 夜雨聆风
夜雨聆风最近我用 AI 做了一个很小的 Chrome 插件。
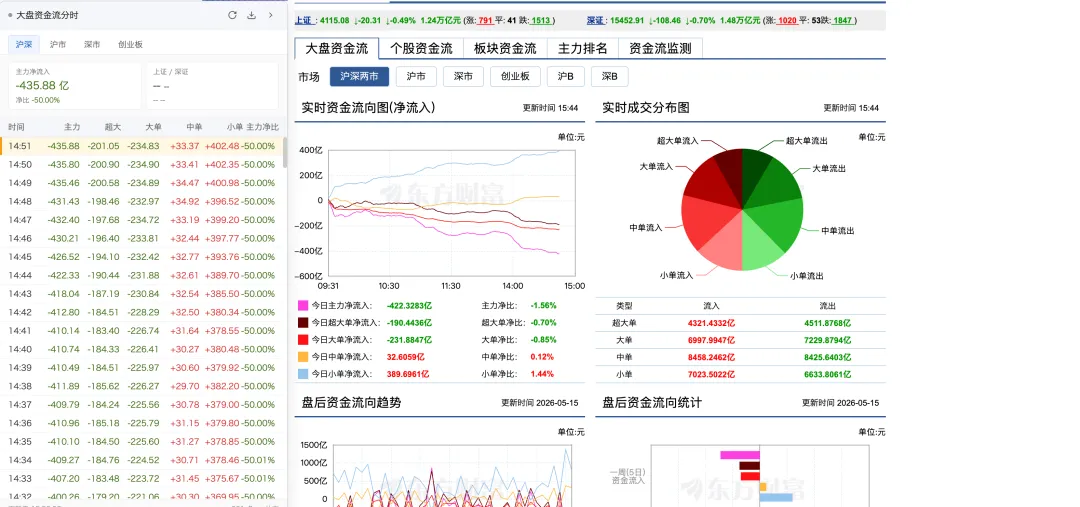
功能不复杂:打开东方财富的「大盘资金流向」页面后,插件会在页面上加一个浮窗,把原本需要鼠标悬停才能看到的分时数据,直接整理成一张表格。
从产品结果看,它只是一个提高信息获取效率的小工具。但真正有意思的,不是插件本身,而是我和 AI 一起把它做出来的过程。
这个过程里, AI 帮我选了技术路线,也犯了错;它写出了能跑的代码,也差点用一个听起来很合理的解释把我带偏;它有时候很听话,有时候又会主动拦住我说:「这个优化现在不值得做。」
我后来意识到, vibe coding 并不是「我什么都不懂,也能让 AI 替我做产品」。
更准确地说,它是一种新的协作方式:
AI 负责快速执行,你负责做判断。
1. 先做决策和原型,再写代码
我一开始没有直接让 AI 写代码。
它先反问了我 3 个问题:
这 3 个问题看起来普通,但每一个都会让最终代码走向不同方向。比如「调接口」和「解析页面」就是两条路线,做到一半才发现选错,基本就不是「小改」了。
所以我现在更习惯先问 AI :
在写代码之前,先列出这个需求有哪些关键技术路线和产品选择,每个选择会影响什么。
你不一定要懂所有实现细节,但你必须知道自己正在做什么选择。
AI 给我的第一个交付物也不是代码,而是一张模拟效果图。浮窗放在哪里,表格有几列,刷新按钮放哪儿,最新一行怎么高亮,异常状态要不要显示「暂无数据」。
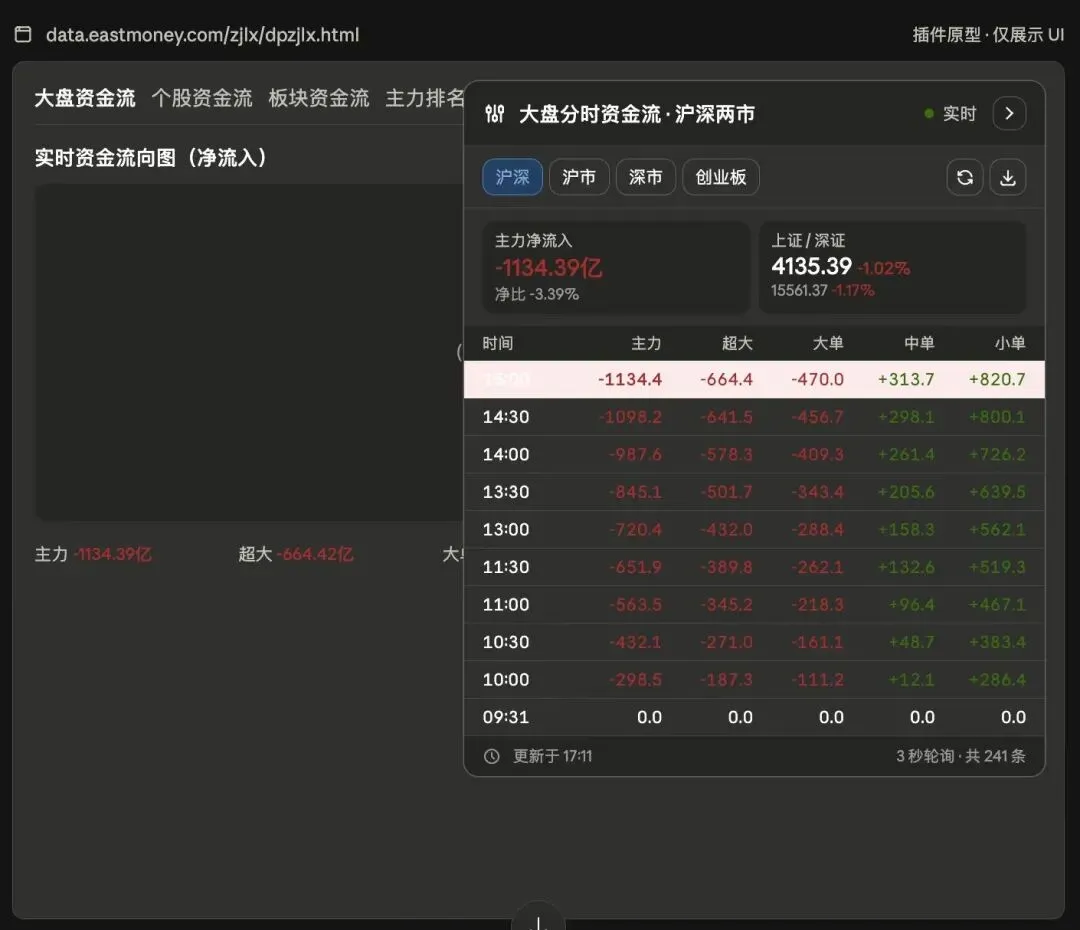
这一步看似在画图,其实是在帮你做决策。
很多需求不是一开始就能说清楚的。你往往是看到一个「不太对」的版本,才知道自己真正想要什么。比如浮窗太大,会挡住原页面右侧行情区域;表格字段超过 6 列,就会削弱「快速查看」的初衷。
这些判断如果发生在代码写完之后,就是返工。但如果发生在 mockup 阶段,只是改图、改文案、改布局。
原型不是为了好看,而是为了让「不对劲」尽早暴露。
2. 为什么我选 Chrome 插件,而不是爬虫脚本
这个项目一开始,我想过用 Python 写个爬虫脚本,定时去抓数据。
但 AI 建议我做成 Chrome 插件。
理由很实际:如果你的目标是给某个网站做数据增强工具,插件往往比爬虫更省事。
像东方财富这类数据网站,浏览器能看到的数据,背后通常都有接口。但「接口能在浏览器里看到」不等于「脚本能稳定调用」。
网站常见的限制包括 Referer 、 Origin 、 Cookie 、 JS 动态签名、访问频率等。你用 Python 直接请求接口,就可能要手动补请求头、处理 Cookie 、复现签名逻辑,还要担心对方小改一下前端,脚本就失效。
Chrome 插件的位置不一样。
插件代码是注入到目标网站页面里运行的。你已经打开了页面,浏览器已经完成 Cookie 、脚本加载和基础请求,插件只是借用了这个上下文。
换句话说,插件不是站在网站外面硬模拟用户,而是运行在真实用户已经打开的网页里。 Referer 、 Cookie 、页面 JS 环境,这些上下文都更自然。
如果你做的是某个网站的数据辅助工具,优先考虑浏览器插件,不要一上来就写外部爬虫。
不是因为插件更高级,而是因为它的执行环境更接近问题本身。
3. 跑不起来时,先拿证据
代码生成完之后,我装上插件。
页面一片空白。浮窗出来了,但表格里没有任何行。
这才是 vibe coding 的常态。
第一版能直接跑通当然好,但更常见的情况是:代码看起来完整,逻辑也说得过去,真正放进浏览器环境后,问题一个接一个出来。
我把现象发给 AI 。
这次它没有直接猜,而是列了 4 种可能原因,然后让我打开开发者工具,在 Console 里用一段小代码确认接口到底有没有返回数据。
这个动作很关键。
调试最怕的不是出错,而是大家开始凭感觉解释错误。 AI 可能会说「应该是跨域问题」,你可能会觉得「是不是插件权限没配」。这些猜测都可能成立,但在没有证据之前,都只是噪音。
Network 面板里有没有请求,状态码是不是 200 ,响应 JSON 里数组长度是不是 0 ,这些才是讨论的起点。
我按它的方式验证后,发现接口确实返回了 0 条数据。
到这里,问题至少从「页面空白」缩小到了「数据源为空」。
这就是一个很好的调试节奏:先把模糊现象拆成可验证的小问题,再用证据逐个排除。
4. AI 会自信地说错,要相信现实
看到接口返回 0 条数据后, AI 给了一个听起来非常合理的解释:
因为今天是周末,股市不开盘,所以接口在非交易日返回空。这是接口设计限制。
这个解释很完整,语气也很确定,还顺手给了 3 个解决方案。
但我心里有一个反例:东方财富自己的页面,周末打开是能看到数据的。
如果接口在非交易日真的只能返回空,那网站自己也不应该展示出数据。
所以我没有马上接受 AI 的解释,而是打开浏览器 Network 面板,刷新页面,抓了目标页面真实发出的接口 URL ,连同 Query String Parameters 一起发给 AI 。
结果很快就清楚了。
AI 代码里用的是 push2his 这一类历史数据域名,而页面真实请求用的是 push2 这一类实时数据域名。两个地址只差几个字母,但行为完全不同。
也就是说,问题不是「周末没数据」,而是「接口选错了」。
AI 讲对的时候很自信,讲错的时候也很自信。
它的语气不能作为可信度判断。
当 AI 的解释和你看到的现实冲突时,永远相信现实。最快的反驳方式不是争论,而是给它证据:真实请求、响应 JSON 、 Console 报错、页面截图。
这不是 AI 不好用。恰恰相反,正确的用法是让它在证据上推理,而不是在猜测上发挥。
5. 好的 AI 不只执行,也会拦你
修完接口问题后,我又问 AI :
现在拉数据是全量还是增量?我想改成增量。
这次它没有马上动手。
它先告诉我:现在是全量拉取,单次响应大概 20KB 。按当前使用频率算,一小时也就几百 KB ,这根本不是性能瓶颈。
然后它解释,增量更新会带来额外复杂度:最新一分钟的数据可能还在变化;部分字段是累计值,不是单分钟增量;如果以后要做本地历史存储,增量才更有意义。
它给出的建议很明确:现在不要改。
这段反馈比一段新代码更有价值。
很多工具不是死在「功能太少」,而是死在「过早复杂化」。所以和 AI 协作时,不要只问:
帮我实现这个功能。
可以多问一句:
这个功能现在值得做吗?如果不做,会有什么实际损失?
很多时候,答案会帮你省掉一半代码。
6. 结束总结: AI 负责执行,你负责判断
Vibe Coding不是「不会写代码的人也能无脑做软件」。
更准确地说:你可以不亲手写每一行代码,但你不能放弃判断。
AI 可以把执行速度拉得很快,但产品方向、取舍、验证和纠错,仍然需要人来负责。
工具变了,做产品的核心没有变。
你还是要清楚自己要什么,也要能在过程中识别:这不是我要的。
