 夜雨聆风
夜雨聆风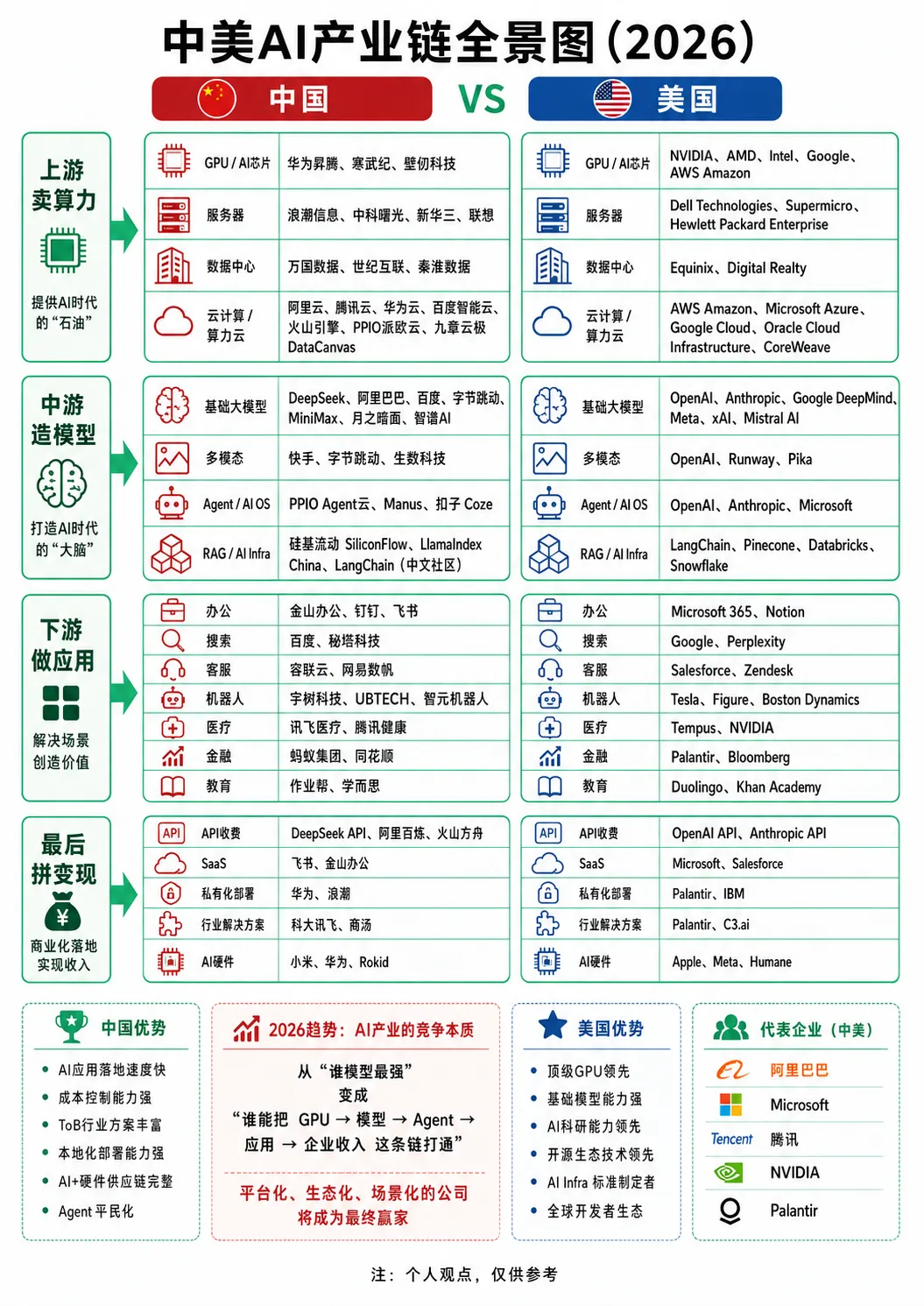
手札 | AI大模型 手札 | 储能 手札 | 光模块 手札 | AI助手 手札 | 低空经济(一) 手札 | 低空经济(二) 手札 | 具身智能 手札 | 人形机器人 手札 | 光伏 手札 | 稀土 手札 | 人工智能 手札 | 半导体-芯片 手札 | CPO 手札 | 智能驾驶 手札 | AI算力
在2026年的时点上回望全球人工智能产业,一幅清晰的中美分工与角力图已经浮出水面。这份产业链全景图不再停留在“谁家模型参数更大”的浅层比较,而是从上游算力、中游模型到下游应用,层层拆解两国各自的底牌与软肋。有意思的是,当人们习惯性地将目光投向NVIDIA的GPU或OpenAI的GPT系列时,全景图揭示了一个更微妙的现实:AI产业的竞争本质,已经从“单点技术突破”转向了“全链路贯通能力”——谁能更高效地把GPU算力转化为模型推理能力,再经由Agent或AIOS封装成可落地的企业服务,最后在真实场景中拿到收入,谁才真正掌握了话语权。 请在微信客户端打开 先看上游。美国阵营的优势几乎是压倒性的。NVIDIA、AMD、Intel三家传统芯片巨头加上Google自研的TPU、AWS的Trainium/Inferentia,构成了从训练到推理的完整硬件矩阵。更关键的是,围绕CUDA生态建立的开发者壁垒,使得任何新进入者都面临极高的迁移成本。相比之下,中国这边的华为昇腾、寒武纪、壁仞科技虽然在特定场景(如昇腾的推理性能)已经追赶到可用水平,但整体生态成熟度仍有明显差距。一个值得注意的细节是,美国的上游名单里出现了Google和AWS——这意味着云计算巨头正在垂直整合芯片设计,不再单纯依赖外部采购。而中国上游的“卖算力”角色仍然分散:服务器层面的浪潮、中科曙光,数据中心里的万国数据、世纪互联,以及提供算力云服务的阿里云、腾讯云、华为云,甚至出现PPIO派欧云、九章云数据这类中小玩家。这种分散在某种程度上体现了灵活性,但也暴露出缺乏像英伟达+亚马逊那样“芯片+云”深度绑定的旗舰组合。 把视线移到中游,景象开始分化。美国的基础大模型阵营依然由OpenAI、Google DeepMind、Anthropic领跑,Meta的Llama系列则以开源策略侵蚀市场,xAI和Mistral AI作为新锐力量补充生态。中国这边,DeepSeek在2025-2026年的异军突起打破了“中国模型总落后一步”的刻板印象,其推理效率和成本控制能力甚至让硅谷同行感到压力。阿里巴巴、百度、字节跳动各自押注多模态和Agent方向,MiniMax、月之暗面、智谱AI则在垂直领域深耕。不过,全景图中一个容易被忽略的对比在于“多模态”与“Agent/AIOS”两个子项:美国在Agent层面的OpenAI、Anthropic、Microsoft已经形成了“模型即服务+自主操作”的闭环,而中国的PPIO Agent云、Manus、扣子Coze仍处于早期跑马圈地阶段。换句话说,模型能力的差距在缩小,但将模型封装为智能体的产品化能力,中美之间还有半代左右的时差。 请在微信客户端打开 RAG和AI Infra这一层尤其耐人寻味。美国有LangChain、Pinecone、Databricks、Snowflake这些成熟的中间件和数据库厂商,它们构筑了从模型到应用的桥梁。中国的硅基流动、LlamaIndex China、LangChain中文社区虽然在功能上快速跟进,但更多是“跟随式创新”或本地化适配,尚未形成类似Snowflake那样估值百亿美金的基础设施标准。这里的问题不在于技术实现,而在于生态位——美国企业更早意识到“模型会商品化,而数据管道和检索系统才是护城河”,中国企业则长期将注意力集中在模型本身,直到2025年才开始大规模补课。 下游的应用层,双方的风格差异骤然放大。美国在办公(Microsoft 365、Notion、Google)、搜索(Google、Perplexity)、客服(Salesforce、Zendesk)等传统软件领域叠加AI能力,走得是“存量升级”路线。机器人领域Tesla的Optimus、Figure和Boston Dynamics则代表了硬件与AI的极限结合。中国这边,办公软件金山办公、钉钉、飞书的AI化同样迅速,但更引人注目的是机器人赛道——宇树科技、UBTECH、智元机器人在消费级和工业级机器人上的出货量已经形成规模优势,这与珠三角的硬件供应链密不可分。医疗和金融领域,讯飞医疗、蚂蚁集团、同花顺等企业深耕本土场景,但全球化程度有限。需要指出的是,中国的“AI硬件”(小米、华为、Rokid)被单独列为一类,这反映出一种不同于美国的变现逻辑:在美国,AI收费主要通过API调用和SaaS订阅实现;在中国,除了API和SaaS,AI能力还通过智能眼镜、AI手机、AI音箱等硬件载体触达用户。这种“软硬一体”的打法在B端行业解决方案中同样存在——华为、浪潮提供私有化部署,科大讯飞、商汤主打垂直行业,而美国对应的Palantir、IBM、C3.ai则更多面向政府和大型企业的高客单价市场。 全景图末尾总结的中美优势对比,值得反复推敲。中国被标注的优势包括“AI应用落地速度快”“成本控制能力强”“ToB行业方案丰富”“本地化部署能力强”“AI+硬件供应链完整”“Agent平民化”。美国的优势则是“顶级GPU领先”“基础模型能力强”“AI科研能力领先”“开源生态技术领先”“AI Infra标准制定者”“全球开发者生态”。这些标签大体公允,但有一个隐藏的维度没有被明确写出:资本和市场的成熟度。美国企业可以从风险投资到IPO的完整链条中获得长期耐心资本,容忍基础研究的长周期;中国企业则更依赖应用端的快速反馈和规模化收入来反哺研发。这不是优劣之分,而是不同土壤长出的不同物种。 真正决定未来五年格局的,是全景图右下角那句判断:“从‘谁模型最强’变成‘谁能把GPU→模型→Agent→应用→企业收入这条链打通’。平台化、生态化、场景化的公司将成为最终赢家。”仔细拆解这条链条,会发现中美两国的“堵点”完全不同。美国的堵点在于成本:虽然模型强、算力足,但单次推理成本仍然偏高,Agent在执行多步任务时的token消耗让中小企业望而却步。中国的堵点在于模型能力上限:尽管DeepSeek等模型在特定评测上追平甚至超越GPT-4o,但在复杂推理、长上下文理解和指令遵循的稳定性上,顶尖水平仍有细微差距。然而,中国企业在成本控制上的激进策略(例如通过MoE架构和推理优化把价格打到OpenAI的十分之一)正在倒逼全球市场降价,这反过来又加速了Agent应用的普及。 一个容易被忽视的趋势是“Agent平民化”。2025年下半年开始,无论是美国的OpenAI Operator还是中国的Manus、扣子Coze,都在尝试让非技术用户通过自然语言构建自动化流程。这意味着AI产业链的价值重心正在从训练侧向推理侧、从模型提供商向Agent平台迁移。上游的GPU厂商或许不会失去定价权,但下游的应用场景会变得更加碎片化和长尾化。全景图中代表“最后”那一栏的API、SaaS、AI收费、私有化部署、行业解决方案、AI硬件——六种变现路径同时存在,说明没有哪家公司能够垄断整个链条。即使是NVIDIA,也在通过DGX Cloud和AI Enterprise软件试图向上游延伸;而OpenAI推出API后又做Operator Agent,再往下游走,难免与自己的客户产生摩擦。 回到中美对比的起点。2026年的AI产业不再是简单的“美国创新、中国跟随”的线性叙事。在机器人、AI硬件、成本优化、本地化部署这些领域,中国已经走出了自己的节奏。而在基础模型、AI Infra、全球开发者生态这些需要长期积淀的环节,美国仍然保持领先。全景图真正的价值不是给出一个胜负结论,而是提醒所有人:当产业链被拆解为上游、中游、下游、变现四个层级后,没有哪个国家能在所有层级同时占据优势。赢家不会是某一个国家,甚至不会是某一家公司——而是那些能够在不同层级之间建立高效转化漏斗、并且能把技术溢价转化为可持续收入的实体。无论是西雅图的云巨头还是深圳的机器人初创,最终都要回到同一个问题:你手里握着GPU算力、模型权重、Agent框架还是行业合同?以及,你能否把它们串成一根牢固的链条? 请在微信客户端打开 |
