 夜雨聆风
夜雨聆风
抽象层次每升一次维,设计空间就放大一个数量级。这次,是 AI 推着 FPGA 再升一维。
3 次升维
RTL -> HLS -> AI,FPGA 设计范式的迭代节奏
前几天我分享了我们的 Python2Verilog 框架,介绍如何让 AI 从 Python 算法一键生成 Verilog RTL。这一篇不讲框架,讲讲我这两年做 AI for FPGA 的一些体会:我的经历,我的经验,我的思考。

FPGA 设计抽象的三次升维
1一、我的经历
从波形飞线,到软件视角,再到 AI 时代
我是很多年前本科毕设开始跟着李老师接触 FPGA 项目。那时做板级调试,测试引脚飞线接逻辑分析仪,长时间盯着屏幕对波形、对数据,最原始的办法调试。之后一直在做算法的 FPGA 硬件实现,陆续做了 近二十个星上、机上 FPGA 图像压缩系统,经历过的"痛苦归零"也有十几次。
❗ Important
这段经历给我的最大收获,不是写了多少 VHDL/Verilog,而是在短时间、高压力环境下快速定位问题的工程思维方法。这个训练对我现在做 AI 工作非常有帮助:当 AI 卡壳的时候,需要靠这种工程思维快速找出问题,让 AI 尽快收敛。
在 UCLA VAST Lab 完成的认知升维
我对 FPGA 设计的重新再认识,是在 UCLA 访学期间。我在 HLS 工具发明人 丛京生(Jason Cong) 老师的 VAST 实验室工作。丛老师从 1990 年加入 UCLA 计算机系,2006 年联合创办 AutoESL,2011 年被 Xilinx 收购:AutoESL 就是今天 Vivado HLS / Vitis HLS 的前身。丛老师凭借 HLS 领域的奠基性工作,于 2024 年获得 Phil Kaufman 奖,这是 EDA 领域最高荣誉之一。
在 VAST 实验室我有一个很强烈的印象:做 FPGA 的几乎都是计算机专业的人,他们天然地 以软件编程视角来看硬件设计。这和国内传统做 FPGA 的团队以电子工程师为主、从 RTL 出发的路径完全不同。那一刻我开始意识到:FPGA 设计不该只是停留在 RTL 逻辑电路层面,而应该借助高级程序语言提升到软件语义层来考虑算法与硬件的协同优化。
升一个层级看问题,开发效率会有质的提升,因为可以在更大的设计空间进行架构探索。
HLS 的历史已经三十年。1994 年 Synopsys 发布第一代 Behavioral Compiler,2001 年 Sony 用 Cynthesizer 完成第一颗 HLS 流片,2008 年美国业界开始规模化采用,AutoESL / Vivado HLS 是这条路上迄今最成功、最被广泛使用的 HLS 工具。
✅ Tip
过去二十多年里,有很多 EDA 公司尝试做 C/C++ 到 RTL 的自动化,都没能成功。这件事本身就说明:抽象层次的每一次抬升,都要等工具链成熟、方法论成熟、生态成熟三者对齐。
从 A2H-MAS 到 A2HCoder
正是这种设计思维的转变,让我在 2024 年就察觉到:AI 是 FPGA 开发第三次升维的大好时机。也就是说,可以在更高级的语义层,通过描述硬件架构设计思想来完成 FPGA 设计。
2025 年年中,我们开发了一套 AI 驱动的 MATLAB 到 HLS C++ 的自动化转换工具 A2H-MAS。2025 年 8 月在张老师的指导和帮助下申请了基金项目《A2HCoder: AI-Driven Algorithm-to-Hardware Transformation Engine》,并顺利拿到资助。

Project Info
ℹ Note
感谢项目评审专家在那个时间点就看好我们这个研究方向。那会 AI Coding 还没有像今天这样被普遍接受和认可。
2二、我的经验
经验一:用最新最好的公开基础模型
2024 年我开始把 AI 用于 FPGA 设计时,很多人的质疑点是:大语言模型没有针对 RTL 设计做大规模预训练,他们想构建更多私有的硬件代码样本、训练一个专用的硬件大模型。
我始终持相反的看法:应该用公开的最新的基础大模型:Claude、GPT、Gemini。原因有三条。

公开基础模型 vs 私有微调模型
▍ 原因一:性能差距不是小问题
私有模型的训练数据再怎么精心挑选,总参数量、总数据量都很难达到公开前沿模型的规模。在一个性能天花板明显更低的模型上做大量的打补丁工作,可能 被公开模型的一次版本升级就远远甩开。
▍ 原因二:基础模型升级是硬件代码的直接红利
大模型优化软件代码的方法(更强的推理链、更准的上下文检索、更长的上下文窗口)同样适用于硬件代码。
最近一轮学术研究的结论也支持这个经验:不需要多智能体编排,只需要基础模型 + 轻量反思,RTL 生成就可以达到前所未有的质量。
▍ 原因三:你的时间才是稀缺资源
微调一个私有模型即便有 10% 左右的特定领域增益,每当基础模型版本跳代(今年 Claude 从 4.5 到 4.6 再到 4.7,Gemini 从 2.5 到 3),私有微调都需要重新来一遍。
❗ Important
你的时间和精力是最宝贵的,不应该浪费在跟性能差的模型较劲。
经验二:别追着工具跑,聚焦你的核心业务
围绕 AI Coding 涌现出各种新插件、新工具、新概念,像今年很火的 OpenClaw、Claude Flow(Ruflo)、OpenCode、各种 Agent 编排平台,还有层出不穷的 skill、subagent、swarm 模式…… 几乎每周都有新的上游变化,很难跟得过来。
我试过多模型协同,让 Claude、GPT、Gemini 一起工作;也试过 swarm 模式,一个 Agent 执行任务、另一个 Agent 负责监督,希望实现 AI 长时间不间断工作。这些尝试最终效果都不够好,反而都不如 Claude Code 自身版本升级带来的提升明显。
这里面有一个规律:
真正好用的模式,基础模型厂商会在随后的版本中直接集成进来。
比如 Claude Code 在 2026 年 2 月和 Opus 4.6 一同发布了官方的 Agent Teams(多智能体团队)功能,3 月又把它从实验性转为稳定版。一旦官方版本成熟,上游第三方项目的价值就会被大幅稀释。
所以我们的精力应该始终聚焦在 自己的核心业务:具体算法的架构探索、硬件约束的正确建模、定点数值的精细处理上。工具类的东西没必要花太多时间跟进,如果真的好用,Claude Code 自身的后续升级会把它添加进来。
3三、我的思考
产品化必须同时做对三件事
使用 AI 完成 FPGA 设计开发,想实现真实的工程落地价值,必须同时做对三件事:
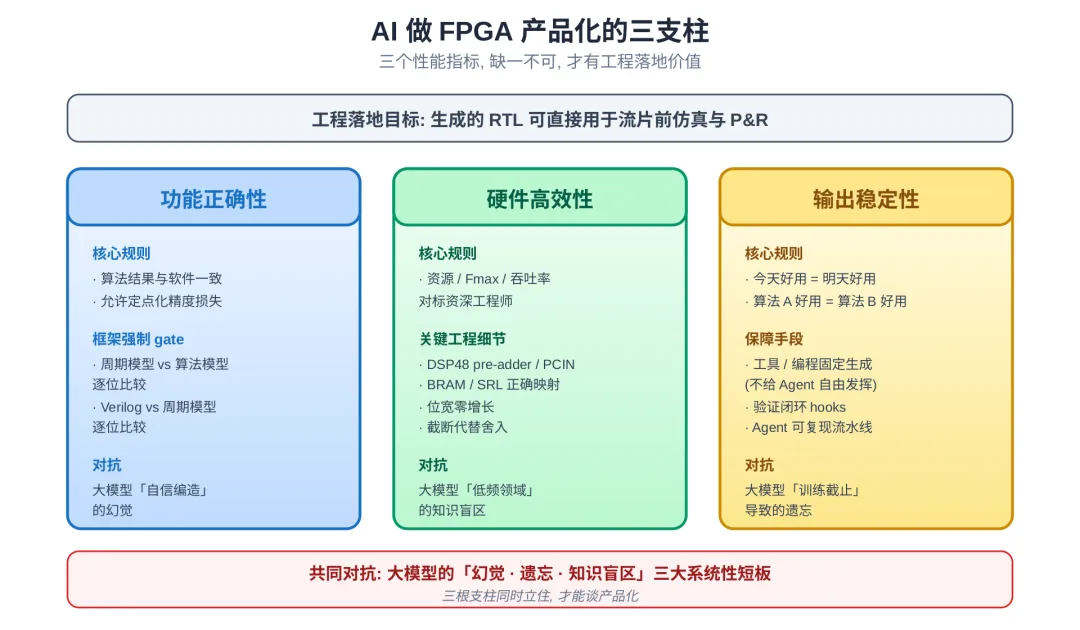
AI 做 FPGA 产品化的三支柱
▍ 支柱一:功能正确性
AI 生成的硬件结果必须与原始软件算法的运行结果一致。允许硬件定点化带来的少量精度损失,但不能是完全对不上的错误。否则 AI 生成的 RTL 代码就是一堆垃圾,没有任何实际应用价值。
❗ Important
Python2Verilog 把这一条工程化成了 周期精确模型与算法模型逐位比较 + Verilog 与周期模型逐位比较 的强制 gate,任何阶段失败都不允许进入下一阶段。
AI 生成的 RTL 必须对应 高效 的硬件结构:资源、时钟频率、吞吐率都要达到或接近资深硬件工程师手工优化的水平。否则用 AI 开发节省出来的时间就没有太大意义,不如投入人力花更长时间做出长期好用的硬件代码(短期投入大,但长期受益)。
具体落到工程细节:
- ▶DSP48 级联:
pre-adder / PCIN 是否用上 - ▶延迟线:
用 BRAM 还是 SRL - ▶位宽增长:
是否做到零增长 - ▶输出量化:
截断而非舍入
▍ 支柱三:输出稳定性
能够用 AI 稳定 地输出高性能代码。不能今天好用、明天再跑就不好了;不能对某个算法好用、换个算法就不灵了。
稳定性来自两个方面:
✅ Tip
第一,Prompt 和工具链本身的确定性:能用工具或编程固定做的事,绝不交给 Agent 自由发挥。
第二,验证闭环的完整性:每一条工程经验都落进可运行的 hook 或验证脚本,让 AI 下次犯同样的错时被自动拦截。
三根支柱都立在一个共同目标上
无论哪一根支柱,都是在对抗大模型的 三大系统性短板:幻觉,遗忘,知识盲区。
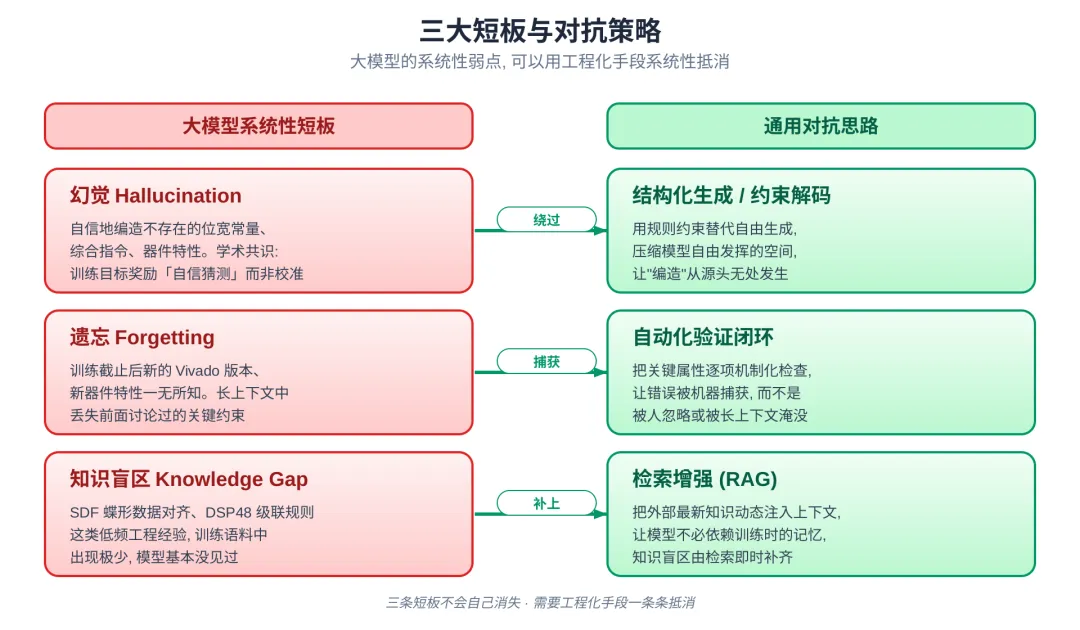
三大短板与对抗策略
▍ 幻觉 Hallucination
模型在缺乏准确知识时倾向于"自信地编造",这在硬件领域尤为致命:一个编造的位宽常量、一个编造的 Vivado 综合指令,可能让一个本该工作的设计彻底跑不起来。
最新的学术共识是:幻觉的根源是训练目标奖励了"自信的猜测"而不是"校准的不确定性",短期没有一劳永逸的解。
通用思路:结构化生成与约束解码,压缩模型自由发挥的空间。
▍ 遗忘 Forgetting
模型的上下文长度有限,很难记住复杂系统设计流程中的长序关联信息,在长上下文中容易丢失前面讨论过的关键约束,导致在同样的问题上反复出错。
通用思路:多阶段自动化验证,把关键属性逐项机制化检查。
▍ 知识盲区 Knowledge Gap
硬件领域的很多经验在开源语料中出现频率极低,模型训练时几乎没见过。比如 SDF FFT 的蝶形数据对齐、DSP48 级联时的 PCIN/PCOUT 连接规则:这些都是教科书之外、工程师在项目中沉淀的经验。
通用思路:检索增强(RAG),把外部最新知识动态注入上下文。
三条短板不会自己消失,需要工程化手段一条条系统性抵消。
3 条短板 x 3 个支柱
AI 做 FPGA 产品化的全部内容
4写在最后
回顾过去,三段旅程其实在做同一件事:不断把自己从具体的 bit 操作中解放出来,把注意力放到更高的抽象层上。
- ▶从 RTL 到 HLS:
把"怎么写寄存器"的注意力,换成了"用什么软件语义来描述算法"。 - ▶从 HLS 到 AI:
把"怎么写 C 代码"的注意力,换成了"用什么架构思路来组织计算"。
❗ Important
下一次升维,会是什么时候、由什么触发?我不知道。但我相信,现在还在手工写 RTL 的同行,会和当年的我在 UCLA VAST Lab 看到同事们用 C++ 写 FPGA 时的感受一样:有一天会突然意识到,这件事原来可以不这么做。
路径相同
每一代工程师都会在某一刻,把自己从底层解放出来
如果你和我一样在做 AI for FPGA 的探索,欢迎交流。这条路还长,而且只会越走越宽。
