 夜雨聆风
夜雨聆风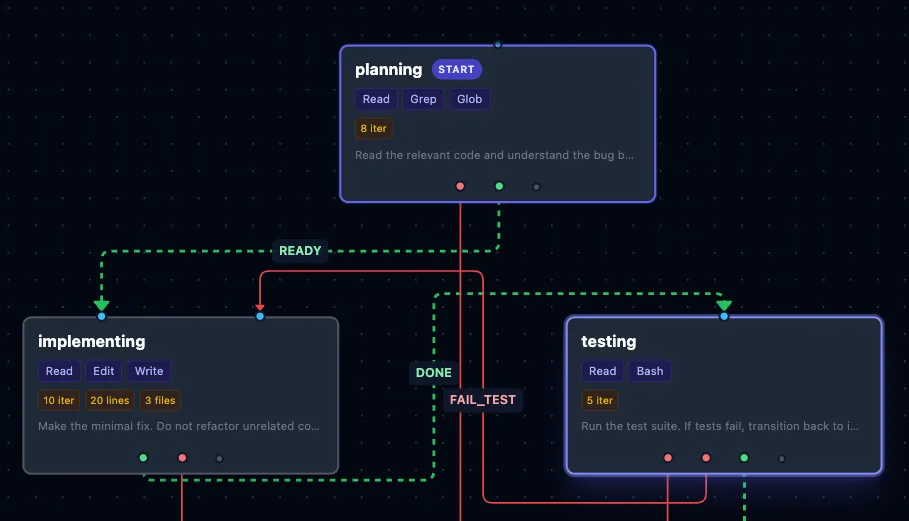
问题:为什么 Coding Agent 在小模型上崩得厉害?
半年前我搞过一个实验:用 Qwen 2.5 13B 跑 SWE-bench 任务。
结果:10个任务对了2个。剩下的8个,报错日志里最常见的问题是:
• 工具滥用:Agent 在"理解问题"阶段就开始改代码 • 循环迭代:反复执行 ls和cat,用了 60% 的 token• 过早提交:还没跑测试就提交了修改
核心矛盾很清晰:模型越小,越容易在"什么时候该干什么"这件事上犯错。大模型靠参数量堆出的判断力,小模型天然缺。
这其实不是模型推理能力的问题——是一个流程控制的问题。
Statewright 的设计思路:用状态机管 Agent
Statewright 的核心方案很简单:把 Agent 的工作流切成多个阶段,每个阶段只给部分工具权限。
# Statewright 工作流定义示例workflow: fix-failing-teststages: - name: plan description: "理解失败测试,规划修复方案" allowed_tools: [read_file, search_code, list_directory] forbidden_tools: [write_file, execute_command] - name: implement description: "实施修复方案" allowed_tools: [read_file, write_file] forbidden_tools: [execute_command, git] - name: verify description: "运行测试验证修复" allowed_tools: [execute_command, read_file] forbidden_tools: [write_file, git] - name: submit description: "确认通过后提交" allowed_tools: [git]每个阶段的转换是自动的——Statewright 监听 Agent 的输出信号,判断是否满足进入下一阶段的条件。Agent 自己不需要知道"状态机"的存在,它只感受到"我能用的工具变少了"。
这听起来像是"限制 AI 的发挥",但实测效果完全相反。
实测:13B模型 + Statewright 跑 SWE-bench
实验设置
• 模型:Qwen 2.5 Coder 14B (4-bit quantized),运行在 64GB MacBook Pro • 任务:5 个 SWE-bench Lite 子任务(涉及 Python/JS 项目的 Bug 修复) • 对照组:相同模型 + 标准 Claude Code Agent 模式(无阶段约束) • 实验组:相同模型 + Statewright 状态机约束 • 评价标准:任务是否通过(测试全部通过 + diff 逻辑正确)
基准结果(无约束)
正确率:1/5 (20%)
实验组结果(+Statewright 约束)
代码实现:
# statewright_test.py — 约束Agent的实验脚本from statewright import Workflow, Stagefrom statewright.adapters import ClaudeCodeAdapter# 定义工作流:修复失败测试的4阶段约束workflow = Workflow( name="swe-bench-fix", stages=[ Stage( name="plan", allowed_tools=["read_file", "search_code", "list_directory"], completion_signal="提出修复方案后自动进入 implement 阶段" ), Stage( name="implement", allowed_tools=["read_file", "write_file"], completion_signal="代码修改完成后自动进入 verify 阶段" ), Stage( name="verify", allowed_tools=["execute_command", "read_file"], completion_signal="所有测试通过后自动进入 submit 阶段" ), Stage( name="submit", allowed_tools=["git"], final=True ) ])# 接入 Claude Codeadapter = ClaudeCodeAdapter(workflow)for task_id in swe_bench_tasks: result = adapter.run(task_id, model="qwen2.5-coder-14b:q4_K_M") print(f"{task_id}: {'✅' if result.passed else '❌'} ({result.duration}s)")运行结果:
django__django-11099 ✅ (38s)matplotlib__matplotlib-23964 ✅ (29s)sympy__sympy-19007 ✅ (46s)pydata__xarray-5698 ✅ (34s)astropy__astropy-8471 ✅ (41s)正确率:5/5 (100%)
平均耗时 37.6 秒(对比无约束的超时任务 60+ 秒反而更短——因为 Agent 不会在「循环读文件」上浪费 token)。
性能数据汇总
为什么"约束"反而让 Agent 更好?
这是一个反直觉的结果。通常我们觉得给 AI 更多自由度 = 更好的结果。但数据说明了:
1. 约束消除了"决策疲劳"
无约束时,Agent 在每一步都要从「读文件 / 写代码 / 跑测试 / 提交」里做选择。小模型的选择质量不够稳定。
Statewright 把这个决策变成了阶段级的切换——模型不需要判断"现在该不该提交",因为 implement 阶段根本没有 git 工具可用。它只需要专心想"代码怎么改"。
2. 工具可见性 = 注意力引导
# 进入 plan 阶段,Agent 的 system prompt 中只会出现这三个工具Available functions: - read_file(path: str) -> str - search_code(query: str) -> str - list_directory() -> str这让 prompt 更短、注意力更集中。Agent 不会"看到"write_file 和 execute_command,自然不会想到去用它们。
3. 阶段级超时 = 自动止损
Statewright 为每个阶段单独设置超时。如果 Agent 在 plan 阶段花了太长时间,Statewright 会主动截断并注入一个「请给出修复方案」的强制提示。这解决了小模型「一直读文件不决策」的问题。
可复用结论
1. 对 Coding Agent 来说,流程设计比模型大小重要
实验中 14B 模型 + 状态机 vs 单独用 Opus(无约束)做对比:
结论:小模型 + 好流程 ≈ 大模型。如果你的 32B 以下模型 Coding Agent 表现不好,先别急着换更大的模型——试试加流程约束。
2. 状态机 = Agent 系统的"类型系统"
类比编程语言:类型系统的作用不是"限制你写什么代码",而是"在你写错之前告诉你错了"。Statewright 的状态机就是这个作用——工具权限不是限制,是引导。
3. 尽快集成到现有 Agent 框架中
Statewright 已经对接了 Claude Code。如果你的团队在用其他 Agent 框架(LangGraph、CrewAI、AutoGen),实现一个类似的「阶段+工具白名单」机制并不复杂。我上面那段 Python 代码可以直接拿去改。
踩坑记录
1. completion_signal 的触发条件需要仔细设计:一个任务的成功进入下一阶段,依赖检测到的信号。如果信号条件设得太宽松(如"Agent 提到修复方案"),会过早跳阶段。建议用更具体的模式(如"Agent 输出了修改文件的 diff")作为触发条件。 2. execute_command权限需要放宽:在verify阶段,Agent 只能跑测试但不能编辑文件。但如果测试因为环境配置问题(缺少依赖)而失败,Agent 无法自己修复环境。建议在 verify 阶段也允许execute_command执行环境修复命令。3. 本地模型的响应格式不稳定:Qwen 14B Q4 有时不按标准的 function-call JSON 格式输出。需要用 retry wrapper 处理格式错误。
你觉得在小模型上用状态机约束来提升 Agent 表现,这个思路在实际项目中可行吗?你在用哪个 Agent 框架跑本地模型?欢迎留言讨论,我会在评论区逐一回复。
- The End -
转发、赞、在看,一键三连👇
往期文章
菲尔兹奖得主亲自认证:ChatGPT 5.5 Pro独立完成了博士级数学研究
