 夜雨聆风
夜雨聆风几十上百篇 PDF 摆在面前,样本量、干预措施、随访时间、各亚组人数一个个手抠;
双人独立提取再交叉核对,一篇文献来回看 3 遍;
表格、Figure、Supplementary 三处分散,字段散落各处;
Excel 录入容易看错行、漏字段,后续 Review Manager / Stata 导入时一片乱码。
一篇高质量的系统综述,光数据提取就要 2–4 周,而你的核心工作其实应该花在 PICOS 设计、偏倚评估和异质性解释上。
医豌豆「AI 自动提取数据」功能,就是为了把研究者从这个泥潭里拉出来:上传 PDF → 描述提取需求 → 一键产出结构化数据表。下面为您手把手介绍。
一、功能定位--"数据收割机"
医豌豆把 Meta 分析全流程拆成了 5 步,「AI 自动提取数据」位于第三步——也就是文献筛选完成、确定纳入文献之后、开始正式统计分析之前的关键节点。
实现原理:
PDF → OCR/解析为可读文本 文本清洗 → 分块分类 → RAG 精准匹配 表格用结构化解析,图片走视觉模型
简单说:你告诉它要什么,它就从一堆 PDF 里找出来填表,而不是把 PDF 翻译给你自己找。
三、界面拆解
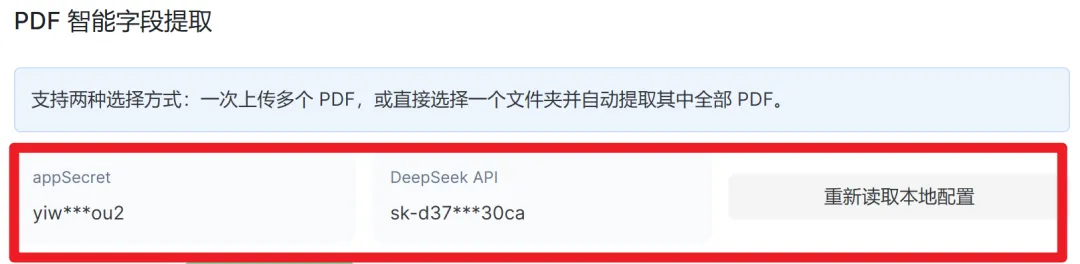
1. API 配置区(顶部)
- appSecret:医豌豆账号密钥,首次使用时配置一次即可,后续自动读取本地配置。
- DeepSeek API:大模型接口,负责语义理解与字段抽取。
- 重新读取本地配置:如果切换了账号或更新了 key,点这里刷新。
提示:第一次使用记得到设置里绑定好 API key,否则会卡在初始化。
2. PDF 上传区
支持两种灵活方式,适配不同工作习惯:
- 「选择多个 PDF」:适合精挑细选,只提取部分文献;
- 「选择整个文件夹」:适合已经整理好"纳入文献"文件夹的场景,一键全选,几十上百篇 PDF 同时处理;
- 「清空文件」:重新开始时一键清空已选列表。
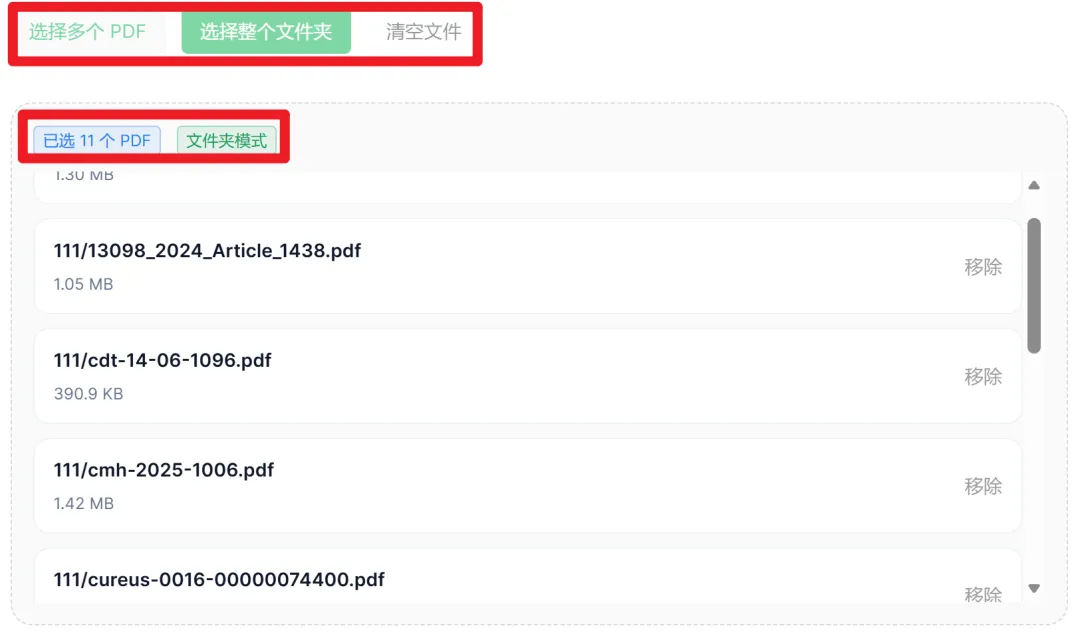
上传后,中间区域会显示「已选 X 个 PDF」,可直观核对数量,避免漏传。
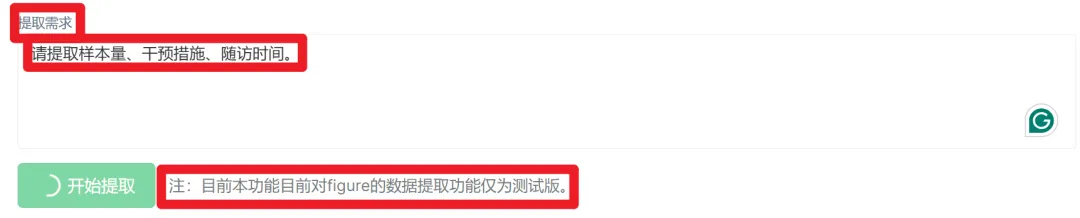
3. 提取需求输入框(灵魂)
这是整个功能的核心交互点。和传统模板式工具不同,医豌豆采用自然语言驱动——
你只需要用一句话描述要提取什么,例如:
例 1:
请提取样本量、干预措施、随访时间
例 2:
提取每组人数、平均年龄、性别比例、主要结局事件数、HR 及 95%CI
例 3:
提取作者、年份、国家、研究设计、纳入排除标准、HbA1c 变化值(均值±标准差)
AI 会按你描述的字段去每篇 PDF 里搜索、识别、抽取、整理。写得越具体,结果越精准。
4. 开始提取按钮 + 处理进度区(实时反馈)
点击「开始提取」启动任务。注意官方提示:
注:目前本功能目前对 figure 的数据提取功能仅为测试版。
也就是说:表格 + 正文里的数字提取已经相当成熟,Figure 里的数据点提取还在迭代中。如果你的关键数据藏在森林图、Kaplan-Meier 曲线里,建议人工二次核对。

提交后下方会实时显示:
- 当前步骤:如"正在解析第 12/45 篇 PDF""字段抽取中""结果汇总中";
- 后端反馈:任务状态、报错信息(如果有);
- 任务 ID:每个提取任务的唯一编号,建议复制保存,如遇异常可凭此向客服反馈定位。
四、常见疑问
Q1: 中英文文献都支持吗?
A:支持。DeepSeek 大模型对中英双语理解能力强,字段名也可中英混写。
Q2: 数据安全吗?
A:文件解析在云端处理,任务 ID 可追溯,不会跨账号泄露。涉及未发表数据的研究建议先咨询合规要求。
Meta 分析的价值在于证据综合的洞察,而不是 PDF 里抠数字的体力劳动。
医豌豆 metaAI agent 不是要取代你的科研判断,而是让你把节省下来的时间花在更有价值的地方——研究问题打磨、异质性来源探讨、临床转化讨论。
第三步 → AI 自动提取数据,现在就可以试用。
操作路径:登录医豌豆 → 第三步 → AI 自动提取数据 → 上传 PDF → 描述需求 → 开始提取
