 夜雨聆风
夜雨聆风今天向大家推荐一个来自文因互联(Memect) 的开源项目——memect-ppx,一款高精度的文档解析引擎,能够将PDF和图片高效转换为结构化的Markdown和JSON格式。
memect-ppx 是什么?
memect-ppx(简称PPX)是一个PDF和图片文档解析工具,它通过内置的OCR和版面分析流程,能够高保真地提取PDF和图片中的文本、表格、图表、公式等内容。它支持两种工作模式:
本地模型模式(默认) :在CPU上即可运行,无需GPU,适合对数据隐私有要求的场景;
LLM后端模式:可选择DeepSeek-OCR、PaddleOCR-VL、GLM-OCR等先进模型,进一步提升解析精度。
输出结果支持Markdown、JSON和HTML格式,每个对象都带有页面坐标信息,方便后续处理和分析。

🎯 为什么需要这样的工具?
文因互联(Memect)是一家专注于AI驱动知识管理技术的公司,由“语义网之父”Tim Berners-Lee的学生鲍捷博士创办。公司长期服务于金融行业,为投资银行、监管机构等提供业务流程自动化和智能化解决方案。
正是因为在金融领域的深耕,文因互联深刻体会到:大量的信息固化在非结构化文档中,提炼成本高昂。在这样的背景下,memect-ppx应运而生——它不仅是一个开源项目,更是文因互联多年文档处理技术积累的结晶。
💡 核心功能亮点
1️⃣ 高精度解析能力
文本提取:精准识别各类文本内容
表格识别:支持复杂表格的
colspan/rowspan结构解析公式提取:自动将公式转换为LaTeX格式
图表区域提取:识别并提取图中的元素
2️⃣ 多后端灵活切换
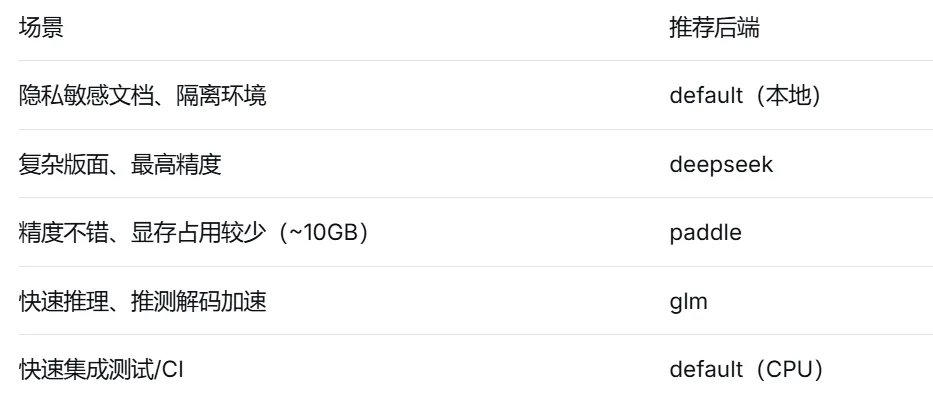
3️⃣ 无需GPU即可运行
默认后端完全支持CPU运行,扫描版PDF会自动应用OCR识别。当然,如果你有GPU(CUDA加速),处理速度会更快——特别是在复杂表格和公式识别方面,速度可提升3~5倍,复杂公式可达十几倍。
4️⃣ 输出格式丰富
output/├── doc.md # 完整文档(Markdown格式)├── doc.html # HTML预览/导出(可选)├── doc.json # 结构化数据(带坐标信息)├── pages/ # 按页面拆分的内容└── images/ # 提取的图片区域
5️⃣ 支持批量处理
批量处理数千份文件只需一个命令,非常适合大规模文档解析场景。
🚀 快速上手
安装
# 使用 uv 创建虚拟环境并安装uv venv -p 3.12source .venv/bin/activate # Linux/Macuv pip install memect-ppx# 安装依赖模型ppx installppx download
基础使用
# 解析单个PDF文件ppx parse report.pdf# 强制对所有页面进行OCRppx parse report.pdf --ocr yes# 使用LLM后端(如DeepSeek-OCR)ppx parse report.pdf --backend deepseek# 批量解析整个目录ppx parse docs/ -o output/
高级配置
可以通过配置文件持久化常用设置,避免每次都重复输入命令行参数。
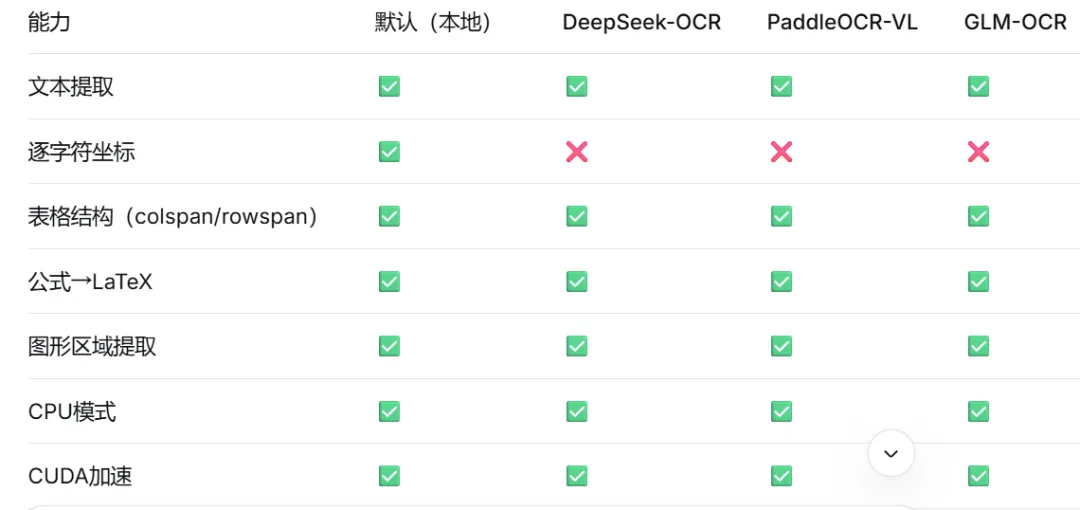
📊 后端能力对比
🌟 适用场景
📄 财务报表解析:精准提取报表中的表格数据
📚 学术论文处理:识别并转换LaTeX公式
🏢 合同文档分析:批量处理合同文本
📸 扫描文档识别:OCR处理老旧的扫描件
📊 批量数据提取:从大量PDF/图片中提取结构化信息
如果你有在线体验需求,也可以访问 pdf2x.cn 进行试用
项目地址
GitHub:https://github.com/memect/memect-ppx
memect-ppx是一款定位精准、功能强大的文档解析工具。它既能满足日常文档提取的基本需求,也能通过LLM后端满足高精度场景的严苛要求。如果你正在为PDF和图片文档的数据提取而烦恼,不妨试试这个来自文因互联的开源项目。
END

如本文对您有帮助,请点赞和爱心,谢谢!

点这里👇关注我,让我们一起成长!
