 夜雨聆风
夜雨聆风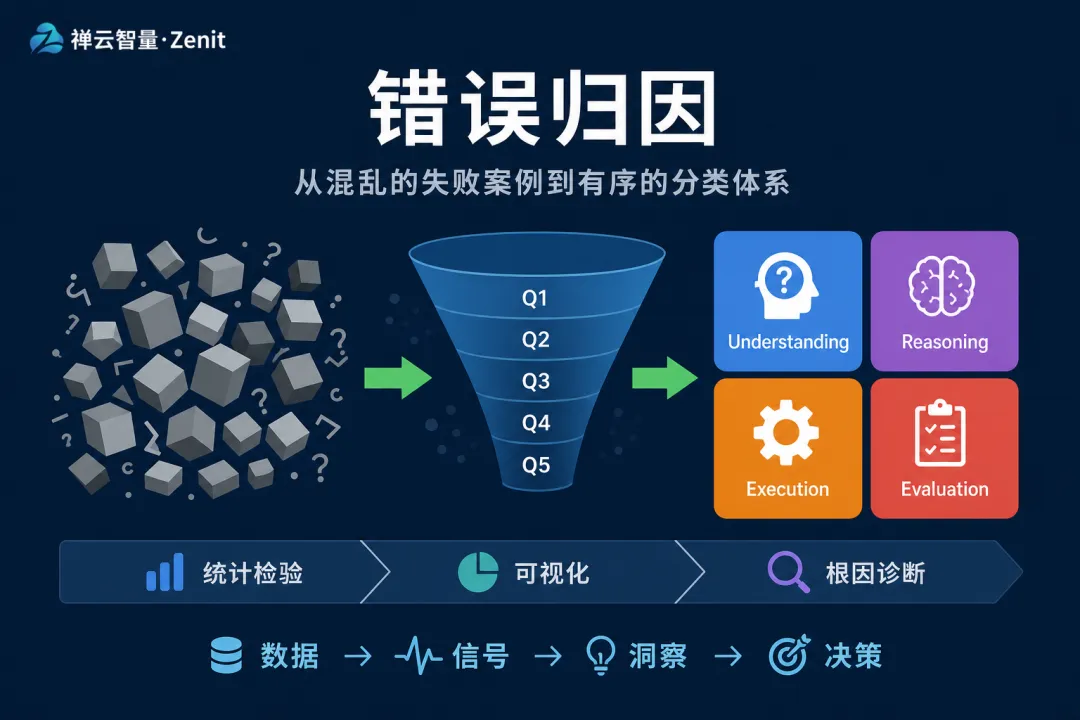
一、开篇:一个模型失败了,到底是谁的错?
在前一期,我们建立了实验系统——用数据告诉你「这个版本比上一个版本好多少」。
但这里浮出了一个更尖锐的问题:当版本对比发现新模型的表现下降了,或者某些场景表现不稳定,我们怎么知道责任在哪里?
是数据不够代表性?是模型架构的问题?是提示词设计缺陷?还是评测方法本身有偏差?
大多数团队的回答是:「我们也不知道,就是不好用。」
这一期,我们要解决的是错误归因——当评测发现了一个失败案例,我们如何系统地拆解这个失败背后的真实原因,从而做出精准的优化决策。
这是从「发现问题」升级到「理解问题」的转折点。也是决定你的评测系统能否真正驱动模型进化的关键。
二、问题定义:为什么我们总是在猜测
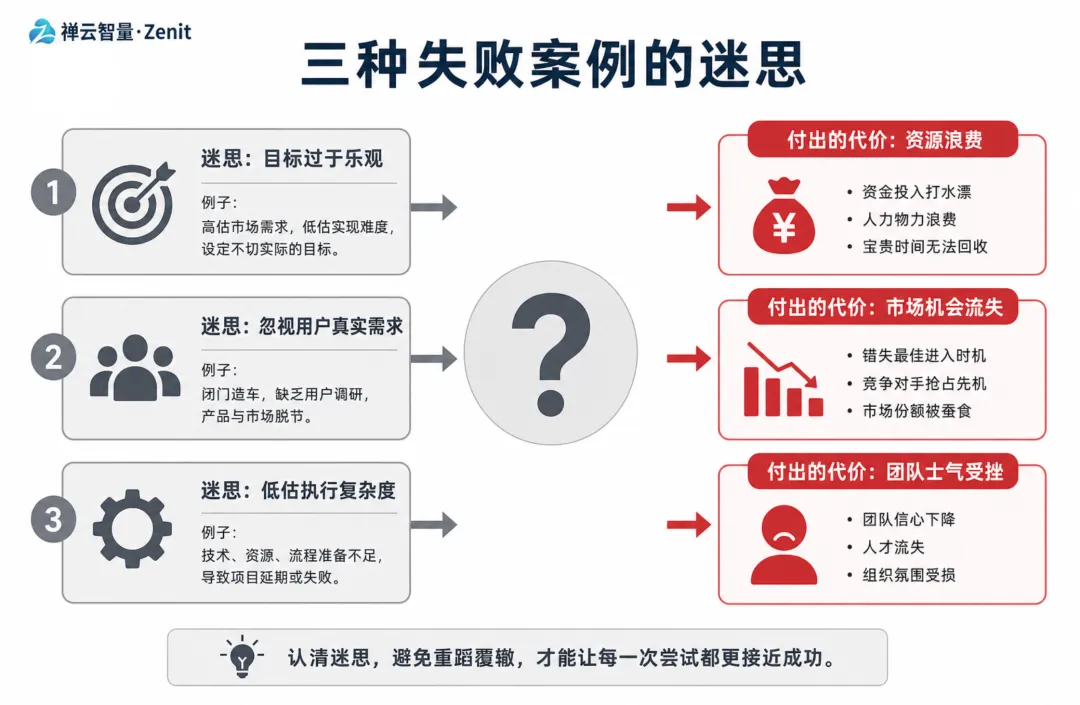
2.1 行业现状:三种"失败案例的迷思"
我们分析了 30+ 个 AI 团队的评测复盘记录,发现错误归因失效的常见情况:
❌ 现象1:只知道「错了」,不知道「怎么错的」 评测报告: - 问题识别:模型在"财务报表分析"上成功率只有 62% - 行动:「这个场景太难了,我们先放弃」 缺失的信息: - 62% 的失败中,有多少是理解问题失败? - 有多少是计算逻辑错误? - 有多少是格式输出错误? 真相:每种错误的修复方案完全不同 不分类就瞎优化,最后还是不行❌ 现象2:混淆了模型问题和评测问题 场景:医学知识问答 评测发现:模型回答准确率 55% 团队反应:「模型不行,需要换基座」 三个月后才发现: - 问题不在模型,而在评测标准 - 医学问答的正确答案不唯一 - 用 BLEU 这种字面匹配度量是错的 - 应该用医学专家打分,或者语义相似度 代价:浪费人力、丧失信心❌ 现象3:有了失败案例,但无法推广到其他模型 案例1:"Claude 在这道题失败了,是因为 XYZ 原因" 案例2:"GPT-4 在同样的题也失败了,原因完全不同" 结果:每个模型都要单独分析,无法形成系统性认知 问题:没有建立「错误分类体系」 同一种错误在不同模型上的表现和成因并不相同
2.2 根本原因:缺少错误分类的设计思维
大多数团队做错误分析的过程是这样的:
跑评测,发现失败案例
打开案例,读一遍内容
凭直觉说「可能是因为 XXX」
写个备忘录
下次遇到类似的,还是重复 1-4
为什么?因为没有一个清晰的错误分类框架。
在软件工程中,我们早已知道:
不同类型的 bug 需要不同的修复方式
没有分类的问题库最后一定变成"垃圾堆"
能否快速定位问题,取决于分类体系的粒度
而在 AI 评测中,这个原理被完全忽视了。
2.3 Zenit 的核心观点
错误归因 = 多维度的分类体系 + 精准的根因定位方法。
它要回答四个问题:
问题维度 | 具体问题 | 责任方 |
理解维度 | 模型是否正确理解了输入意图? | 模型 / 提示词设计 |
推理维度 | 模型的中间推理过程是否逻辑清晰? | 模型能力 / 上下文长度 |
执行维度 | 模型是否按预期的方式组织了输出? | 模型 / 输出约束 |
评测维度 | 评测标准是否能公正地衡量这个答案? | 评测指标 / 标注规则 |
三、方案拆解:构建错误分类体系
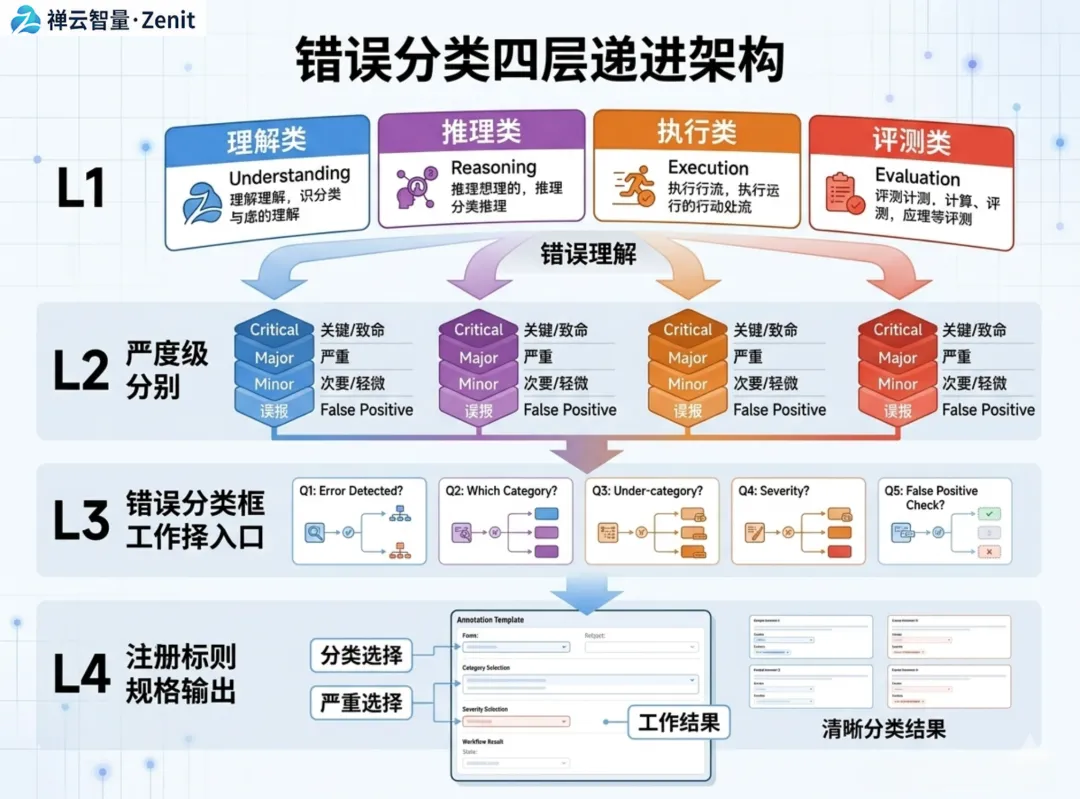
3.1 第一层:错误类型的标准分类
我们基于 1000+ 个实际失败案例,总结出了一套可复用的错误分类框架:
L1 - 错误大类(4类) ├── 理解类(Understanding Failure) │ └─ 模型未能正确提取题目意图或关键信息 │ ├── 推理类(Reasoning Failure) │ └─ 中间推理步骤有逻辑漏洞或违反约束 │ ├── 执行类(Execution Failure) │ └─ 最终输出不符合预期格式或约定 │ └── 评测类(Evaluation Failure) └─ 答案本身可能是对的,但评测标准错了
为什么这样分?
理解类失败需要改进:更好的提示词、更清晰的输入结构化、或更强的基座模型
推理类失败需要改进:长链路稳定性、思维链(CoT)设计、或外部知识库
执行类失败需要改进:输出约束(如正则表达式)、结构化输出(JSON Schema)
评测类失败需要改进:重新审视评测指标本身
这四类的优化路径完全不同。
3.2 第二层:失败的严重程度划分
不是所有失败都一样重要。我们需要区分:
严重程度 | 定义 | 优化优先级 |
Critical | 答案完全错误,不只是部分不完美;例如:要求 True/False,却输出「可能是」 | 🔴 最高 |
Major | 答案主要思路正确,但关键细节缺失或错误;例如:选择题选对了选项,但原因分析错了 | 🟠 高 |
Minor | 答案内容对,但表述、格式或风格不符合预期;例如:要求一句话总结,却写了三段 | 🟡 中 |
False Positive | 这不是真的失败,是评测标准过于严格;例如:医学问答的合理答案被标注为「错」 | 🔵 需要重新评估 |
为什么需要这个划分?
假如你的评测有 10000 个失败案例,不区分严重程度,你无法定位优化重点。但如果你知道其中 800 个是 Critical、2000 个是 Major,你就能聚焦于最有价值的 2800 个。

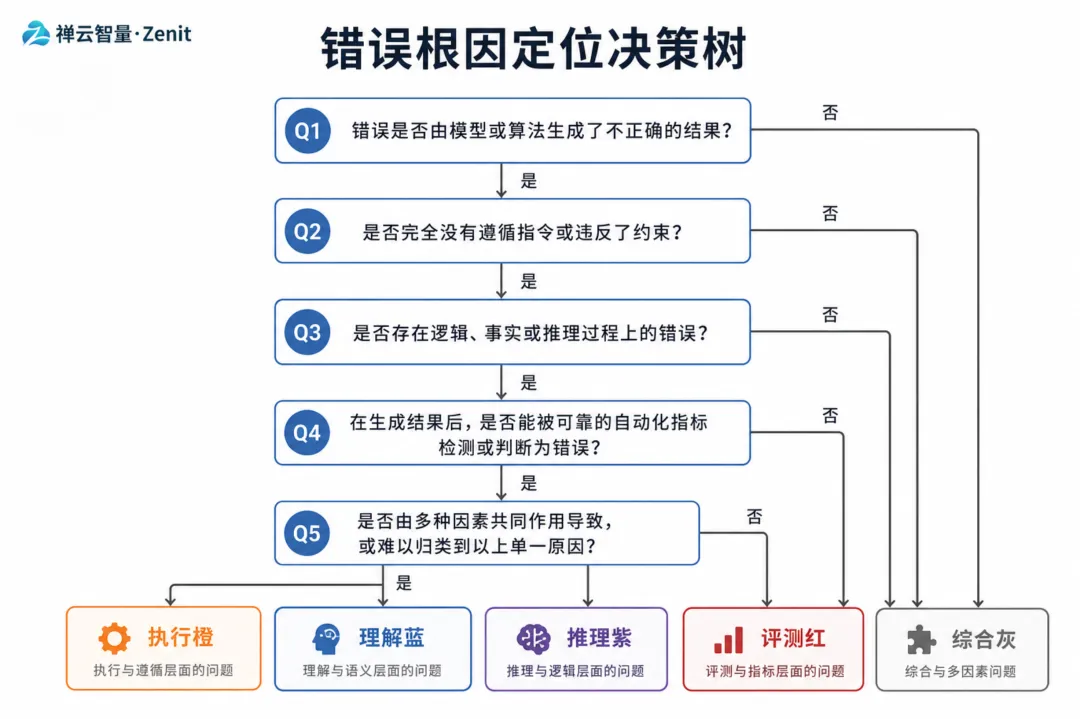
3.3 第三层:归因的决策树
当你发现一个失败案例时,这个决策树可以帮你快速定位根因:
发现失败案例 │ ├─ Q1: 模型输出内容是否为空? │ ├─ YES → 【执行类】模型拒绝或崩溃,检查异常处理 │ └─ NO → 继续 │ ├─ Q2: 输出是否符合指定的格式(JSON/Markdown/等)? │ ├─ NO → 【执行类】格式错误,需要约束输出 │ └─ YES → 继续 │ ├─ Q3: 如果我给 GPT-4 加上详细的背景和思考步骤, │ GPT-4 能否给出正确答案? │ ├─ NO → 【理解类】模型根本理解错了,需要改进提示词 │ └─ YES → 继续 │ ├─ Q4: 答案的中间推理步骤是否逻辑自洽? │ ├─ NO → 【推理类】推理链条有漏洞,需要 CoT 或知识补充 │ └─ YES → 继续 │ └─ Q5: 专家审核认为这个答案可接受吗? ├─ YES → 【评测类】评测标准过于严格,需要调整 └─ NO → 【综合】需要多维度改进
这个决策树的妙处在于:它是从最容易修的问题开始(执行类),到最难改的问题(理解类)。
3.4 第四层:标注规范与工具化
为了让这个分类框架能够一致性地应用,我们需要标注规范:
标注模板(每个失败案例都需要填写):【案例 ID】test_case_20260511_0042【失败类型】理解类 + 推理类【严重程度】Major(因为核心答案对,但推理过程缺失关键步骤)【错误描述】 - 一句话原因:模型未能从长文本中提取关键数字,导致计算错误【改进方向】 - 短期:改进提示词,显式要求"先提取所有数字,然后计算" - 中期:评估长上下文的稳定性(见第9期)【是否已分配修复任务】是 / 否【关联的前置技术债】实验系统(6) / 数据引擎(2)
这样,每个失败案例就不再是孤立的"吐槽",而是可追踪、可复用的数据资产。

四、实践要点:从分类到行动
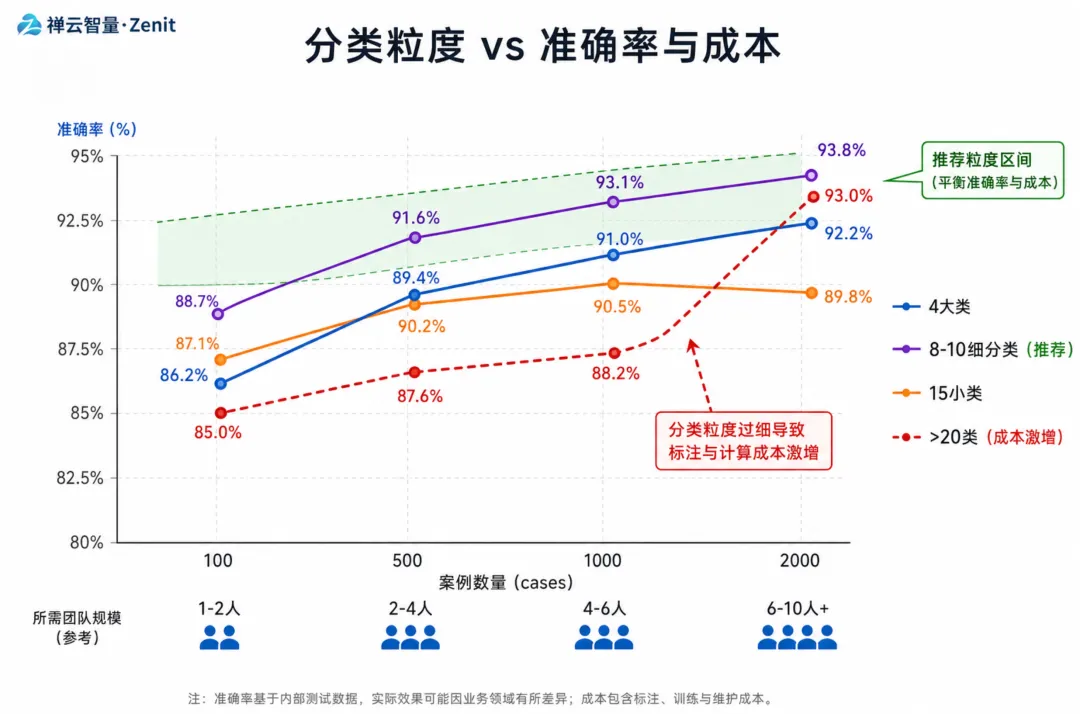
4.1 关键决策1:分类的粒度
问题:是用 4 个大类够了,还是要分到 20 个小类?
建议:从 4 个大类开始,逐步根据你的数据分布细化。
在我们的实验中:
前 100 个案例:用 4 大类,分类准确率 89%
到 500 个案例:加了 3-4 个子类,准确率升到 93%
到 1000 个案例:稳定在 8-10 个细分类,准确率 94%
过度分类(超过 15 个小类)的风险是:标注成本飙升,而边际收益递减。
我们的建议:
小团队(少于 50 人):坚持 4 大类 + 3-5 个常见子类
中等团队(50–200 人):8-10 个细分类
大团队(多于 200 人):可以根据业务特点定制 15-20 个类别
4.2 关键决策2:谁来做标注
选项1:算法工程师标注
优点:理解模型逻辑,标注准确
缺点:工时太贵,影响迭代速度
选项2:产品或测试团队标注
优点:跟业务场景近,能识别评测类失败
缺点:对模型细节理解不足
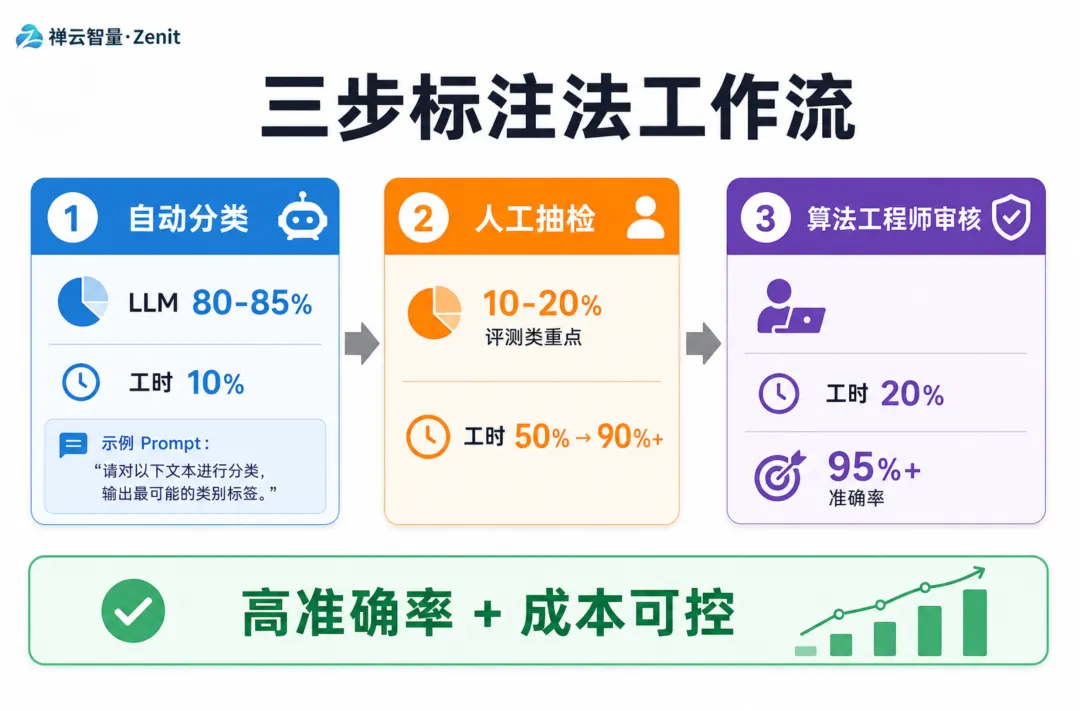
选项3:三步标注法(最实用)
第一步:自动分类(用 LLM 初步分类) └─ 用 Prompt:"这个失败案例属于 [理解/推理/执行/评测] 类,理由是?" └─ 准确率通常 80-85%第二步:人工抽检(标注员抽检 10-20% 的案例) └─ 重点抽查评测类和边界案例第三步:算法工程师快速审核(只审关键案例的分类) └─ 这一步只需要 20% 的工时
这样既能保证准确率,又能控制成本。
4.3 关键决策3:分类后的流转
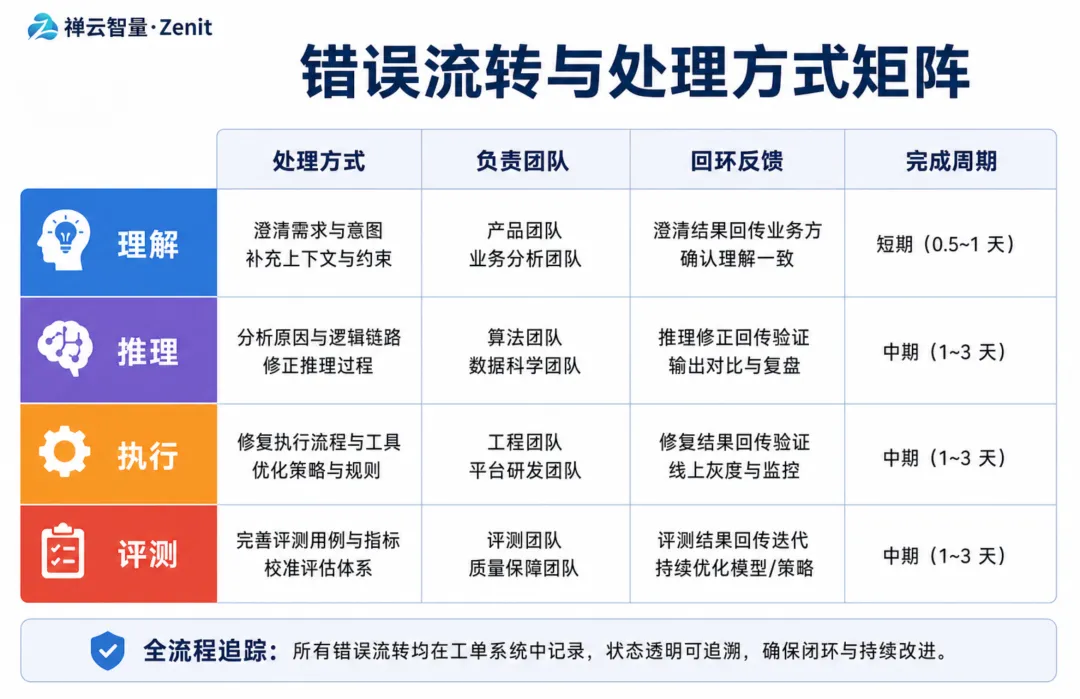
分类完成后,不同类型的错误应该流向不同的团队处理:
错误类型 | 处理方式 | 负责团队 | 回环反馈 |
理解类 | 改进提示词设计 | 产品/测试 + 算法 | 下一轮迭代测试 |
推理类 | 外接知识库或长文本优化 | 算法 + 架构 | 发布新版本再测 |
执行类 | 加入输出约束和后处理 | 工程 | 立即生效 |
评测类 | 重新审视评测指标 | 测试/产品 | 重新标注相关案例 |
这个流转表的意义在于:确保每个失败案例都有明确的处理方向,而不是沉入数据库无人问津。
4.4 关键决策4:如何度量改进
做了这么多分类和分析,改进有没有效果?怎么衡量?
建议用这个指标:
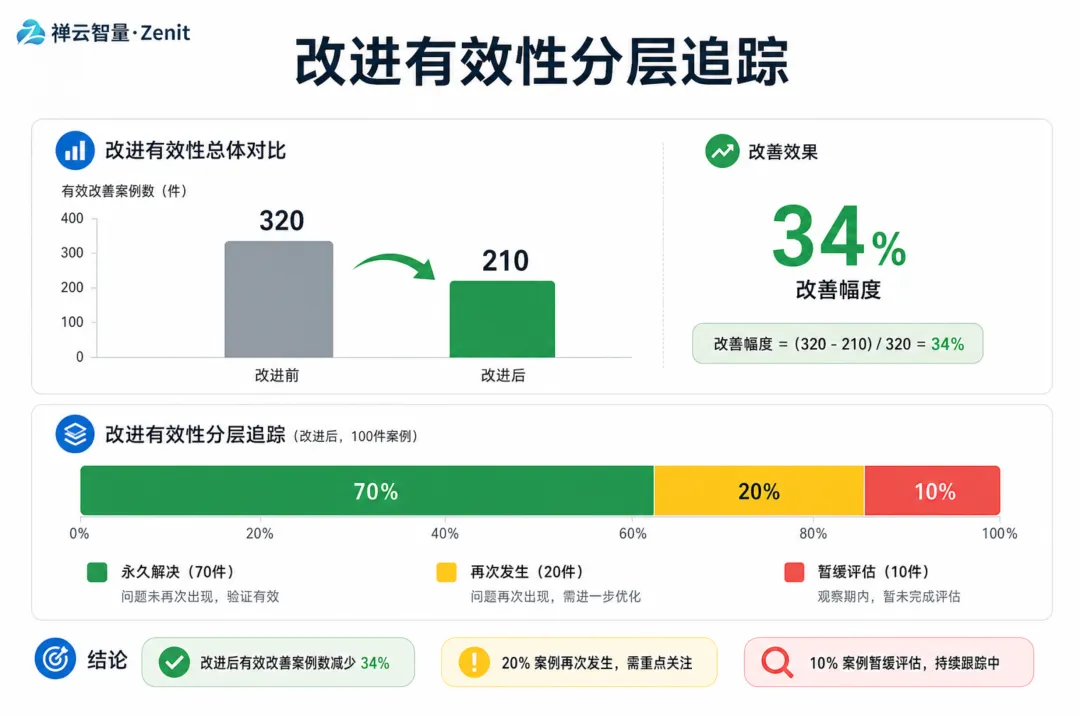
改进有效性 = (修复前失败数 - 修复后失败数) / 修复前失败数以理解类失败为例:- 修改提示词前:理解类失败 320 个- 修改后:理解类失败 210 个- 改进有效性 = (320 - 210) / 320 = 34%
但更重要的是分层追踪:
改进后,这 110 个被修复的案例中:- 有 70% 永久解决了- 有 20% 在新数据上又出现了(数据覆盖问题)- 有 10% 只是被推迟了(真正的深层问题)这说明:✅ 短期改进有效⚠️ 需要扩大评测数据集🔧 需要更深层的架构改进
五、收尾:从「测什么」到「改什么」
这一期我们明确了一个关键转变:
从「用评测发现问题」升级到「用分类理解问题」。
当你建立了错误分类体系,每一个失败案例就不再是压力,而是改进的地图。你知道从哪开始改,改的顺序是什么,改了有没有效果。
但这只是故事的上半部分。
下一期(第八期),我们要讨论的是:当你有了成百上千个失败案例和它们的分类后,怎样把这些「坏数据」变成「进化的数据」?
这就是著名的 Badcase 闭环 —— 也许是决定你的评测系统能否自我进化的最后一道坎。
敬请期待。
