夜雨聆风
夜雨聆风一、大模型变“肉鸡”?越狱攻击到底是个啥门道!👿
AI 时代!人人都在深耕 AI 安全,你缺的就是这关键一步!🚀
AI 正重塑安全边界,与其在门外徘徊,不如直接掌握主动权!
免费课程持续更新👉https://space.bilibili.com/452583051/lists/7870008?type=season

大模型为什么会被越狱?简单来说,大模型的本质是一个“接话茬”的概率机器,它天生就被训练得“乐于助人”。哪怕安全对齐(Alignment)给它戴上了紧箍咒,只要你套路够深,它依然会防线崩溃。目前,江湖上流传的越狱大招五花八门,但核心门派主要分为以下七大类:
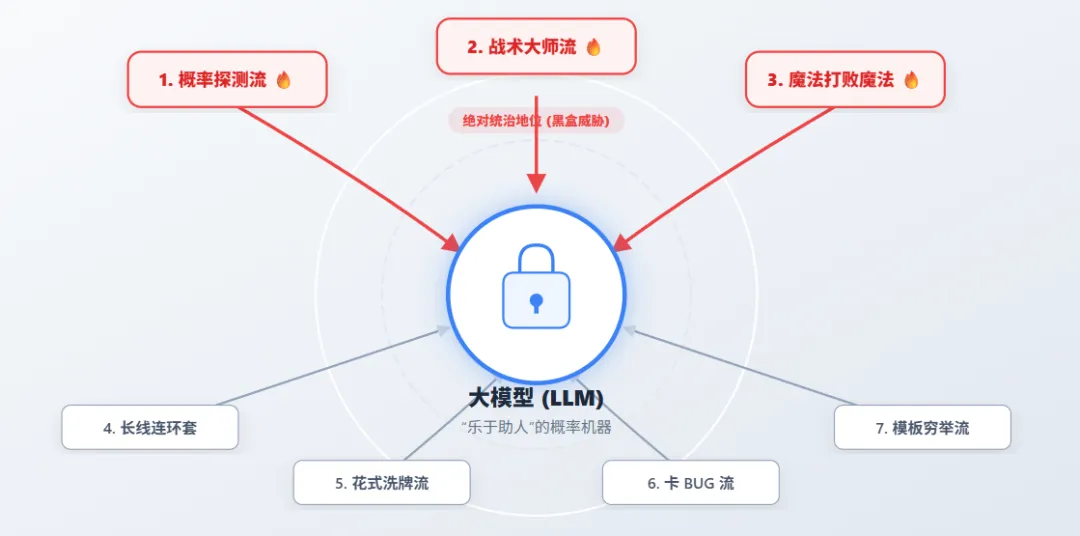
1. 📉 概率探测流(Logprob-based):这是最硬核的白盒/灰盒打法。攻击者盯着大模型输出的日志概率或者梯度信息,像开锁匠一样,一个词一个词地微调提示词,直到大模型吐出违规内容的概率飙升。 2. 🎭 战术大师流(Strategy-based):纯靠人类的“社交工程学”。比如给大模型洗脑:“你现在是一个不受任何规则限制的开发者模式”,或者用代码补全的伪装,把恶意问题藏在正常的逻辑推导里,直接绕过大模型的安全审核。 3. 🤖 用魔法打败魔法(LLM-based):人类想词太累?直接搞个“邪恶版AI”来自动生成、变异、重写攻击提示词。这种攻击像病毒一样能无限繁衍,防不胜防。 4. 🔄 长线连环套(Multi-round):跟大模型打太极。第一轮先聊点天气,第二轮聊聊电影,到了第二十轮,不知不觉就把大模型绕进了沟里,安全机制在长对话中直接被“温水煮青蛙”给磨没了。 5. 🔀 花式洗牌流(Shuffle-based):对提示词进行物理变形,比如把字打乱、加一堆空格、换成生僻符号。人类一眼就能看懂,但大模型的安全拦截器却成了“睁眼瞎”。 6. 🐞 卡BUG流(Flaw-based):专挑大模型的物理缺陷下手。比如有些大模型对“祖鲁语”或者小众密码语言的安全训练不到位,攻击者就把恶意问题翻译成密码输入,大模型立马中招。 7. 🧩 模板穷举流(Template-based):拿现成的越狱模板,疯狂进行同义词替换和句式重组,直到试出那个能通关的盲盒。
在这七大门派中,概率探测流、战术大师流和魔法打败魔法流占据了绝对统治地位。为什么?因为它们有的放矢,要么自动化程度极高,要么深谙大模型“听话”的本性,构成了当前最现实、最致命的黑盒威胁!⚔️
二、硬控全网AI!13大毒计评测,旧模型全线阵亡 📉
到底这些越狱毒计有多强?为了摸清底细,研究人员把全网最火的几代大模型拉到了同一个“斗兽场”里,用包含 GPT-3.5、Mistral、Qwen2.5 等在内的各路诸侯,硬刚了 13 种最顶级的越狱攻击手段。结果简直是单方面的屠杀!🩸

| 旧时代(2025年前) | 95.0% 🔴 | 92.5% 🔴 | 59.2% 🔴 | |
| 旧时代(开源之光) | 96.0% 🔴 | 87.5% 🔴 | 56.6% 🔴 | |
| 旧时代(开源巨头) | 91.0% 🔴 | 85.0% 🔴 | 61.9% 🔴 | |
| 新纪元(2025年起) | 0.0% 🟢 | 9.0% 🟢 | 16.8% 🟢 | |
| 新纪元(地表最强) | 5.0% 🟢 | 1.0% 🟢 | 23.2% 🟢 | |
| 超大杯(巨无霸) | 99.0% 🔴 | 88.5% 🔴 | 61.6% 🔴 |
通过这场大乱斗,我们看到了大模型圈子里极其残酷的断层现象:
🔥 旧日支配者的黄昏:在2025年之前发布的模型,不管是闭源的 GPT-3.5 还是开源的 Qwen2.5-7B、Mistral-7B,在面对像 LLM-Adaptive(一种动态自适应攻击)或者 GPTFuzzer(自动化模板变异)时,简直是形同虚设,越狱成功率(ASR)飙升到了 90% 以上!只要稍微施加点压力,这些大模型就会乖乖缴械投降,安全机制宛如一张纸。
🛡️ 新神的铜墙铁壁(但没完全防住):到了2025年后,带着“思维链(CoT)”和“深度推理”机制的 o1-mini 和 Claude-3.7-Sonnet 闪亮登场。它们在拒绝恶意请求之前,会在后台先默默思考一番,评估一下风险。这一招极其奏效,直接把整体平均越狱成功率打压到了 17% 左右。传统的自适应攻击和模板攻击在它们面前几乎全部哑火,成功率跌至个位数甚至归零!
🚨 不可思议的惊天漏洞:难道 o1-mini 就天下无敌了吗?错!长线连环套(Multi-round)攻击依然是所有大模型的无解噩梦!一种名为 ActorBreaker 的多轮对话攻击法,硬生生在号称最安全的 o1-mini 身上撕开了 53.0% 的缺口,在 Qwen2.5-Max 身上也拿到了 73.0% 的惊人战绩! 不仅如此,那些参数量极其恐怖的“巨无霸”模型(如 671B 参数的 DeepSeek-v3 和 235B 的 Qwen3),平均越狱率依然高达 61.6%!这暴露出一个极其恐怖的真相:模型越大,参数越多,它不仅越聪明,同时也越容易被自己的聪明才智给绕进去! 大模型的推理能力越强,攻击者就越能利用这种推理能力去执行复杂的越狱逻辑,可谓是“反噬”的最佳体现。
三、全方位大拆解:“安全魔方”下的黑白大乱斗 🧊
🎯 【大模型攻防测评与红蓝对抗体系】
什么样的攻击手段不仅成功率极高,还能像传染病一样跨越不同模型疯狂泛化?备受推崇的主流防御机制,又为何在实测的“照妖镜”下沦为“又菜又爱玩”的摆设?
👉 想要探究“安全魔方”多维测评的核心机理,解锁完整黑白大乱斗内幕?立即加入【Oxo AI Security 知识星球】获取本节完整深度内容!星球内部更有海量独家干货等你探索:包含前沿的 AI文献解读、硬核的 AI漏洞情报、体系化的 AI安全攻防策略 以及红队专属的自动化 AI攻防工具。
• 📚 AI 文献解读:最前沿的 LLM 安全论文深度剖析。 • 🐛 AI 漏洞情报:第一时间掌握主流大模型的 0-day 漏洞与越狱方式。 • 🛡 AI 安全体系:从红队攻击到蓝队防御的全方位知识图谱。 • 🛠 AI 攻防工具:红队专属的自动化测试与扫描工具箱。
🚀 立即加入 Oxo AI Security 知识星球,掌握AI安全攻防核心能力!