 夜雨聆风
夜雨聆风
一个 Agent 跑完任务,下次能不能做得更好?这就是 AI Agent 自进化赛道在解决的事。
下面拆解六个项目:Hermes Agent、GenericAgent、EvoAgentX、Evolver,加上 OpenSpace 和 AgentFactory。它们都叫"自进化",但做的事情差很远。
先说我用来判断的五层标准:
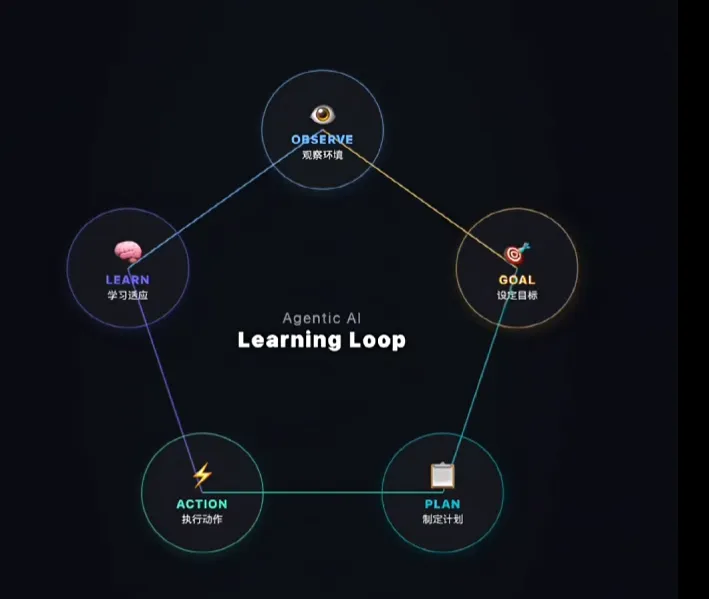
第一层:记忆 — 能记住过去的交互内容 第二层:Skill 沉淀 — 把成功经验提炼成可复用的技能 第三层:Workflow 优化 — 基于评估反馈迭代工作流 第四层:工程化自进化协议 — 自动触发、显式验证、可审计可回滚 第五层:群体经验共享 — 一个 Agent 学到的东西,其他 Agent 能直接用
记住"上次怎么做",是记忆。从失败里提取规律、验证规律、把规律固化成能力,才叫进化。
一、 Hermes 生态:从 Skill 沉淀到模型权重更新方向
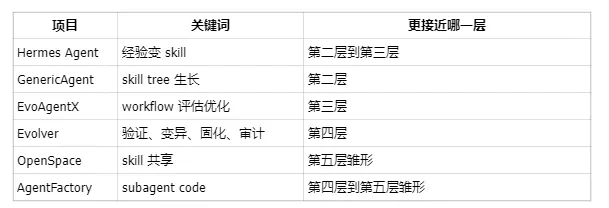
Hermes Agent 的定位很直白:The agent that grows with you。截至 2026 年 5 月,主仓库(NousResearch/hermes-agent)积累了 147k+ stars,赛道里现象级的项目。
它内置了一套 learning loop:从经验中创建 skills,在使用中改进 skills,保存知识,搜索过去对话,建立跨 session 的用户模型。普通 memory 是"我记得你说过什么",Hermes 做的是"我把你做事的方法整理成一个可复用流程"。任务跑通后,有用的路径沉淀成 skill,后续直接调用。
生态里还有两个模块值得单独说。
Self-Evolution 模块(独立仓库,3k stars):用 DSPy + GEPA(Genetic-Pareto Prompt Evolution)自动优化 skills、tool descriptions、system prompts 和 code。不需要 GPU,API 调用生成变体、评估结果、选更优版本。
Hermes RL 训练(探索性实现,如 trajectory-based LoRA 训练):把执行轨迹转化为训练信号,更新模型权重(LoRA adapter 可热加载)。这条路激进得多——skill/prompt 优化改的是外部指令,RL 训练直接改模型行为本身。
三条线合起来,Hermes 构建了从记忆到进化的完整路径。但成熟的在线 RL 闭环还在早期,目前处在第二层到第三层之间。
二、GenericAgent:让 Agent 自己长出 Skill Tree
GenericAgent(lsdefine/GenericAgent,11.1k stars)的想法很直接:别一开始就塞满技能,让 Agent 在使用中慢慢长出技能树。
核心代码只有大约 3K 行。9 个原子工具 + 约 100 行 Agent Loop,每次完成任务后,把执行路径 crystallize 成 skill(已引入 verified past trajectories 机制,转为 reusable SOPs 和 executable code)。新 Agent 从零开始,在真实任务里探索、试错、修正,成功后能力增长一分。
问题也很明显。一次成功不代表经验可靠,skill 跨场景复用、边界处理、避免固化错误经验,都还需要更强的验证机制。目前处在第二层。
三、EvoAgentX:优化的不是记忆,而是 Workflow
EvoAgentX(EvoAgentX/EvoAgentX,3k stars)更像一个 Workflow 优化实验室。
它用于构建、评估和演化 LLM Agent 或 agentic workflow。集成了 TextGrad、AFlow、MIPRO 等方法,自动生成、执行、评估并优化 prompts、tools 配置和 workflow topologies。
关心的不是"Agent 记住了什么",而是"这个 workflow 能不能在评估反馈中变得更好"。任务成功率、成本、流程稳定性、评测指标都能持续迭代。放在第三层。
四、Evolver:把经验变成可审计的进化资产
Evolver(EvoMap/evolver,7.4k stars)关心的底层问题是:经验应该以什么形式被保存、验证、变异和继承?
核心是 GEP(Genome Evolution Protocol),一个 self-evolution engine,把临时 prompt tweak 变成可审计、可复用的 evolution assets。GEP 把学习环拆成四步闭环,让经验从"用了一次就丢"变成"留下来、验证过、可复用"。
几个项目里最接近第四层的。自动触发、有显式验证闭环、产出可审计复用。但验证质量、规则泛化、副作用处理、跨 Agent 共享时的版本冲突,都还在早期。我对这条路线整体偏乐观,但离工程成熟还有距离。

五、两个小玩家:OpenSpace 和 AgentFactory
OpenSpace(HKUDS/OpenSpace):把 skills 视为 living entities,支持 FIX/DERIVED/CAPTURED 三种自动进化模式,通过 open-space.cloud 社区实现 agents experience sharing。一个 Agent 学到的 skill 能给其他 Agent 用——初步走向第五层群体经验共享。已验证可降低 46% token 消耗。
AgentFactory(zzatpku/AgentFactory):思路更硬。不把经验保存成文字,保存为 executable subagent code,根据执行反馈持续改进。解决的是"文本经验执行不稳定"这个实际问题——沉淀下来的东西直接可运行、可测试、可迁移。第四层到第五层的雏形。
六、 谁是真进化,谁只是高级记忆?
可以这样横向对比(基于当前公开实现):
判断标准三条就够了:
能不能把记忆变成可复用的 Skill? 有没有验证、变异、回滚的工程闭环? 沉淀出来的是文字描述,还是可执行、可共享的"基因"?
市面上不少"自进化 Agent",本质上还是记忆系统。能记住过去、复用经验,但稳定验证、自动变异、可靠固化和群体共享,目前没几家真正做到。

七、 终局预测:从个人经验到群体遗传
Agent 自进化的终局不是单个 Agent 越来越聪明,而是一个 Agent 完成任务后留下几类资产:验证过的 Skill(有成功率的可复用能力)、经验规则(从失败中提取的做事规律)、可执行代码(能直接跑的子 Agent)、共享协议(其他 Agent 能发现和继承这些资产的机制)。
一个 Agent 踩过的坑,不应该让所有 Agent 重新踩一遍。一个 Agent 验证过的规则,应该能进入公共能力网络。到那时候,Agent 会更像一个拥有群体遗传能力的数字物种,而不只是某个用户的私人工具。
"我记得你上次说过什么"是记忆。
"我验证了规律,固化成能力,后续持续修正,还能分享给其他 Agent"是进化。
这是 AI Agent 自进化赛道真正值得盯的地方。
