 夜雨聆风
夜雨聆风当行业还在争论“多大的上下文窗口才够用”时,我们需要面对一个更本质的问题:AI Agent真正需要的不是“能记住更多”,而是“能记住对的”。
过去一年,AI Agent从实验室的Demo快速走向企业生产环境。我们见证了无数令人惊艳的演示,也目睹了更多在实际落地中折戟的案例。几乎所有失败的根源,都指向同一个问题:记忆不可靠。
在一个典型的 AI Agent 应用中,记忆系统往往面临这样的困境:
你和Agent助手合作了三个月,期间换过一次工作方向、调整过两次项目目标。当你问“我上个月的目标是什么”,Agent 做了一次语义检索,把三个月前的目标和上个月的目标混在一起返回了——因为在纯语义空间里,“目标”这个词不会因为时间不同而拉开距离。
这个问题,没有一个能靠把上下文窗口从128K扩大到1M来解决。因为大模型的上下文窗口本质上是一个“临时缓冲区”,而不是一个“长期记忆系统”。真正的长期记忆,需要结构化、可检索、可验证,并且最重要的是——有时间感。
近期,红熊AI记忆科学正式发布MemoryBear v0.3.3版本。重点解决了AI记忆系统最核心的两个底层问题:时间维度的缺失和信息密度的不足。
从“记住了什么”到“记住了什么时候”,从“能存进去”到“能取出来用”,MemoryBear v0.3.3正在重新定义AI记忆系统的行业标准。

时间记忆上线:让AI拥有了“历史观”
如果说人类的记忆是一条流淌的河流,那么此前绝大多数AI Agent的记忆就是一堆散落的碎片。它们能告诉你“有过这件事”,但永远说不清楚“这件事发生在什么时候”。
这背后的技术根源极其简单却又极其致命:几乎所有的记忆系统都只在记忆条目上记录了一个“创建时间”——也就是“这条信息什么时候被存进数据库的”,而不是“这件事实际上什么时候发生的”。
这就导致了一个荒谬的场景:用户在5月10日说“我上周换了工作”,系统会把"换工作“这件事的时间标记为5月10日。当用户在5月15日问“我这个月换工作了吗”,系统会回答“是的”;但当用户问"我上个月换工作了吗",系统也会回答“是的”——因为在它的认知里,“换工作”这件事就发生在5月10日。
更糟糕的是,系统完全不知道信息会过期。当用户在6月1日说“我又回到了原来的公司”,系统只会新增一条记录,而不会把“我换了工作”这条记录标记为失效。于是,当用户再问“我现在在哪里工作”时,系统会同时返回两条相互矛盾的信息,然后随机选择一条来回答。
MemoryBear v0.3.3彻底终结了这个行业顽疾。
本次版本为所有实体关系新增了三个结构化时间字段,构建了完整的时间坐标系:
dialog_at:对话发生的时间——“这条信息是什么时候被说出来的”
valid_at:事件发生的时间——“这件事实际上是什么时候发生的”
invalid_at:事件失效的时间——“这件事从什么时候开始不再成立”
这三个字段看似简单,却从根本上改变了AI记忆的本质。现在,当用户说“我上周换了工作”,系统会自动解析出:dialog_at=5月10日,valid_at=5月3日左右。当用户后来又说“我又回到了原来的公司”,系统会自动将前一条记录的invalid_at标记为6月1日。
有了这个完整的时间坐标系,Agent开始真正拥有了“历史观”。它不仅能回答“发生了什么”,还能回答“什么时候发生的”“持续了多久”“现在还成立吗”
在此基础上,MemoryBear v0.3.3实现了真正意义上的时间检索。用户可以问“上周发生了什么”“三月份讨论过哪些方案”“过去半年我调整过几次目标”——这些在纯语义检索里几乎无解的问题,现在都能得到精确的答案。
因为“上周”从来就不是一个语义概念,它是一个时间窗口。只有当记忆本身带有结构化的时间标记,系统才能把自然语言中的时间表述翻译成精确的时间区间,然后在海量记忆中进行过滤和检索。
配合时间字段,记忆验证接口还新增了session_id参数,支持跨对话轮次的代词消融。当用户说“继续上次的方案”,系统不再需要猜测“上次”指的是哪次对话,而是可以根据session链路自动还原完整的上下文。
在此之前,AI的记忆是平面的;在此之后,AI的记忆变成了立体的、有时间轴的、有生命周期的。
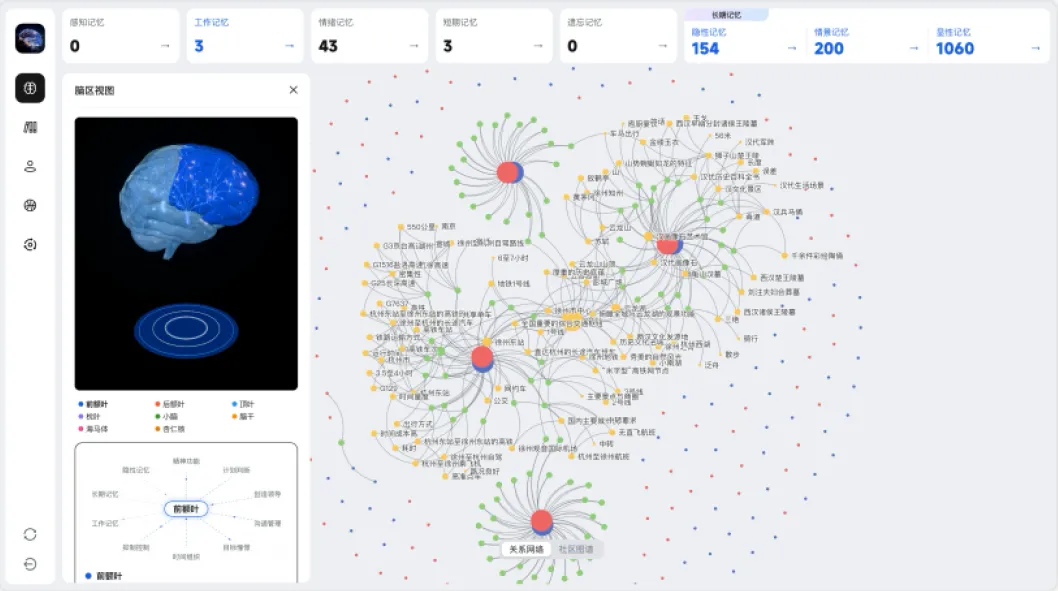
新萃取流水线:把记忆的“入口质量”做到极致
如果说时间维度解决了“记忆在哪里”的问题,那么萃取精度就解决了“记忆是什么”的问题。
记忆萃取流水线是整个记忆系统的“入口质量关”。一段对话进来之后,能不能准确识别出“谁”“做了什么”“和谁有关”“产生了什么结果”,直接决定了后续存储、检索、推理的上限。
很多Agent看起来“记性不好”,其实根本不是存储的问题,而是萃取的问题。如果在入口处就把信息提取错了,那么后面无论检索算法多么先进,都不可能得到正确的结果。
MemoryBear v0.3.3没有在局部做小修小补,而是直接替换了整条记忆萃取流水线。新一代萃取引擎在实体识别准确率、关系提取准确率和吞吐量三个核心指标上都实现了显著提升。
配合萃取引擎的升级,红熊AI还对本体工程体系进行了全面更新。本体工程是知识图谱的“骨架”,它定义了世界上有哪些类型的事物,以及这些事物之间有哪些类型的关系。
本次更新重新梳理了通用本体工程的上下层级定义:
Upper Level:定义最抽象的概念类别,如人、事件、地点、时间、组织
Lower Level:定义具体的概念子类,如同事、会议、办公室、上周二、客户公司
层级定义的优化,让萃取出来的实体会被归到更准确的类别下。
比如,系统现在能准确区分“王经理”是一个“人”,而不是一个“职位”;能准确识别“项目评审会”是一个“事件”,而不是一个“文档”。
在读取端,v0.3.3也做了一个非常重要的改进:L0记忆读取增强。
现在,当调用记忆读取接口时,系统会自动返回固定的用户画像四维字段:goals(目标)、traits(性格)、interests(兴趣)、core_facts(核心事实)。
这看似是一个很小的改动,却极大地降低了接入方的使用门槛。此前,接入方需要自己从海量的metadata中筛选出有用的用户信息;现在,系统直接给出了结构化的用户画像,接入方可以开箱即用。
如果把这一版的记忆升级画成一个坐标系:X轴是写入质量(新萃取引擎+本体工程升级),Y轴是读取维度(时间字段+时间检索)。两个轴同时升级,意味着记忆系统的有效信息密度上了一个数量级。
工程化能力:让AI记忆真正走向生产
一个优秀的技术产品,不仅要有领先的核心能力,还要有过硬的工程化能力。对于企业级应用来说,后者往往比前者更重要。
MemoryBear v0.3.3的另外两个重大升级——工作流单节点运行和知识库工程化,正是瞄准了企业生产环境中的核心痛点。
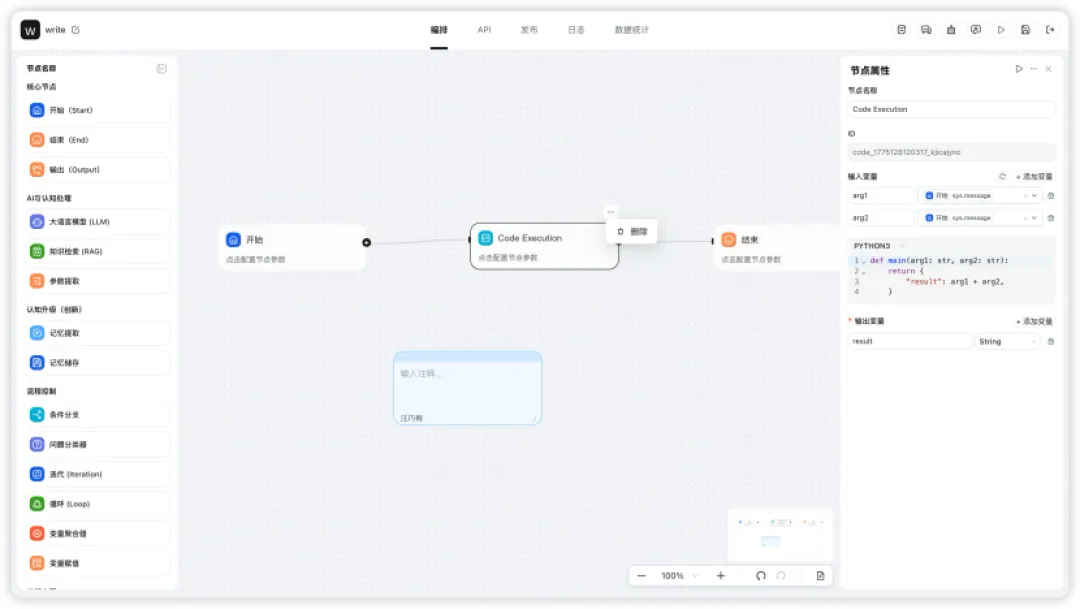
工作流单节点运行:调试效率提升10倍
此前,调试工作流是所有开发者的噩梦。如果你想调试工作流里第12个节点的逻辑,你必须从第1个节点开始跑完整条流程。如果这条流有15个节点,那么每调试一次,前面11个节点都得空跑一遍。
这不仅浪费时间,还会引入大量不必要的变量。有时候,你以为是第12个节点出了问题,结果发现是第3个节点的输出有问题。这种“连锁反应”式的调试,让工作流的开发效率极其低下。
MemoryBear v0.3.3,工作流支持所有16+种节点类型的独立执行。无论是模型节点、工具节点、代码执行节点,还是记忆提取、知识检索、条件分支节点,每一个节点都可以被单独拎出来运行。
开发者现在可以直接点击任意一个节点,填入测试输入,立刻看到输出结果。这不仅把调试效率提升了一个数量级,还让问题定位变得极其简单。
配套的两个改进让单节点调试更加完善:
变量真实值展示:节点输入中包含变量时,现在展示解析后的真实值而非变量名称,开发者不用再猜“这个变量到底传了什么进来”。
模型节点异常处理分支:模型节点新增异常处理分支,优雅处理敏感词过滤等错误,避免静默失败。
知识库工程化:从“手工维护”到“可被集成”
此前的知识库系统,更像是一个“个人笔记工具”,而不是一个“企业级基础设施”。你可以手动添加几条QA,但当知识库规模上到几千条、几万条时,手动维护就变得完全不可行。
MemoryBear v0.3.3对知识库系统进行了彻底的工程化改造,所有改动都指向同一个方向:让知识库成为可以被外部系统集成的基础设施。
文件系统抽象:知识库文件存储使用API层文件系统,支持OSS、S3和本地存储后端互换,部署方可以根据自己的环境选择存储后端,不需要改业务代码
批量操作API:新增知识库录入的服务端批量操作API,支持批量导入和修改,这是知识库从“手工维护”走向“程序化管理”的前提
CSV按行分块:CSV文件导入后按一行一个chunk处理,彻底解决了之前行数据被合并导致的检索精度问题
完整的调试支持:知识库页面现在显示知识库ID、文档ID和chunk ID,当检索结果不符合预期时,开发者能直接追溯到源头
这些工程化能力的提升,让MemoryBear不再只是一个“好用的工具”,而是变成了一个“可靠的平台”。企业现在可以基于MemoryBear构建大规模的、生产级的AI Agent应用,而不用担心性能、稳定性和可维护性的问题。
· 结语 ·
2026年的AI Agent,不缺更强的模型,不缺更大的窗口,缺的是长期交互中的可靠性。
而可靠性的基础是记忆的质量——能不能记住、记多准、记多久、能不能在需要的时候精准召回。
MemoryBear v0.3.3沿着这条线索,把“时间维度缺失”这个长期被忽视的问题摆上了台面,并给出了一套工程上可落地的方案。
时间记忆让 Agent 能区分“昨天”和“上个月”,新萃取引擎让记忆写入更精准,工作流单节点运行让复杂系统的调试不再痛苦,知识库工程化让记忆基础设施真正可被集成。
当记忆有了时间轴,Agent 才会真正从“聊天机器人”变成了“数字伙伴”。它不仅能记住你们说过什么,还能记住这一切发生的时间线。 这才是长期交互的基础,也是Agent走向生产环境的必经之路。

推荐阅读


关注红熊AI,了解AI应用前沿动态~
