 夜雨聆风
夜雨聆风最近完成了一件以前觉得"迟早要做但一直拖着"的事:把一个检索结果里的几百篇文献,使用AI,完成了大部分文献的批量下载。
以前的做法,相信很多人都经历过——打开 PubMed,找到文章,点进去,找 PDF 链接,下载,再回来,找下一篇……循环几十次之后,整个人像机器一样整天无脑点鼠标。
这次我换了一种方式,让 AI帮助想办法来做这件事。过程挺有意思,感觉又一次探索了AI能做什么,拓展了我对它功能边界的认识。
流程是这样的
第一步:从 PubMed 导出检索结果
PubMed 支持把检索结果批量导出成文件,包含每篇文章的标题、作者、DOI、PMID 等基本信息。成为一个txt文件。以往这个txt很难编辑,直接用表格读,也不能信息对应归类。只能导出到.bib 等格式,给到文献管理软件,例如给到endnote,然后再从endnote里导出表格式的题录。
但是现在有AI帮助,可以自动识别这个txt中的字段名,迅速生成整齐表格。
第二步:让 AI尝试分析问题写对应的脚本
我把需求描述给 AI:给定一批 DOI,尝试获取每篇文章的全文 PDF,并按规则命名保存到本地文件夹。
AI生成的脚本会依次尝试不同的获取路径:
优先走公开渠道:部分期刊本身开放获取,或者有合规的公开全文数据库,这部分脚本可以直接在任何网络环境下跑;(Skill 见文末分享)
再走所属机构(学校)的VPN渠道:有些文献需要通过所属机构(学校)账号或 VPN 才能访问,脚本会在连接机构网络的环境下尝试这部分。这部分也涉及到权限,就不继续展开了。
第三步:检查结果,人工补充
脚本跑完之后,会生成一份日志,会列出下载成功、失败的文献以及失败的原因。
之后再手动过一遍,进行必要的人工下载。
这套流程适合什么场景?
用下来,我觉得以下几类情况特别值得试试:
场景一:系统综述或 Meta 分析的文献准备阶段
这类工作往往要从几百甚至上千篇检索结果里筛文献,在筛选之前需要先把摘要、全文都拿到手。手动下载会让这个阶段变得格外漫长,批量脚本可以把这部分时间压缩到极低。
场景二:开题阶段的大范围文献调研
开题时需要快速建立对某个领域的整体认知,往往要读很多文章、拉很长的参考书单。这时候有一个本地的全文文件夹,比反复在线查找要方便得多。
场景三:团队定期更新文献库
如果你的课题组有固定的关注领域,可以定期跑一次检索+下载,把新出的相关文献自动收进来,省去人工盯着数据库的麻烦。
开放数据库的全文下载Skill 分享
它会做这几件事:
解析题录里的 DOI、PMID、PMCID
查询公开开放全文链接
保存为
`序号_标题.pdf`生成
`download_manifest.csv`对每条失败记录写清楚原因
这个 skill 的功能很明确:只下载开放全文,不使用插件、不绕过付费墙。
下载skill,给到AI装载,下次同样的场景就可以调用了
https://github.com/zhli6342-creator/public-literature-download
一边做这个Skill, 又有一个新想法冒出来,既然这是一个可以脱离AI完成的自动化程序,那是否可以独立生成一个类似软件的工具呢?又和AI聊了一会儿,生成了一个工具包,可以独立下载、解压缩、工作。
于是有了这个可以独立使用的工具包:
我用夸克网盘链接:https://pan.quark.cn/s/b9bc39964025
使用方法:解压后(压缩包密码 gongzhonghao-fanhuashi )双击 start.bat,然后打开 http://localhost:4319。界面支持上传 TXT/CSV(表头格式为`序号`, `文献名`, `DOI`, `PMID`, `PMCID`),设置并发数和试跑数量,下载完成后会生成 download_manifest.csv,PDF 和报告会保存在 downloads/<job-id>/ 下。
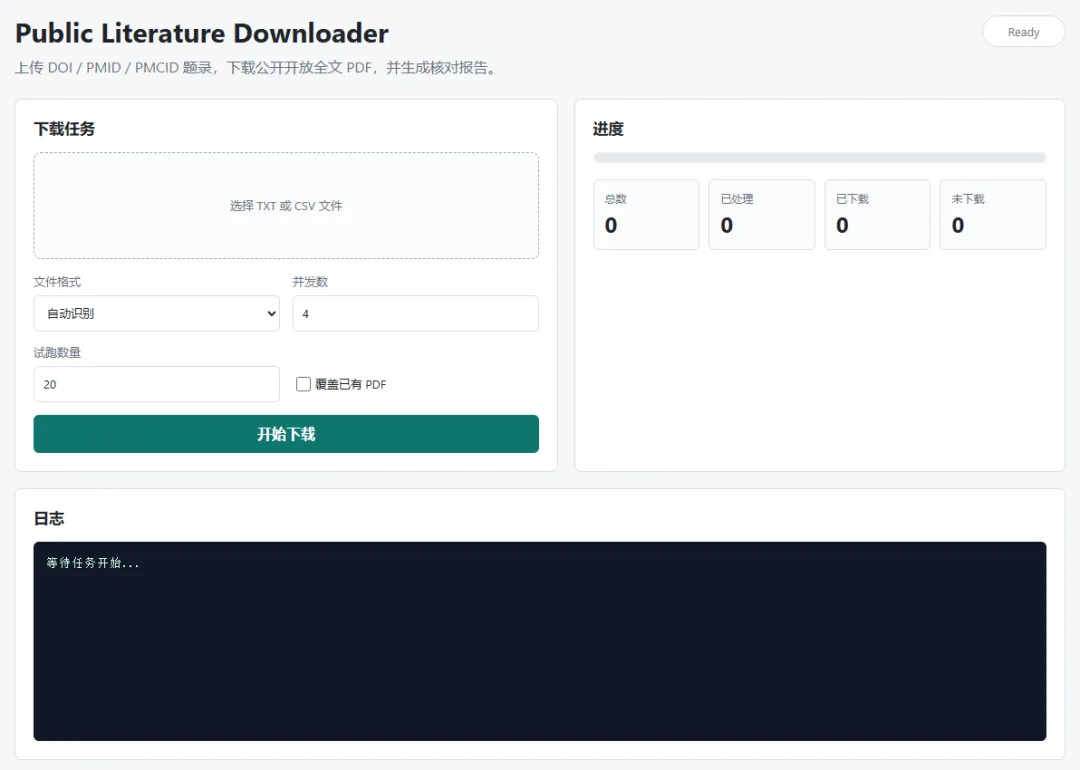
最后
这次尝试让我意识到,很多"烦但必须做"的环节,其实是可以借助 AI 工具降低阻力的。它可以帮你把精力留给真正需要思考的部分。
并且 每一次使用AI完成的工作,都可以开发为一个skill,或者独立工具,这也是非常有趣的事。
