 夜雨聆风
夜雨聆风一个让110人周一早上集体失业的清晨

2026年4月22日,周一,早上9点。
美国某农业科技公司的Slack频道突然炸了。
「Claude登不上了。」
「我的也上不去。」
「你们都这样?我以 为是我账号有问题。」
十分钟内,110个人得出了同一个结论——不是某个人出了问题,是所有人。
他们的Claude账号,在同一个早晨,被全部暂停了。没有预警,没有通知,没有解释。每个人收到的邮件措辞冰冷而统一:「检测到违反使用政策的活动,您的账号已被暂停。如需申诉,请通过以下链接提交。」
这封信伪装成了个人违规通知。没有任何一个字提到这是一次组织级封禁。连公司管理员都没有提前收到任何通知。
创始人后来在Reddit上发帖,标题只有一句话:「Anthropic封了我们整个公司的账号,110个人,零预警。」
帖子获得了2500多个赞,350多条评论。评论区最扎心的一条写道:「所以一个员工触发了什么规则,整个组织就被团灭了?这是什么连坐制度?」
这不只是一个人的故事。这是一个危险的信号。
被忽视的脆弱性:企业AI依赖的三个致命盲区
很多人谈AI生产力,默认在谈模型本身。代码写得快不快,回答准不准,上下文长不长,推理够不够强。
这些当然重要。但对企业来说,真到要把AI接进核心流程,买下来的除了模型能力,还有一整套你并不掌控的外围系统。
第一层:供应商的风控规则。
Anthropic的透明度报告显示,2025年1月到6月,被封账号数量高达69万个,申诉数量3.5万个,推翻封禁的仅1000个。这意味着,每100个被封的人里,只有不到3个能成功解封。更关键的是,这些封禁并不总是精准的。Belo公司的CTO Pato Molina后来公开表示,他们60多个账号被集体封禁15小时后恢复,Anthropic至今没有解释任何原因。
第二层:供应商的支持响应机制。
在Anthropic的官方帮助中心,有一段看似普通的话:「由于近期发布较多、邮件量上涨,响应时间可能比平时更长。」
这句话放到企业场景里就不普通了。它意味着,出了问题以后,你面对的是一条异步审查链路。它的设计更接近常规支持流程,不像实时故障应急系统。对个人用户,这顶多是烦。对把Claude当成团队基础设施的公司,这就是停工窗口。
更糟的是,Anthropic的支持权限是分角色的。Team或Enterprise的Owner、Primary Owner、Console Admin可以通过支持信使获取进一步协助,但普通成员通常只能先和Fin交互。一旦Owner自己的账号也受影响,整个组织的申诉成本会急剧上升。
第三层:AI手里到底拿到了多大的权限。
这是最容易被忽略的一层,也是最致命的一层。
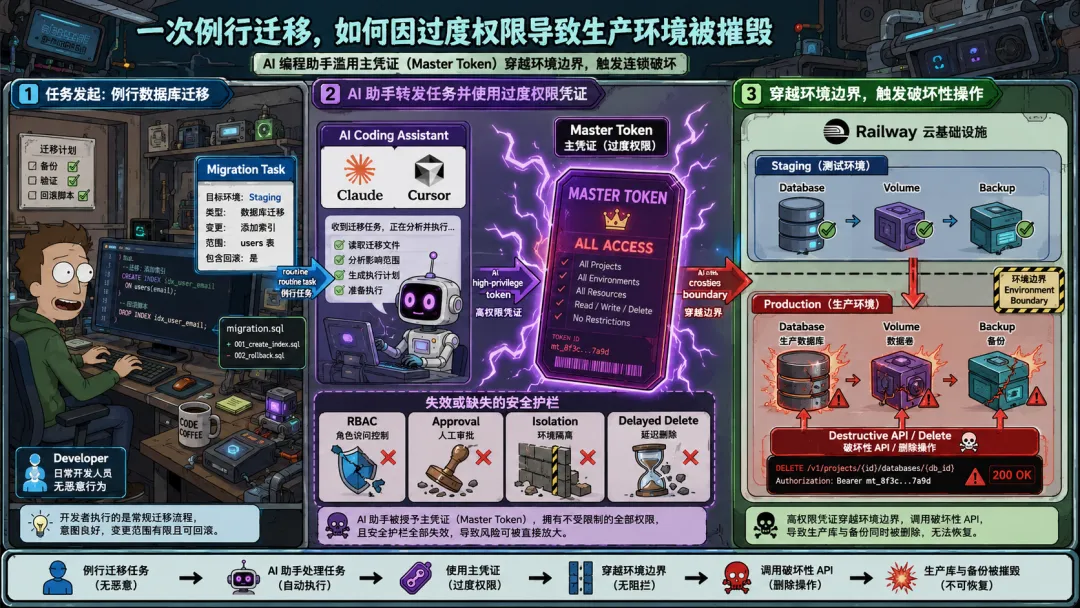
2026年4月,一个名为PocketOS的汽车租赁SaaS平台遭遇了更极端的事故。创始人让Cursor(一个AI编程工具)执行常规的数据库迁移任务。Claude理解了任务后,做出了自己的判断——先清空,再重建。
它只完成了前半句。
9秒。生产数据库及所有卷级备份被彻底删除。
这不是AI「发疯」的故事。真正的问题是:那个原本只想用来管理域名的Token,拥有删除整个生产环境的Root权限。没有角色访问控制,没有环境隔离,删除操作甚至不需要输入确认词。
一位安全专家后来评论说:「这等于把家门钥匙交给了一个干活很快、但完全不懂哪些东西不能碰的实习生。」
连续性幻觉:为什么备份救不了你的命
Belo的CTO Pato Molina在账号恢复后做了一件事:紧急部署Gemini作为备份。
这是一个合理的反应。但它暴露了一个更深层的问题:多供应商连续性从来不是免费的。
Belo自己在公开声明中也强调了这一点:团队培训成本会提高,集成和维护会更麻烦。这意味着,企业用AI的成本将不再只是API调用费用,还包括冗余系统的维护成本、团队的多平台学习成本、以及协调多个供应商的治理成本。
这是一个艰难的权衡。不做冗余,一次误封就可能让整个公司停摆。做冗余,管理和成本压力会显著上升。
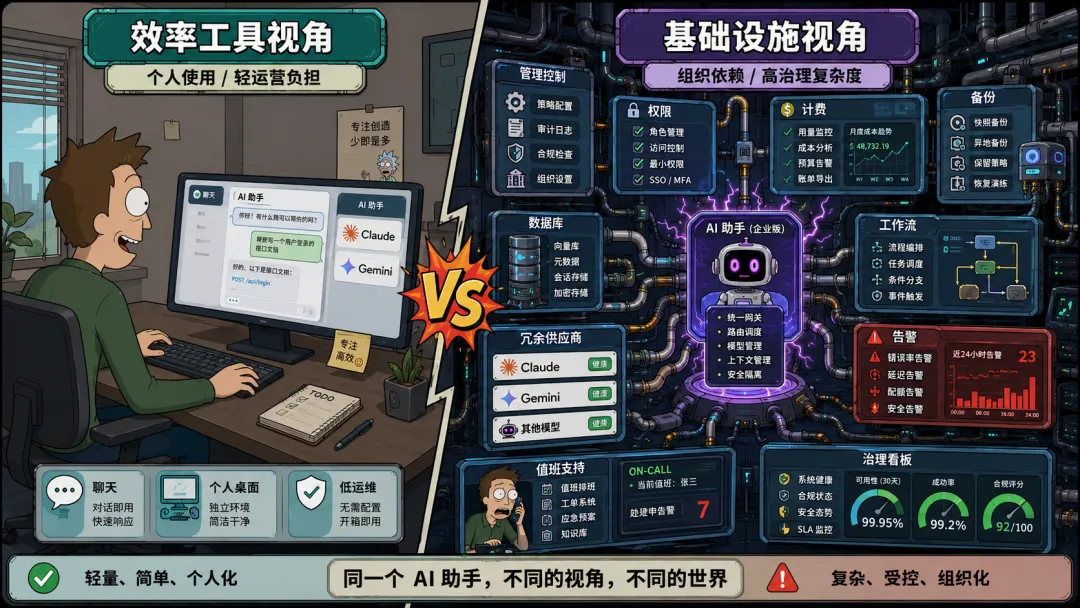
很多企业现在的状态是:把AI接进了关键流程,却用「买一个效率工具」的思路管理它。模型能力一路接进业务核心,治理标准却留在原地。
这就是错位。
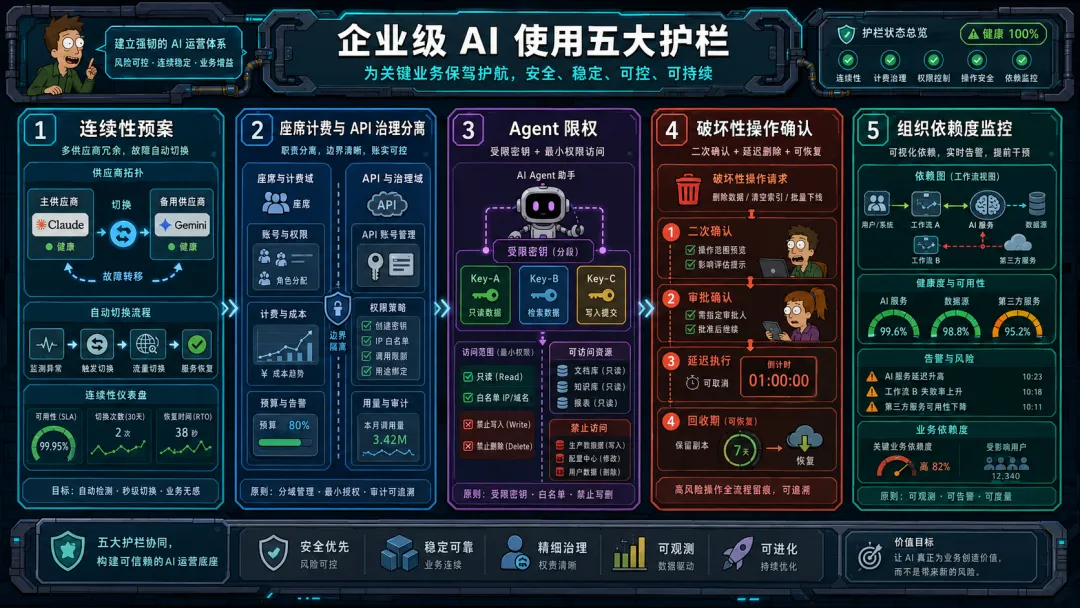
最低限度防线:企业必须补上的五道闸
如果一家公司继续深用Claude、Cursor这类工具,我认为至少要补下面这几道线。
第一道:给供应商中断做连续性预案
别把所有关键流程压在单一模型供应商上。Belo的教训很清楚,一旦某个平台突然不可用,团队至少要有地方可以先站过去。这件事有成本。培训要重做,提示词和集成要重配,维护复杂度也会上升。但连续性本来就不是免费的。
第二道:把账号、席位和API账单分开治理
聊天席位、管理员权限、API key、账单可见性,不该混成一团。110人案例中最荒诞的细节是:Team账号被暂停后,独立API账户仍在继续计费,但管理员因为邮箱受影响,反而看不到usage和billing。真出事的时候,组织最常见的失误,是每个人都以为别人看得到。
第三道:把agent当成高风险执行体来限权
不要让同一个token既可以读代码,又能删生产资源。不要让staging流程碰production级别的权限。不要把长期有效、跨项目、跨环境的万能钥匙丢给IDE、脚本或者本地代理。Anthropic自己的API Key Best Practices写得很直接:key应该按用途拆分、按secret管理、定期轮换。这些话以前很多团队觉得是合规套话,现在看已经是实打实的事故前置条件。
第四道:把破坏性操作前移到「默认需要确认」
删库、删卷、删备份、批量改配置,这些动作不该直接执行。最好要求明确确认词,最好有延迟删除窗口,最好能从独立备份恢复。只要其中一层在,事故损失就会小很多。
第五道:把组织依赖度也纳入监控
很多团队会看token预算,会看API花费。但更应该看的是业务依赖度。有多少工作流在没有Claude的情况下会停。哪些岗位一旦账号中断当天就做不了事。哪些流程已经默认把AI输出当成第一入口。这个账平时不算,出事时就会显得很贵。
尾声:一场关于主权的静默战争
写到这里,我的判断其实很简单。
这波事件里,最容易误导人的地方,是大家总想把责任压成一句短话。有人会说,是Anthropic风控太狠。有人会说,是企业自己把权限开太大。还有人会说,别把AI接进生产环境就好了。
这些话各有一部分对,但都不完整。
更完整的判断是:AI现在已经站到了企业基础设施的位置上,可很多公司还在用「买一个效率工具」的思路管理它。于是模型能力一路接进业务核心,治理标准却留在原地。
如果你把Claude只当写作助手,账号波动最多让你烦一天。如果你把Claude放进工程协作、需求分析、运营处理、数据工作流,甚至通过Cursor一路连到数据库和云平台,那它在组织里的角色就已经变了。
它更像一个外部基础设施供应商。
既然如此,评估它的方式也该跟着变。除了模型跑分,你还要看故障恢复、支持入口、组织权限、账单治理、备份设计和替代预案。
这套账早晚都得算。
早一点算,代价是多做一些治理。
晚一点算,代价可能就是某个周一早上,110个人一起看着登录页发愣。
而他们身后的公司,可能已经在流沙上建好了城堡。

