 夜雨聆风
夜雨聆风分片(Chunking)是 RAG 中投入产出比最高的优化环节——分片策略对了,不改模型、不换 Embedding,检索质量就能有明显提升。分片策略错了,后续的检索、重排序、Prompt 工程都是"垃圾进、垃圾出"。本文以 TMC 差旅财务知识库为业务背景,梳理五种主流分片方式,从最基础的一刀切到 LLM 驱动的智能分片。
一、为什么要分片
大模型有上下文窗口限制,不可能一次把整本《差旅管理制度》塞进去。RAG 的做法是:把文档拆成小文本块(chunk),检索时只取与问题最相关的那几个块,拼入 Prompt 交给 LLM。
分片是连接海量知识库和有限上下文窗口之间的关键桥梁。它直接影响:
• 检索精度:块太大→一个 chunk 含多个不相关主题,语义不聚焦,检索命中率低;块太小→关键上下文被切断,LLM 拿到的信息残缺 • 上下文利用率:块太小→需要召回更多 chunk 才能覆盖完整信息,消耗大量 token;块刚好→几个 chunk 就能回答,经济高效 • 生成质量:chunk 的语义完整性决定 LLM 看到的"上下文"是否自包含、可理解
术语说明:Chunking、Splitting、分段、分片、分块——都指同一件事,本文统一用"分片"。
二、固定大小分片:最简单的起点
2.1 原理
按字符数(或 token 数)固定切割,不管内容是什么。两个参数:
• chunk_size:每个块的字符/ token 数,一般 500-1000• chunk_overlap:相邻块的重叠字符数,一般 50-200
overlap 的作用是缓冲——固定切割必然在某个字符处切下,overlap 确保切点前后的内容在相邻块中都有出现,减少语义断裂。
2.2 TMC 示例
以 系统模块职责.txt 为例,chunk_size=150, overlap=5:
# 付款申请(PR)流程
## PR 的用途
PR(Payment Request,付款申请)用于以下场景:
1. 向供应商付款(多数以 EXS 开头的 supplierCode)
2. 员工报销(supplierCode 以 E 开头)
3. 退票产生的付款
## PR 状态流转
Raised(已提交) → Approved(已审批) → Paid(已付款)
已付款后的 PR 可以 Void(作废),需在 Detail 中写明原因。
## 操作标识
- 给客户的 PR:C Complete
- 给供应商的 PR:S Complete
## 供应商付款详细流程
1. 新增供应商,设置编号
2. 提交付款申请
3. 签字审批完成
4. AP(应付账款)根据付款申请做入账,PR 状态变更为 Raised
5. 审核后状态变更为 Approved
6. 出纳付款
7. AP 记录状态为 Paid
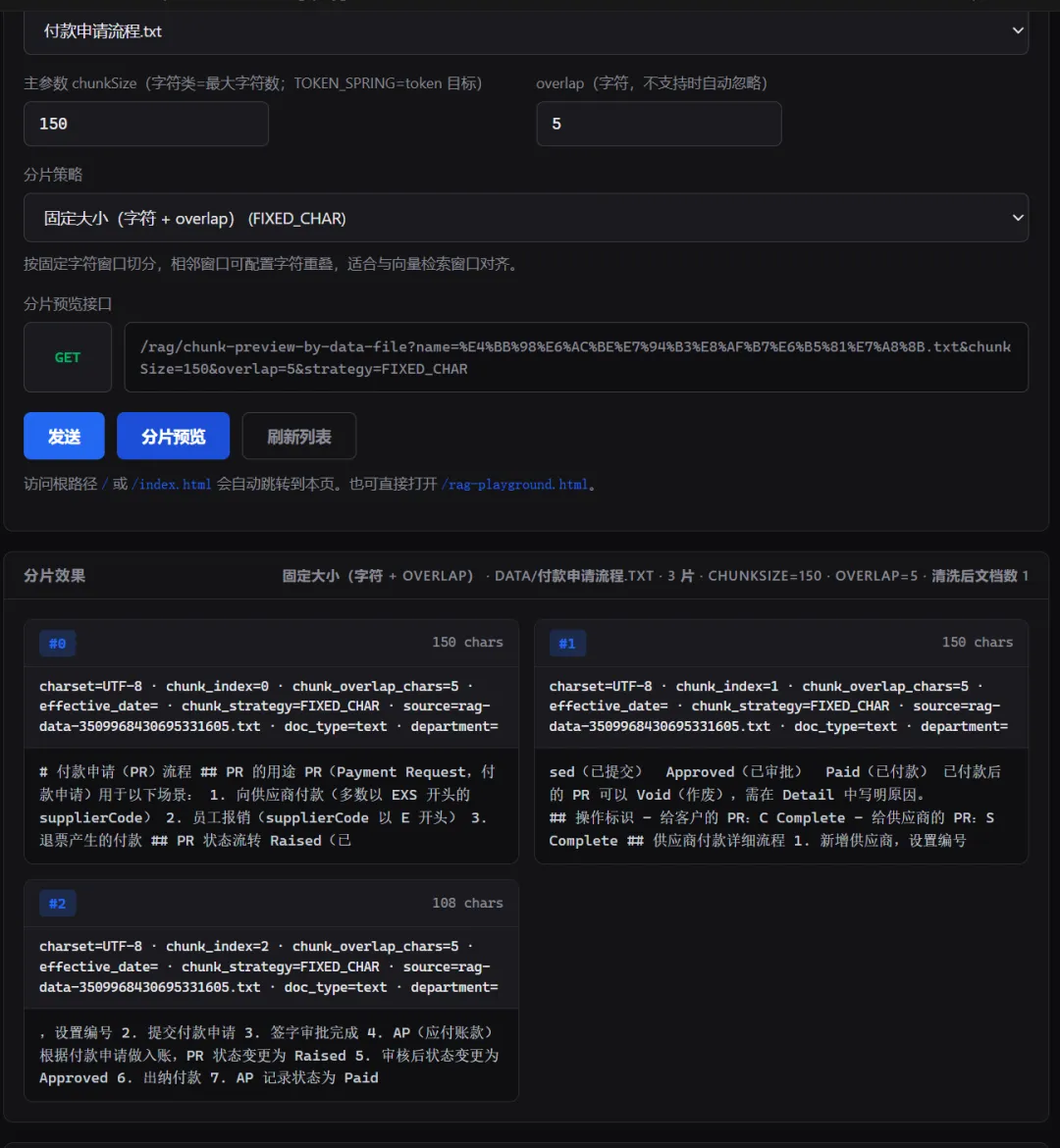
问题很明显: 连贯的内容被拦腰斩断。“## PR 状态流转 Raised(已” 被阶段,下一个分块到了“sed(已提交) Approved(已审批) Paid(已付款) 已付款后的 PR 可以 Void(作废),需在 Detail 中写明原因。”
2.3 优缺点
适用场景:仅适合快速原型验证和性能基线对比,不建议用于生产环境。
三、递归分片:最常用的生产选择
3.1 原理
指定一组分隔符,按优先级逐级尝试切分。只有当当前分隔符无法切出合格大小的块时,才降级使用下一个分隔符——这就是"递归"的含义。
// Spring AI Alibaba RecursiveCharacterTextSplitter 源码片段
publicRecursiveCharacterTextSplitter(int chunkSize, String[] separators) {
this.chunkSize = chunkSize;
this.separators = Objects.requireNonNullElse(separators,
newString[] { "\n\n", "\n", "。", "!", "?", ";", ",", " " });
}
privatevoidsplitText(String text, int separatorIndex, List<String> chunks) {
if (text.isEmpty()) return;
// 1. 如果文本已经够短,直接作为一个块
if (text.length() <= chunkSize) {
chunks.add(text);
return;
}
// 2. 所有分隔符都用完了还没切好,强制按 chunkSize 切割
if (separatorIndex >= separators.length) {
for (inti=0; i < text.length(); i += chunkSize) {
intend= Math.min(i + chunkSize, text.length());
chunks.add(text.substring(i, end));
}
return;
}
// 3. 用当前分隔符切分
Stringseparator= separators[separatorIndex];
String[] splits = text.split(separator);
// 4. 递归处理每个分段:够短的直接保留,太长的用下一个分隔符继续切
for (String split : splits) {
if (split.length() > chunkSize) {
splitText(split, separatorIndex + 1, chunks); // 递归
} else {
chunks.add(split);
}
}
}递归体现在:splitText 调用自身,分片太长时 separatorIndex + 1 切换到下一级分隔符。相当于"先用粗筛子,失败了用细筛子,再失败直接上刀"。
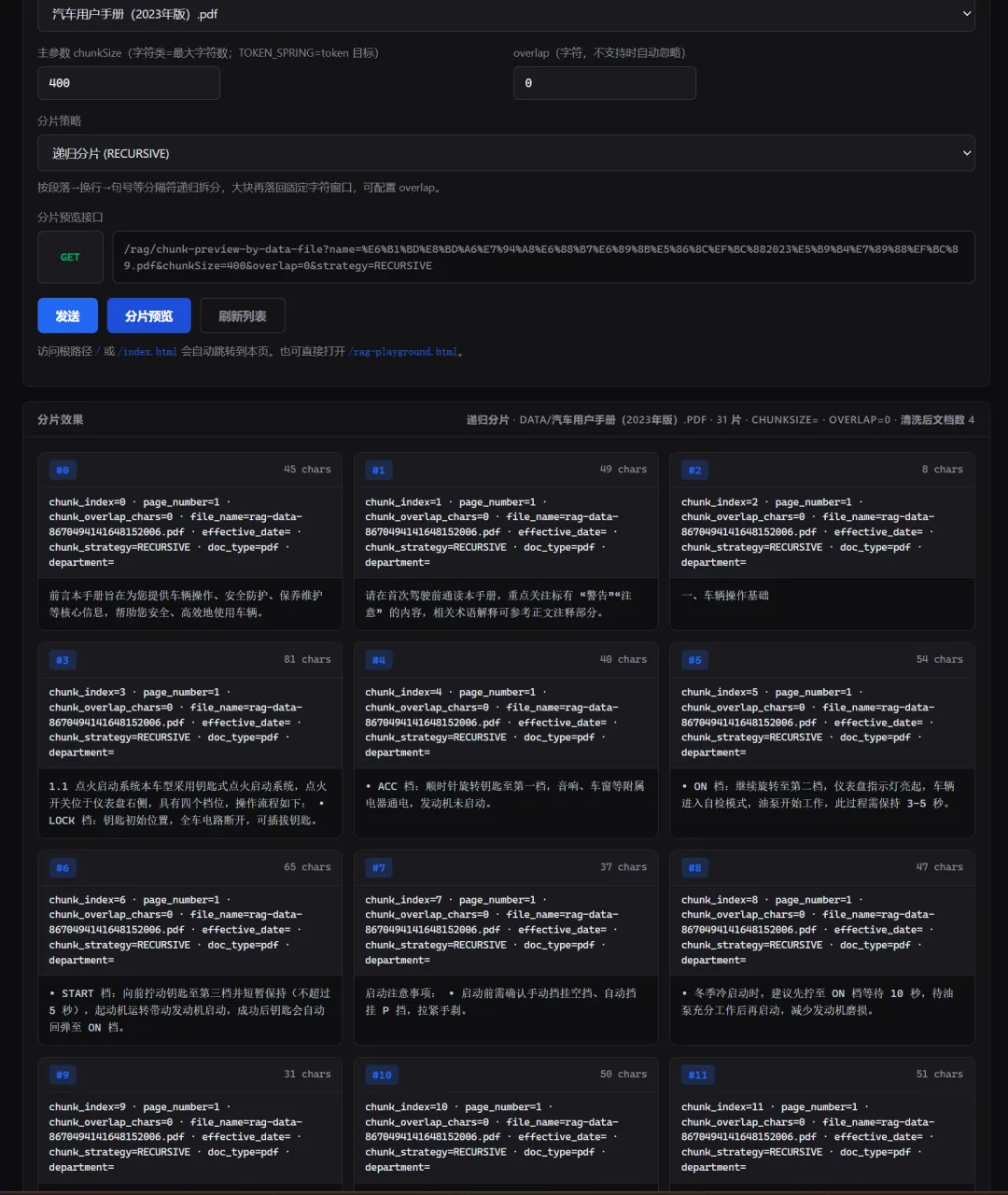
3.2 TMC 示例
同样 系统模块职责.txt,使用默认分隔符 ["\n\n", "\n", "。", "!", "?", ";", ",", " "],chunk_size=200:
切割结果:
Chunk 1:
"AR(应收账款)负责对账、生成 CreditNote(贷项通知单)、
收款管理、预付款管理。"
Chunk 2:
"AP(应付账款)负责供应商付款管理、员工报销管理、
付款申请(PR)管理。"
Chunk 3:
"GL(总账)负责手工账管理、系统账管理、科目维护、
报表生成。"递归分片优先在 \n\n(段落边界)切分,AR、AP、GL 各自独立成一个 chunk。用户搜"AR 的职责"时精准命中 Chunk1,不会混入 AP、GL 的内容。
3.3 为什么递归分片最常用
从主流平台的配置就能看出来:
| 百炼 | ||
| Dify | ||
| Coze |
三个平台的核心分片方案都是递归分片——实现简单、效果可预期、适配大部分文档类型。
四、基于文档结构的分片
4.1 原理
递归分片依赖通用分隔符,但 Markdown、HTML、代码等有结构标记的文档可以做得更精准——利用标题层级(#/##/###)、HTML 标签、代码语法树等结构信息在"天然边界"上切分。
4.2 Markdown 标题分片(TMC 推荐)
TMC 知识库的 5 份文档都是 Markdown 格式,按 ## 标题切分是最自然的选择:
付款申请流程.txt 的结构:
├── # 付款申请(PR)流程
│ ├── ## PR 的用途 → Chunk 1
│ │ ├── 1. 向供应商付款
│ │ ├── 2. 员工报销
│ │ └── 3. 退票产生的付款
│ ├── ## PR 状态流转 → Chunk 2
│ │ └── Raised → Approved → Paid → Void
│ ├── ## 操作标识 → Chunk 3
│ │ ├── C Complete(给客户)
│ │ └── S Complete(给供应商)
│ └── ## 供应商付款详细流程 → Chunk 4
│ └── 7 步详细流程按 ## 切分后,每个 chunk 包含一个完整的子主题,语义自包含。用户问"PR 的状态流转",Chunk2 被召回,内容完整独立。
4.3 HTML / 代码分片
对于公司 Wiki 上的差旅 FAQ(HTML)或自动化脚本文档(Python/JS),有专门的解析器:
// Spring AI MarkdownDocumentReader:按标题切分
MarkdownDocumentReaderConfigconfig= MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true) // 水平线也作为分片边界
.withIncludeCodeBlock(false) // 排除代码块
.withIncludeBlockquote(false) // 排除引用
.withAdditionalMetadata("filename", "付款申请流程.txt")
.build();# LangChain:HTML 标题分片
from langchain.text_splitter import HTMLHeaderTextSplitter
splitter = HTMLHeaderTextSplitter(
headers_to_split_on=[("h1", "h1"), ("h2", "h2"), ("h3", "h3")]
)
chunks = splitter.split_text(html_content)五、语义分片:感知主题边界
5.1 原理
前面的方式只看结构和字符数,不看语义。语义分片的核心思路:相邻句子如果语义相似,属于同一块;相似度陡降,就是切分点。
句子序列的语义相似度曲线:
S1 S2 S3 S4 S5 S6 S7 S8 S9 S10
████████████░░░░██████████████████░░░░░░░
↑ 都是PR用途 ↑切 ↑ 都是PR状态流转 ↑切实现方式有三种:
| Embedding 阈值 | ||
| NLP 句子分割 | SentenceDetectorME(最大熵模型)先拆句,再按语义合并 | |
| LLM 判断 |
5.2 TMC 示例
预存款与XO核销.txt 包含两个截然不同的主题:
原始文本:
"## 预存款来源
1. 超额支付(OverPayment):结算时付款金额超出发票金额的部分
2. 企业预付款:销售完成后的预付款余额
## 预存款用途
1. 后续差旅消费
2. 抵扣供应商 XO(Exchange Order,外部订单)"固定分块可能把两个主题塞进同一个 chunk(因为都不长)。语义分块则能识别 ## 预存款来源 和 ## 预存款用途 之间的语义跳变,在主题切换处切开,生成两个独立的、语义聚焦的 chunk——用户搜"预存款怎么用"时直接命中 Chunk2,不混入来源信息。
5.3 实际实现
// Spring AI / LangChain4J 中的语义分片核心实现
SentenceDetectorMEsentenceDetector=newSentenceDetectorME(sentenceModel);
String[] sentences = sentenceDetector.sentDetect(text);
// 将检测到的句子按 chunk_size 和语义相似度合并底层依赖 OpenNLP 的预训练句子模型(opennlp-en-ud-ewt-sentence-1.2-2.5.0.bin),基于最大熵模型判断句子边界。
六、LLM 驱动的智能分片
6.1 Agentic Chunking:让大模型做主
import com.example.rag.chunk.config.ChunkConfig;
import com.example.rag.chunk.config.LlmChunkConfig;
import com.example.rag.dto.ParamDescriptor;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.document.Document;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Component
publicclassLlmGuidedChunkStrategyimplementsChunkStrategy {
privatestaticfinalintMAX_PROMPT_CHARS=12_000;
privatestaticfinalPatternJSON_ARRAY= Pattern.compile("\\[\\s*\"(?:[^\"\\\\]|\\\\.)*\"(?:\\s*,\\s*\"(?:[^\"\\\\]|\\\\.)*\")*\\s*]");
privatefinal ObjectProvider<ChatModel> chatModelProvider;
privatefinalObjectMapperobjectMapper=newObjectMapper();
publicLlmGuidedChunkStrategy(ObjectProvider<ChatModel> chatModelProvider) {
this.chatModelProvider = chatModelProvider;
}
@Override
public String id() {
return"LLM_SMART";
}
@Override
public String label() {
return"LLM 智能分片";
}
@Override
public String description() {
return"调用已注册的 Spring AI ChatModel(如 DashScope)按提示词输出 JSON 字符串数组。overlapHint 在提示中作为软约束,不保证严格字符重叠。";
}
@Override
public Class<? extendsChunkConfig> configType() {
return LlmChunkConfig.class;
}
@Override
publicbooleansupportsOverlap() {
returntrue;
}
@Override
public List<ParamDescriptor> parameters() {
return List.of(
newParamDescriptor("chunkSize", "分片大小(字符)", "int", 400, 200, 12000,
"LLM 分片的软约束目标字符数"),
newParamDescriptor("overlapHint", "重叠提示(字符)", "int", 0, 0, 500,
"LLM 上下文延续软约束,不保证严格字符重叠"),
newParamDescriptor("temperature", "LLM 温度", "double", 0.3, 0, 1,
"LLM 生成随机性,越低越确定,0 为确定输出"));
}
@Override
public List<Document> split(List<Document> documents, ChunkConfig config) {
LlmChunkConfigcfg= (LlmChunkConfig) config;
ChatModelchatModel= chatModelProvider.getIfAvailable();
if (chatModel == null) {
thrownewIllegalStateException("未检测到 ChatModel Bean(需配置 spring.ai.dashscope 等),无法使用 LLM 分片");
}
Stringfull= ChunkTextMerge.joinText(documents);
if (full.isEmpty()) {
return List.of();
}
intapprox= cfg.chunkSize();
intoverlap= cfg.overlapHint();
doubletemperature= cfg.temperature();
Stringbody= full.length() > MAX_PROMPT_CHARS ? full.substring(0, MAX_PROMPT_CHARS) : full;
booleantruncated= full.length() > MAX_PROMPT_CHARS;
SystemMessagesystem=newSystemMessage(
"You are a text segmentation assistant for RAG. Output ONLY a valid JSON array of strings. "
+ "Each string is one chunk. Chunks should be coherent topics. "
+ "Target about " + approx + " characters per chunk when possible. "
+ "If overlap is requested (" + overlap + "), let neighboring chunks share contextual continuity where natural. "
+ "No markdown fences, no commentary.");
UserMessageuser=newUserMessage("Document:\n" + body);
// NOTE: 如需将 temperature 传递给 ChatModel,可在此处通过 Prompt(Builder).chatOptions(...) 配置
Promptprompt=newPrompt(List.of(system, user));
Stringraw= chatModel.call(prompt).getResult().getOutput().getText();
List<String> pieces = parseChunks(raw);
if (pieces.isEmpty()) {
pieces = List.of(body.strip());
}
Map<String, Object> base = baseMeta(documents);
base.put("llm_chunk_overlap_hint", overlap);
base.put("llm_temperature", temperature);
base.put("llm_input_truncated", truncated);
return ChunkTextMerge.annotateIndices(ChunkTextMerge.fromTextPieces(pieces, id(), base));
}
private List<String> parseChunks(String raw) {
if (raw == null || raw.isBlank()) {
return List.of();
}
Stringtrimmed= stripCodeFence(raw.trim());
try {
return objectMapper.readValue(trimmed, newTypeReference<>() {
});
} catch (Exception ignored) {
Matcherm= JSON_ARRAY.matcher(trimmed);
if (m.find()) {
try {
return objectMapper.readValue(m.group(), newTypeReference<>() {
});
} catch (Exception ignored2) {
// fall through
}
}
}
returnnewArrayList<>();
}
privatestatic String stripCodeFence(String s) {
if (s.startsWith("```")) {
inti= s.indexOf('\n');
if (i > 0) {
s = s.substring(i + 1);
}
intj= s.lastIndexOf("```");
if (j > 0) {
s = s.substring(0, j).trim();
}
}
return s;
}
privatestatic Map<String, Object> baseMeta(List<Document> documents) {
Map<String, Object> md = newLinkedHashMap<>();
if (!documents.isEmpty()) {
md.putAll(newLinkedHashMap<>(documents.get(0).getMetadata()));
}
return md;
}
}把整篇文档交给 LLM,让它自主判断在哪些位置切分,并为每个块生成标题:
本手册旨在为您提供车辆操作、安全防护、保养维护等核心信息,帮助您安全、高效地使用车
辆。请在首次驾驶前通读本手册,重点关注标有 “警告”“注意” 的内容,相关术语解释可参考正
文注释部分。 一、车辆操作基础
1.1 点火启动系统
本车型采用钥匙式点火启动系统,点火开关位于仪表盘右侧,具有四个档位,操作流程如下:
• LOCK 档:钥匙初始位置,全车电路断开,可插拔钥匙。
• ACC 档:顺时针旋转钥匙至第一档,音响、车窗等附属电器通电,发动机未启动。
• ON 档:继续旋转至第二档,仪表盘指示灯亮起,车辆进入自检模式,油泵开始工作,此
过程需保持 3-5 秒。
• START 档:向前拧动钥匙至第三档并短暂保持(不超过 5 秒),起动机运转带动发动机
启动,成功后钥匙会自动回弹至 ON 档。
启动注意事项:
• 启动前需确认手动挡挂空挡、自动挡挂 P 挡,拉紧手刹。
• 冬季冷启动时,建议先拧至 ON 档等待 10 秒,待油泵充分工作后再启动,减少发动机磨
损。
• 若连续两次启动失败,需间隔 15 秒后重试,避免损坏蓄电池。
1.2 驾驶舱核心控制
• 方向盘按键:左侧控制定速巡航,右侧调节音响音量、切换曲目及接听蓝牙电话。
• 空调系统:物理旋钮调节温度与风量,按键控制内外循环、除雾功能,冬季除霜需开启 AC
模式配合热风。
• 挡位操作:自动挡车型配备传统电子挡把,P 挡锁止需踩下刹车解锁,行驶中禁止直接切
换至 R 挡或 P 挡。 二、安全防护系统
2.1 被动安全配置
全车配备前排双安全气囊、侧气囊及帘式气囊,气囊触发需满足碰撞强度≥30km/h 且角度在
±30° 范围内。前排安全带具备预紧功能,身高 145cm 以下乘员需配合儿童安全座椅使用,安
装位置仅限后排座椅。
2.2 主动安全提示
车辆配备 ABS 防抱死系统与 EBD 制动力分配系统,紧急制动时需持续踩下刹车踏板,系统
会自动调节制动力。雨天行驶需开启 ESP 车身稳定系统,按键位于挡把左侧。 三、驾驶与保养规范
3.1 驾驶操作指南
• 冷车启动后无需长时间怠速热车,怠速 30 秒至 1 分钟待转速稳定后即可行驶,水温未达
正常范围(80-90℃)时避免急加速。
• 城市道路行驶保持与前车 2 秒以上车距,高速公路增至 4 秒,雨雪天气需加倍并降低车速
至 60km/h 以下。
• 手动挡车型换挡时需将离合器踩到底,时速 20km/h 以下使用 1-2 挡,40km/h 以上切换至
3-4 挡,避免低速高挡导致积碳。
3.2 定期保养要求
• 机油更换周期为 5000 公里或 6 个月,推荐使用 5W-30 标号全合成机油,更换时需同步更
换机油滤芯。
• 轮胎每月检查一次胎压(标准值 2.3-2.5bar),每 1 万公里进行交叉换位,胎纹深度小于
1.6 毫米时必须更换。
• 蓄电池使用寿命约 3-5 年,若出现启动无力、灯光变暗等现象,需及时更换原厂蓄电池。 四、紧急情况处理
4.1 启动故障排查
• 钥匙拧至 ON 档无反应:检查蓄电池接线柱是否松动氧化,可用热水冲洗氧化物后紧固。
• 启动时起动机异响:立即停止操作,检查钥匙是否完全插入,若问题持续需联系售后检
修。
4.2 轮胎更换流程
1. 将车辆停至平坦路面,开启双闪灯并放置三角警示牌(距离车后 50-150 米)。
2. 用千斤顶顶起车身至轮胎离地 2-3 厘米,拆卸轮毂螺丝时遵循 “对角顺序”,安装备胎后需
将螺丝分次拧紧。 五、技术参数
• 发动机:1.5L 自然吸气,最大功率 85kW,峰值扭矩 148N・m。
• 悬架系统:前麦弗逊式独立悬架,后三连杆独立悬架。
• 燃油经济性:综合油耗 6.2L/100km,油箱容积 52L。
(注:文档部分内容可能由 AI 生成)优点:语义完整性最好,分片结果自带标题,后续用标题做 embedding 能大幅提升检索命中率。
缺点:每次分片需要 LLM 调用,成本高、速度慢。适合一次性构建知识库的离线预处理阶段,不适合实时文档。
6.2 Proposition Chunking:拆成原子事实
更进一步的方式——不是按主题分块,而是把文本拆成不可再分的原子事实,每个事实是一个独立的 chunk:
每个 Proposition 都是独立、自包含的事实陈述。检索时粒度最细,精确度最高。代价是 LLM 调用量大,chunk 数量爆炸。
效果还是不错的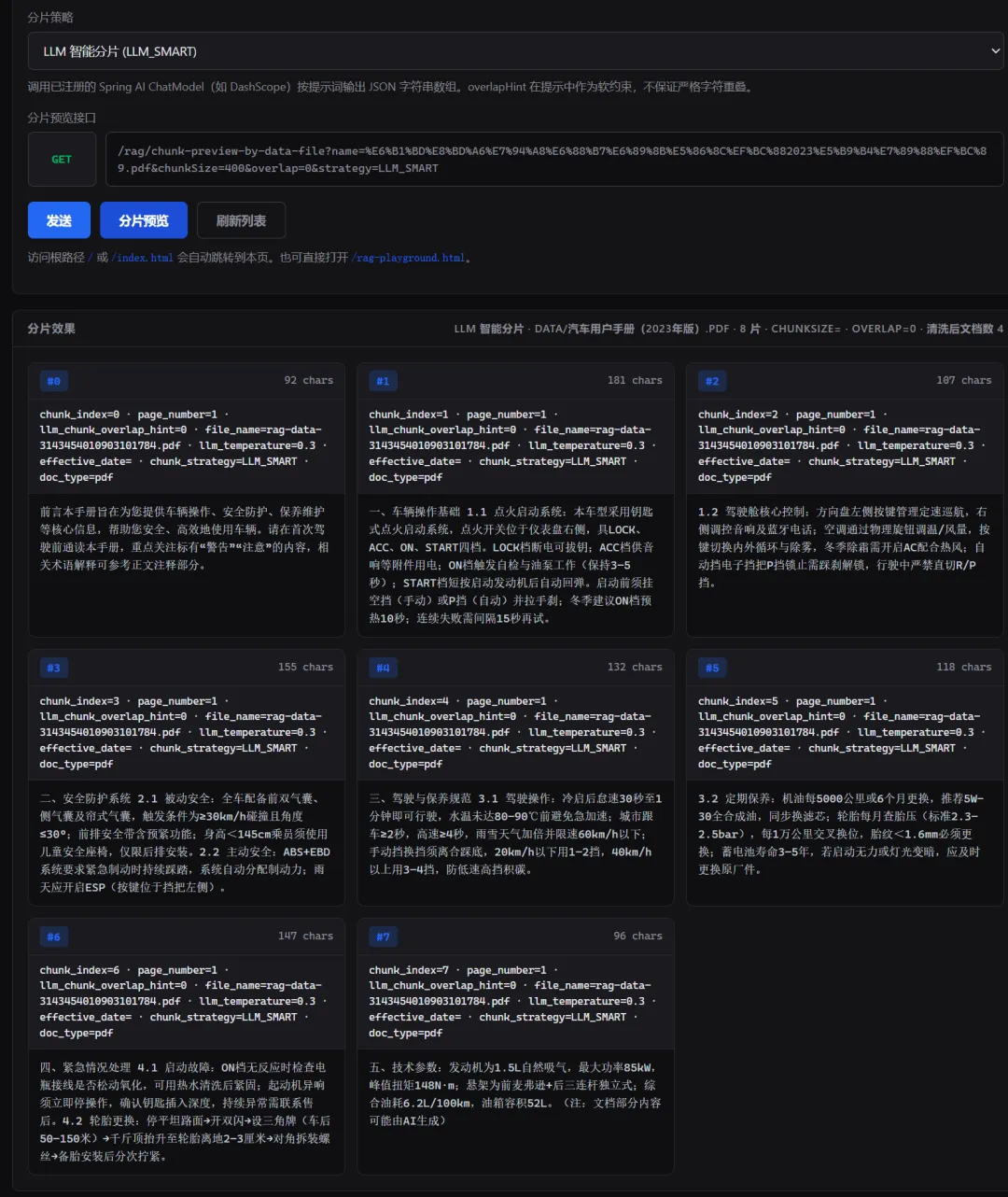
七、五种分片方式对比
| 固定大小 | ||||
| 递归分片 | ||||
| 文档结构分片 | ||||
| 语义分片 | ||||
| LLM 智能分片 |
选择建议:大部分 TMC 场景用"文档结构分片(按 H2) + 递归分片兜底"即可。只有政策类长文档需要叠加语义分片。LLM 分片适合在初始构建时跑一次,后续增量更新用结构分片。
八、分片后的下一步
分片不是终点。分完的 chunk 要真正好用,还有两个关键增强:
8.1 语境增强(CCH)
chunk 存入向量库后是孤立存在的——丢失了"我来自哪"的上下文。在每个 chunk 前预置文档级信息:
原始 Chunk:
"- 供应商付款管理
- 员工报销管理"
CCH 增强后:
"[文档:系统模块职责 | 章节:AP(应付账款)]
- 供应商付款管理
- 员工报销管理"8.2 父子分片(Hierarchical Chunking)
Dify 等平台支持的"父子分段":文档先按大粒度(如 H2)切成"父块",每个父块内部再按小粒度(如段落)切成"子块"。检索时用子块做精准匹配,但返回给 LLM 的是完整的父块上下文。
父块(H2 层级):
"## AP(应付账款)
供应商付款管理、员工报销管理、付款申请(PR)管理"
子块(小粒度):
"员工报销管理"(供检索匹配用)检索命中子块 → 向上找到父块 → 将完整父块拼入 Prompt。这种"子检索、父返回"的模式兼顾了检索精准度和上下文完整性。
九、总结
1. 固定分块是玩具:验证流程可用,但生产不要用 2. 递归分块是主力:简单、可靠、三大平台都在用,适合大多数场景 3. 结构分块是进阶:Markdown/HTML 文档优先用标题层级分片,TMC 知识库的最佳选择 4. 语义分块是补充:长政策文档用语义边界避免主题混杂 5. LLM 分片是未来:一次投入,语义完整性无可匹敌,但目前成本偏高
对 TMC 差旅财务系统而言,文档都是 Markdown 格式、结构清晰——直接按 ## 标题做文档结构分片 + CCH 上下文增强,即可获得远超固定分块和纯递归分片的检索质量,且几乎零额外成本。
