA Research
💬 加入 IC Agent 技术交流群
群里聚集了芯片设计工程师、IT/CAD 负责人和 AI+EDA 从业者,聊技术、聊工具、聊行业趋势。

👉 关注回复「加群」,拉你进群一起聊
👉 关注回复「合作」,如果你在做 AI+ 芯片/EDA 相关,欢迎来聊
后续会持续更新这个系列,关注不迷路。
