夜雨聆风
夜雨聆风
当 AI 读不懂你精心设计的网页--人类与 AI 的「信道之争」
我最近在帮朋友设计一个处理业务文书的skill,整个流程并不复杂,但是涉及到从多个网站上获取信息,按照模版形成文书初稿.顺带还要把一个现有的word文档按照模版进行重排版
在编写的过程中,我发现两个非常别扭的事实:
• 很多我们人类浏览起来很简单直接的网站, 因为没有 API,或者网站自己的 MCP 工具,我只能模拟浏览器操作,将内容爬下来之后再采集.明明人类可以在3-4 步内完成的操作, AI 做起来却要复杂的多,元素的定位,点击搜索后结果的确认,等待详情页的加载.. • word排版更是灾难,按理说只要人在写word的时候,每个样式都按照模版里的规定来使用,比如文章标题的样式就叫总标题, 一级标题的样式就使用标题 1,排版工作就非常的简单. 但是实际在使用的时候,我发现有人把文章标题的样式定义为加粗的正文,有人把二级标题定义为段落. 我和朋友吐槽说,这样不行,要不你们干脆写markdown算了....
我不禁在想,人类过去几十年设计的信息载体,本来就不是为机器读取设计的。那么人和 AI 在处理信息方面,到底区别是什么呢? 我做了进一步的研究.
人类信道带宽的真正度量单位:组块

信息论里衡量信息量用比特(Bit)。但在人类的认知系统里,比特是一个不相关的物理单位。我们的意识不处理比特,处理的是组块(Chunk)。什么是组块?组块是一个"语义单位"。它并没有严格的度量单位和度量方法,数据量完全由接收者的背景知识决定。我们用一个英文单词来举例:
1 A-P-P-L-E
对于一个不认识英文的人来说,这是 5 个组块(5 个字母逐一解码)。对于一个认识英文的人来说,这是 1 个组块(Apple 作为一个整体语义)。
同一个字符串,认知负载可以相差 5 倍。差距的来源只有一点:接收者是否具备把零散信号打包成一个组块的经验。
这是人类认知系统最核心的机制:组块化(Chunking)。
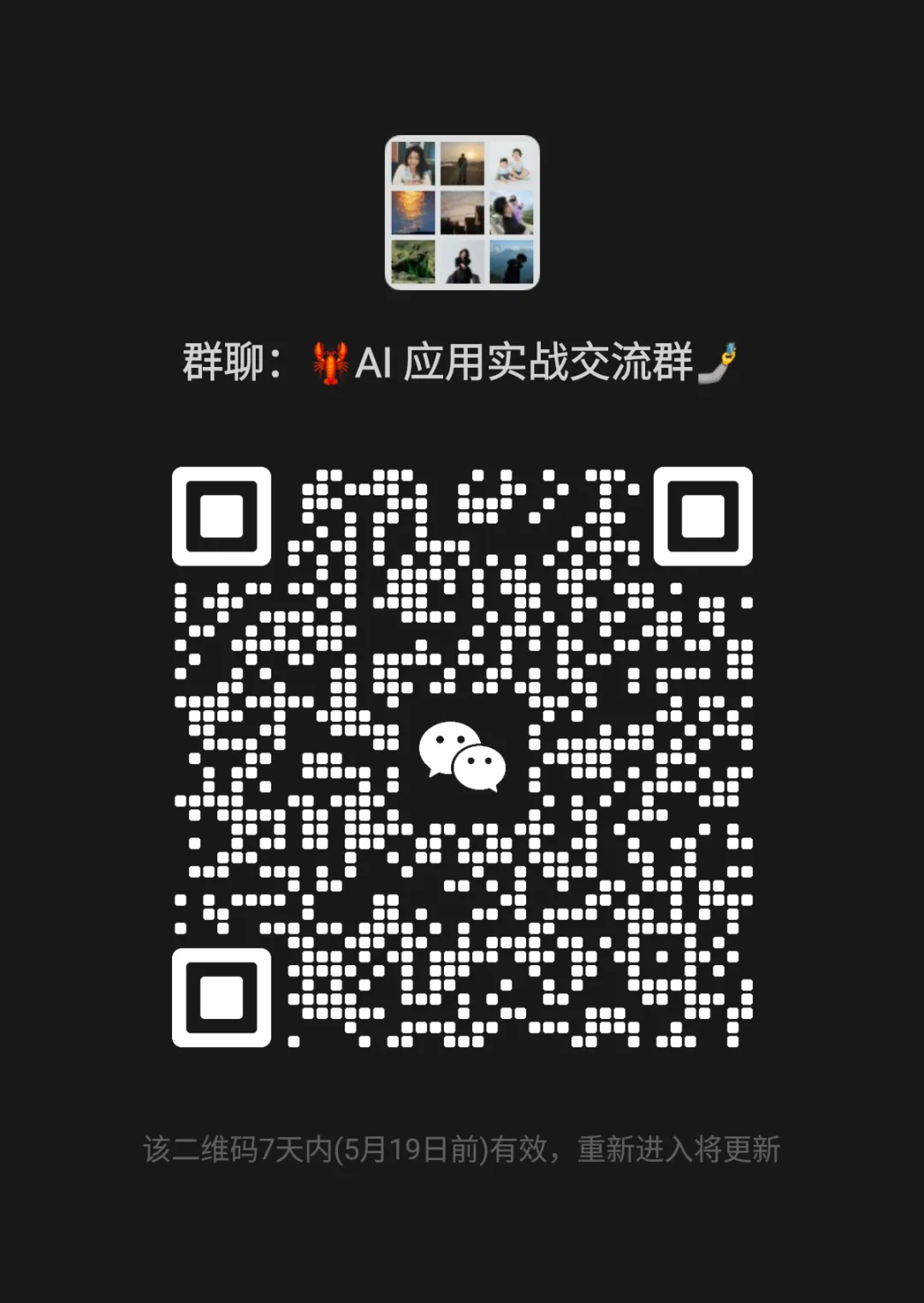
7±2 的物理墙
Miller(1956):人类短时记忆能同时处理约 7±2 个信息单元。Cowan(2001)将这个数字进一步收紧到了 3 到 5 个。
这就是人类认知信道的物理带宽。极窄。
为了在这条窄信道上传递更多信息,人类进化的核心方向就是不断提高每个组块的信息压缩比。想一想,中国的古代成语,现代互联网上的"梗",其实都是人类对信息进行压缩,从而提高处理效率的手段. 我们惊叹古人的智慧和现代人的"造词"能力,却没意识到之所以这些压缩后的信息能够被快速的传播,除了其本身携带的信息之外,他的便携性(高压缩比)在传播中也起了关键作用.
当压缩比呈现指数级变化时,我称之为语义坍缩(Semantic Collapse):把多个维度、多个层级的碎片信息,瞬间聚合成一个高阶结论的过程。
人类使用网页和 Word 时,并不是逐像素、逐标签、逐样式地读取。我们看到的是被经验压缩后的组块:一个醒目的按钮、一个标题层级、一块表格区域、一段正文。问题在于,这些组块很多并没有被显式写进系统结构里,只存在于人的经验中。
语义坍缩与隐性信息:以一副名为"午后的等待--少女与猫"的油画为例

我们用一个例子来说明到底什么是"语义坍缩", 你先读一段话:
如果你来过 XX 市的 XX 老街, 你一定会记得在 XX 广场的东南角坐落着一间经营了数年的咖啡馆,小小咖啡馆临街,墙壁上挂满了藤蔓。咖啡馆的主人为了方便周边客人驻足,在街边划出一片区域,布置了几张圆桌和靠背椅. 这是一个夏日的午后,一名约莫 20 岁出头的少女安静的坐在其中一张圆桌旁,女孩面前的桌子上放着一杯热气腾腾的咖啡,空气中弥漫着咖啡浓郁的香气。少女穿着一件浅色的碎花连衣裙.一只猫咪慵懒的躺在桌子的另一侧,少女一遍遍轻抚猫咪的身体,猫咪打着哈欠。少女望向街对面,眼神里充满了期待,空闲的手反复的揉搓着自己的发梢. 好像在等待什么人的出现.
阅读这段文字大概需要 10 秒,人类在阅读时其实是在玩一种“跳跃游戏”。我们的视觉并不是平滑扫过文字,而是在不停地进行扫视(Saccades),像快进镜头一样直接跳过那些没用的废话,然后精准地定格(Fixations)在关键信息点上,通过短暂停留来抓取含义。这种“块状采集”配合大脑强大的“自动补全”功能,让我们产生了一目十行的错觉。但无论你跳得再快,文字依然需要大脑按照逻辑先后去解码符号,再像拼图一样拼出画面。这就像在看一场极速播放的幻灯片,节奏再快,它本质上还是一个序列化的动作,没法像看图那样实现一瞬间的全局感知。
现在,想象你看到的是一幅彩色照片。镜头从少女对面 10 米外拍摄,前面文字里描绘的所有元素都在画幅内。
你在一瞬间就能看到阳光透过藤蔓洒在桌面上的温暖色调、少女低垂的目光和轻抚猫咪的姿态、猫咪半眯着眼睛的慵懒。视觉系统在毫秒级内同时捕获所有这些信号。所有要素在进入意识前已经在潜意识层完成了语义坍缩。你得到的是一个名为“慵懒与希冀”的单一组块,跟“阳光+藤蔓+少女+猫咪+咖啡”那堆素材清单完全不同。
上面这段大约200个字、耗费人类 10 秒才能传达的意象,图像在 0.1 秒内就完成了传递。图像利用空间布局,让信息在极窄的信道里实现了超高密度的瞬时传输。
隐性信息:比"画了什么"更深一层
但图像的能力不止于此。
画面中少女和猫咪占据中心位,光线聚焦在指尖与猫背上。构图告诉你:这是场景的灵魂,其他藤蔓和桌椅只是背景。同时整个画面的颜色以暖色为主,打哈欠的猫咪和安静的少女又给了你强烈的舒适,惬意的感觉. 这些在图片背后传达的信息就是隐性信息.
隐性信息的核心:看的不只是“画了什么”,更要看“画面传达了什么含义”。
人类之所以能瞬间秒懂“隐性信息”,是因为大脑运行着一套比语言逻辑更古老的“生理直觉”。当我们看到暖色调或中心构图时,并不是在进行理性推导,而是触发了基因里的生存本能与情感共振。大脑中的镜像神经元会让我们在看到猫咪打哈欠时,自动模拟出那种松弛感,实现感官上的“感同身受”。这种处理方式是并行的、全方位的,它跳过了符号解码的过程,直接将光影和色彩转化为安全、舒适或期待的情绪信号。说白了,读文字是“脑力活”,需要按部就班地拼凑;而读懂画面的暗示则是“本能反应”,是身体在感官层面与环境发生的直接共鸣。
AI: 我看不懂你们人类设计中的隐性信息
基于前面的语义坍缩和隐性知识,你就不难理解为什么我们的信息渠道:网站和应用要如此大费周章的做交互和视觉设计了: 设计师通过位置调整——重要的放左上角或视口中心;通过局部放大——大字号、高对比色、动效吸引注意力;通过分组和留白——相关元素聚在一起、不相关的拉开距离。整个视觉系统在帮你的眼睛走一条最短路径,让你扫一眼就能判断"这里最重要"、"这是操作入口"、"先看这里再看那里"。
我们人类已经习惯了这一套视角表达系统,并且习以为常. 那么, 换做 AI 呢?
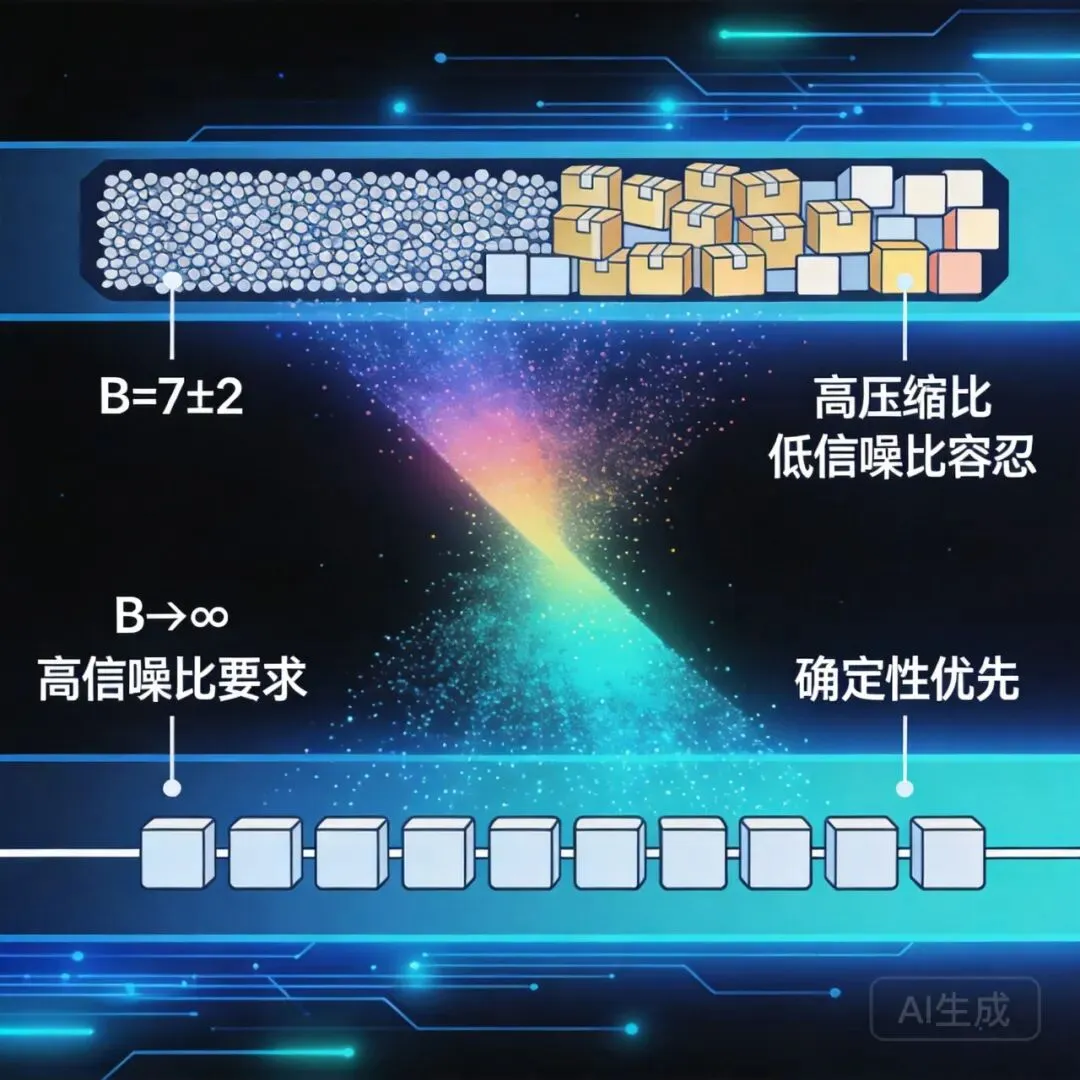
AI 不是完全看不懂,而是它对这些隐性暗示的理解不稳定、不可验证、难以自动转化为可靠操作.AI 解析网页时,在一个全平的逻辑空间里扫描,无法自动感知人类设计的任何视觉捷径。
AI 能理解的(显性逻辑)
• DOM 树结构:节点之间的父子关系、层级嵌套 • 文本内容:HTML 标签内的硬编码文字 • 元数据与属性:id、class、alt 标签、ARIA 无障碍说明 • 显式逻辑:超链接指向,按钮绑定的脚本函数
以上这些,AI 处理得很好。这些是"拆好的零件",每一个标签、属性、节点都是结构化的逻辑锚点。
AI 无法理解的(隐性暗示)
视觉权重。一个红色 32px 的按钮,在 AI 眼里只是 color: #FF0000; font-size: 32px;。它无法直接从颜色和尺寸的组合中感知到"绝对优先级"。人类看到红色按钮会本能地意识到"这里最重要",AI 需要显式的权重标注才能确认。
视觉引导的意图。人类用“留白”突出核心功能,用"深色模式"营造沉浸感。对 AI 来说,留白只是空白像素。它无法理解设计者通过牺牲空间来换取注意力聚焦的策略。
审美带来的信任背书。人类会因为一个网站排版精美、配色和谐而产生"专业、可靠"的预判。AI 对美学毫无感知。
冲突的核心:网页的 GUI 是人脑的语义坍缩加速器,充满只有人能识别的隐性暗示。AI 作为一个纯逻辑解析器,在这些暗示面前是盲目的。
香农极限:为什么错位不可持续
香农信道容量公式:C = B log2(1 + S/N)。
C 是最大信息传输速率,B 是带宽,S/N 是信噪比。
人类这一侧:B 极低,7±2 个组块。为了在这条窄信道上传递信息,人类走了两条路。第一,组块化--把一个语义组的压缩比不断推高,A-P-P-L-E 打包成 Apple,150 个字的场景坍缩成一幅视觉画面。第二,接受低信噪比--模糊、隐喻、隐性暗示、直觉补偿、缺字不影响理解。窄带宽,高压缩容忍,低信噪比容忍。
AI 这一侧:B 几乎无限,百万级 Token 上下文。但它对信噪比的要求比人类要高。AI可以忍受噪声,但是当任务从“理解大意”进入“稳定执行”时,混在在信息里噪声会迅速变成成本和风险
现在,我们已经有了一组清晰的对比:
• 人类:窄信道(7±2)、更喜欢能够高度浓缩信息的图片,视频,图表 • AI:宽信道、逻辑解析能力强、确定性优先、更喜欢信噪比高的文字信息
所以我们会得出一个结论: 目前这套给人类使用的信息渠道对 AI 是不适用的. 二者有着严重的错位. 于是就出现了AI 为了适配人类的信息渠道和信息载体的尝试:网页抓取是在给 AI 做噪声过滤,提高 S/N。视频抽帧是在把非结构化数据变成结构化 Token 流。docx 解析是在剥离排版噪声,保留内容信号。RAG 分块是在长文档中建立索引,降低检索成本。
这些工程本质上都是同一个动作:信道适配。
短期的趋势:人类向 AI 靠拢
原因不再需要复杂的论证了--公式已经说清楚了。
AI 对信噪比的要求是一个硬约束。它不会因为人类的设计偏好而降低。所以未来 3 到 5 年,人类的信息基础设施必须向 AI 的舒适区间靠拢。这已经不是可选项了。
例如:
网站:从 GUI 单通道变为 GUI+(MCP,API,结构化页面描述..)的双通道机制
弹窗、广告、复杂的 CSS 布局,对人类是用户体验,对 AI 是垃圾信息。未来,没有 API 的网站会失去 AI 流量入口。Headless CMS 和 Agent-friendly 的接口会成为标配。无法被 AI 感知的网站等于不存在。
文档:信息层和表现层分离
Word文档的问题不在 Word 本身,而在用户把“看起来像标题”和“结构上是标题”混为一谈。人眼能靠字号、加粗和位置完成语义坍缩;AI 需要的是明确的结构标签。
Word把内容和排版焊死在一起。未来的文档格式会走 Markdown 加独立渲染引擎的路线。内容归内容,样式归样式。人类看渲染后的漂亮页面,AI 直接读内容层。最近 Anthropic 又引发了 HTML 替代 Markdown 的话题, 但是我觉得 HTML 也好,PDF 也好,DOCX 文档也好,本质还是展示, 但是底层的信息层不会变,无论是json, yaml,亦或是更贴合人类自然语言的markdown.信息层和表现层一定会分离.
视频网站“去黑盒化”
首先,平台在架构上强推结构化锚点,比如自动章节拆分和多语种实时字幕,这本质上是给视频建立了一份精准的语义索引。其次,视频不再被视为单一文件,而是被拆解为海量的特征向量。通过视觉识别技术,视频里的物体、场景甚至是背景文字(OCR)都会被自动打上标签,存入AI可检索的数据库。
最关键的设计转变在于元数据的深度关联。现在的后台系统会自动对齐画面、音频和文本,将原本模糊的感官信号转化为AI最擅长的逻辑序列。这种设计让AI不再需要盲目猜测,而是能直接定位到视频中某分某秒的具体细节。可以说,现在的视频网站更像是一个巨大的多模态知识库,所有的交互设计都在努力将非线性的视觉流,翻译成AI可处理的结构化逻辑。
长期:AI 会向人类靠拢吗
这既非退化也非进化,而是一场“认知维度的补完”。
这种补完并不是科幻构想,全球最顶尖的实验室正在通过 VLM(多模态大模型) 强行攻克这一高地。
现在的 AI 巨头们,正在为 AI 打造一层仿人类的“感官中间件”:
• OpenAI 的 GPT-4o 正在挑战“实时感官对齐”,让 AI 能直接通过摄像头读懂人类的手势、微表情和现场氛围,而不只是处理文字指令; • Google 的 Gemini 已经在尝试从长达数小时的原始视频中,直接定位并解析那些细微的、非结构化的动作特征; • NVIDIA 则通过具身智能(Embodied AI) 试图让 AI 在物理世界中学习——让它明白红色按钮之所以重要,是因为它连接着物理世界的反馈,而不仅是一个颜色标签。
这些努力证明了:短期三到五年,人类会主动改造基础设施(如网页、应用)去迁就 AI,把世界变得“AI 友好”;但长期来看,AI 必然会建立起对人类原生载体的第二套理解系统。
人类发明了文字也没丢掉口语,发明了图像也没丢掉文字。未来,AI 也会在保持数字逻辑内核的同时,外挂这层强大的感知系统。它不再只是“读”你的 JSON 字段,而是能像人类一样,去捕捉那些坍缩在生活细微处的隐性暗示。当 AI 真正看懂了那张咖啡馆照片里的午后阳光和少女眼神时,那才是人机关系真正有意思的时刻。
最后: 所谓人类与 AI 的信道战争,不是你死我活的格式之争,而是两套认知系统在争夺信息表达的默认结构。短期是人类世界结构化,长期是 AI 感知能力拟人化。