 夜雨聆风
夜雨聆风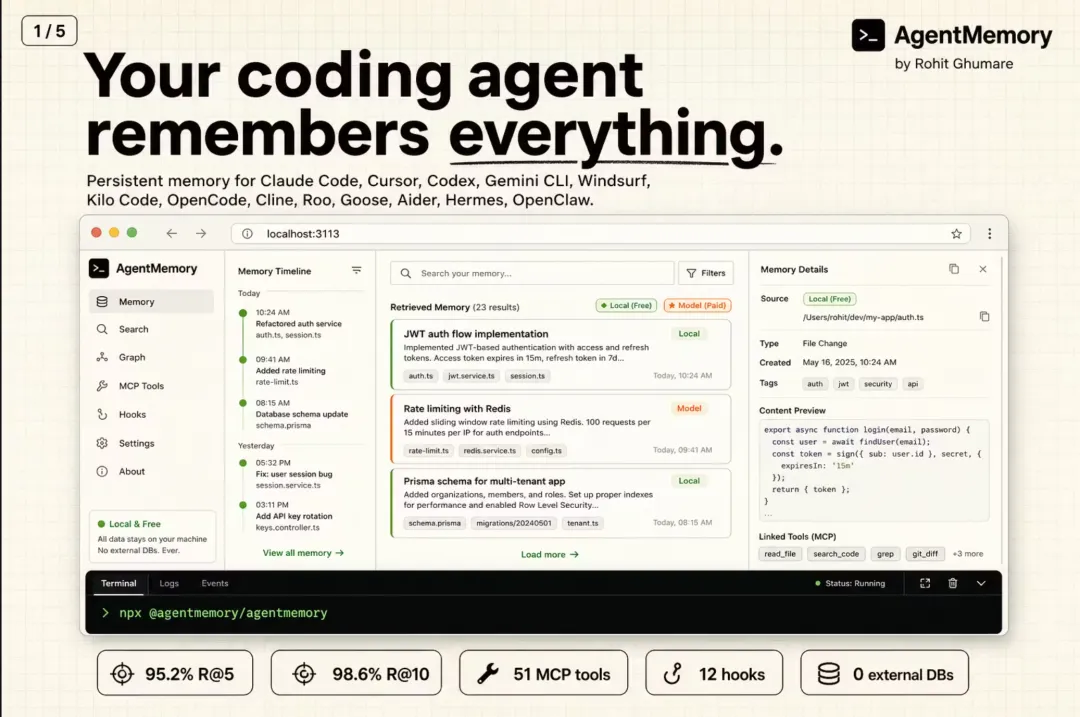
Claude Code 已经有自带的 Auto Memory,但规模一大就露出短板。这个开源工具补上了检索能力和跨工具共享,是自带记忆的进阶替代方案。
核心数据: LongMemEval 召回率 95.2% | 51 个 MCP 工具接口 | 支持 16+ AI 助手
背景:Claude Code 已经有记忆了,还需要这个吗?
先说一个容易被忽略的事实:Claude Code 其实已经有自带的持久记忆功能。
Auto Memory 让 Claude 在会话中自动把发现的有用信息写入 MEMORY.md,不需要开发者手动维护。Auto Dream 则在会话后后台自动整理:合并重复条目、删除矛盾事实、把"昨天决定用 Redis"转换成带绝对日期的记录。
所以问题变成了:自带的够用吗?
对于轻度用户,够了。但随着项目积累,三个结构性问题会浮现:
1. Token 膨胀:MEMORY.md 在累积 240 条观测后,会把 22,000+ tokens 塞进每次会话的上下文;agentmemory 同等数据只用 1,900 tokens,节省 92%。到 1,000 条观测时,内置记忆有 80% 会因为超出窗口而变得不可见。
2. 没有检索:auto memory 没有搜索能力,Claude 是线性读取 MEMORY.md 后自己决定要不要打开话题文件——本质上还是在 grep 一个 Markdown 文件。
3. 记忆不跨工具:如果你同时用 Claude Code 做重构、Cursor 做补全、Codex CLI 跑脚本,三者之间没有共享记忆,每个助手每次都要从头建上下文。
AgentMemory 针对的正是这三个问题,而不是"有没有记忆"本身。
AgentMemory 是什么?
AgentMemory 是一个专为 AI 编程助手设计的持久记忆系统,在 GitHub 上以「基于真实世界 Benchmark 的 AI 编程助手 #1 持久记忆」为口号发布。
它把 Karpathy 提出的 LLM Wiki 模式延伸升级,加入了置信度评分、生命周期管理、知识图谱和混合检索——AgentMemory 是这套架构的完整工程实现。
现有的 AI 编程助手自带的记忆(Claude Code 的 MEMORY.md、Cursor 的 notepads)就像便利贴,好用但有限。AgentMemory 是便利贴背后那个可搜索的数据库。
记忆是如何工作的?
AgentMemory 受人类大脑记忆巩固机制启发,将信息处理分为三个阶段:
① 实时观测(工具调用后触发)
SHA-256 去重 → 隐私过滤(剔除 API 密钥等敏感信息)→ 存储原始观测 → LLM 压缩提取结构化事实、概念和叙述
② 会话结束时的"睡眠巩固"
会话摘要 → 知识图谱抽取 → 向量嵌入(支持 6 家提供商 + 本地模型)→ 同步写入 BM25 索引和向量索引
③ 新会话时的上下文注入
加载项目档案(核心概念、常用文件、代码模式)→ 三路混合检索 → Token 预算控制(默认 2000 tokens)→ 注入对话
三路混合检索(Hybrid Search)
融合三种检索方式,并用 RRF 算法重排结果:
- BM25 关键词检索
— 词干提取 + 同义词扩展,支持中文、希腊文、西里尔文等多语言 - 向量语义检索
— 基于嵌入向量的语义相似度,捕获意图而非字面匹配 - 知识图谱遍历
— 挖掘实体间关系,补充单纯关键词/向量检索遗漏的关联信息 - 置信度衰减评分
— 综合新鲜度、访问频率、置信度对结果重打分
Benchmark 表现
| 95.2% | |
支持哪些 AI 编程助手?
AgentMemory 同时支持 Hooks、MCP 协议和 REST API 三种接入方式,几乎覆盖了市场上所有主流 AI 编程工具:
Claude Code Cursor Gemini CLI Codex CLI ClineWindsurf Aider Goose Kilo Code OpenCodeRoo Code Hermes 任意 MCP 客户端
所有助手共用同一个记忆服务器,记忆跨工具互通——你在 Cursor 里讲的架构决策,Claude Code 也能记住。
三行命令,立即开始
AgentMemory 做到了真正的零配置启动,不需要外部数据库,数据默认存储在本地:
# 1. 全局安装(推荐)npminstall-g@agentmemory/agentmemory# 2. 启动记忆服务器(端口 3111)agentmemory# 3. 连接你的 AI 助手(以 Claude Code 为例)agentmemory connect claude-code# 打开浏览器,实时观察记忆构建过程# → http://localhost:3113
安装完成后,访问 http://localhost:3113 可以看到一个实时可视化面板,包含:实时观测流、会话浏览器、记忆浏览器、知识图谱可视化和健康状态仪表盘。
几个值得关注的设计亮点
🔒 本地优先,数据不出境
所有记忆数据默认存储在用户本地机器,无需外部数据库。隐私过滤在写入前自动剔除 API 密钥、密码等敏感信息,并支持配置 AGENTMEMORY_SECRET 保护访问。
💰 Token 节省计算器
内置 Token 消耗统计,agentmemory status 命令实时显示累计节省的 Token 数量和等价美元成本(按 $0.30/1K tokens 计算)。持久记忆本质上减少了每次重复解释带来的 Token 消耗。
🔭 OpenTelemetry 全链路追踪
每一次记忆操作都作为 OpenTelemetry trace 记录,在控制台中可以看到 BM25 扫描 → 向量检索 → RRF 融合 → 重排序的完整瀑布图,支持导出到 Jaeger、Honeycomb、Grafana Tempo。
总结
Claude Code 的 Auto Memory 已经解决了「有没有记忆」的问题,AgentMemory 解决的是下一层:记忆多了怎么办、怎么检索、多个工具怎么共享。
如果你只用 Claude Code、项目不大、会话数不多——自带的 Auto Memory 完全够用,不需要额外折腾。
如果你同时使用多个 AI 工具、项目积累了大量上下文、或者对 Token 消耗比较敏感,AgentMemory 值得认真评估。
项目地址: github.com/rohitg00/agentmemory安装命令: npm install -g @agentmemory/agentmemory
感兴趣的话,赶紧安装上试试吧~
