 夜雨聆风
夜雨聆风Google DeepMind + Research · LLM + Tree Search 自动写实证软件 · 6 个 scorable 基准全部达 expert-level
—— 40 个新单细胞方法击败 OpenProblems leaderboard · 14 个 COVID 模型击败 CDC Ensemble · 全 GIFT-Eval 时序 leaderboard 被超越 ——
◆ ◇ ◆
作者Eser Aygün*, Anastasiya Belyaeva*, ..., Shibl Mourad†, Michael P. Brenner† (通讯)|单位Google DeepMind / Google Research / Google Platforms / MIT / Harvard SEAS / McGill / Caltech|期刊Nature, 2026-05-19 online (Accelerated Article Preview)|DOI10.1038/s41586-026-10658-6|通讯shibl@google.com · mbrenner@google.com
一导读
科研的瓶颈不只在思考——更经常卡在"写一段能跑、能验证、能上 leaderboard 的代码"上。一个有经验的科研工程师写一个 scRNA-seq 批次效应去除算法可能要几周,跨平台部署 + 调参 + benchmark 又要更久。**绝大多数科学突破被这道"实证软件墙"挡在外面**。
2026 年 5 月,Google DeepMind / Research 团队在 Nature 报告了 **ERA (Empirical Research Assistance)**——一个把 LLM 与 Tree Search 结合起来"自动写专家级科研代码"的 AI 系统。给它一个可打分的任务,它会反复变异代码、用 tree search 探索解空间,在多个独立科学领域**完整超越当下最强人类 + 最强基准**:
✓ **单细胞 RNA-seq 批次校正** — 在 OpenProblems v2.0.0 benchmark 上,ERA 自动发现了 40 种新方法,**全部胜过当下最强人工方法 (ComBat) 14% 以上**;✓ **CDC COVID-19 入院预测** — 生成 14 个超过 CDC Ensemble 的模型,**WIS=26 vs 官方 Ensemble WIS=29**;✓ **GIFT-Eval 时间序列** — 超过 2025 年 5 月所有基础模型 + 深度学习 + 经典方法 leaderboard;✓ **斑马鱼 70,000 神经元活动预测 (ZAPBench)**、**地理影像分割**、**积分数值求解**——皆达到 expert-level。
换句话说:**LLM 已经能从零写出经过严格基准 leaderboard 验证的科研软件,且超越人类专家**。
二研究背景:为何"实证软件"是科研的隐形瓶颈
▍ 1. 大多数 Nobel-prize 工作背后都是一个软件
1998 化学奖 (Density Functional Theory)、2013 化学奖 (分子动力学模拟)、2024 化学奖 (蛋白质结构预测) 背后都是定制化、性能极优的科研软件。但这种软件极其难写,通常需要多年人月,且没有系统的"搜索更好替代方案"过程——多数设计选择靠"经验直觉"而非穷举。
▍ 2. 已有的 LLM 写代码方法的不足
直接让 GPT-4 写一段 scRNA-seq 批次校正代码,通常会输出一个能跑但平庸的解。Best-of-N 采样虽好,但缺乏"探索 + 回退"能力。AIDE 等 code mutation 系统是单线路径,无法系统性 backtrack。**真正的科研代码需要 tree search**——保留多个 promising 分支、择优继续、停滞时回退、组合 idea。
三方法:LLM + Tree Search + 研究想法注入
▍ 1. ERA 的核心范式
(1) 给系统一个"可打分任务"(scorable task) + 数据 + evaluation metric;(2) LLM 写初版代码,运行,得到分数;(3) Tree search 维护一个**多分支候选解树**,每个节点是一段代码 + 其得分;(4) 在每个时间步,系统选择最有 promise 的节点变异 (mutation) 新代码,如果改善就扩展该分支,如果停滞就回退到其他分支;(5) 注入**研究想法**——可来自高被引论文、教科书、搜索引擎结果,或人工指令;(6) 一直跑直到 budget 用完。
▍ 2. 6 个 scorable 基准全覆盖
论文一次性在 6 个差异极大的任务上跑 ERA,证明其 generalizability:• Single-cell RNA-seq 批次校正 (OpenProblems v2.0.0)• CDC COVID-19 入院预测 (CovidHub)• 时间序列预测 (GIFT-Eval, 7 领域 28 数据集)• 地理影像语义分割• 斑马鱼神经活动预测 (ZAPBench, 70,000+ 神经元)• 困难数值积分求解另在 16 个 Kaggle playground 比赛上做基准校验。
▍ 3. Kaggle benchmark — 击败 AIDE / best-of-1000 / 单 LLM
16 个 2023 赛季 Kaggle playground 比赛,ERA 平均 percentile rank 显著高于 single LLM call、best-of-1000 LLM calls、以及目前最强 code-mutation 基线 AIDE。
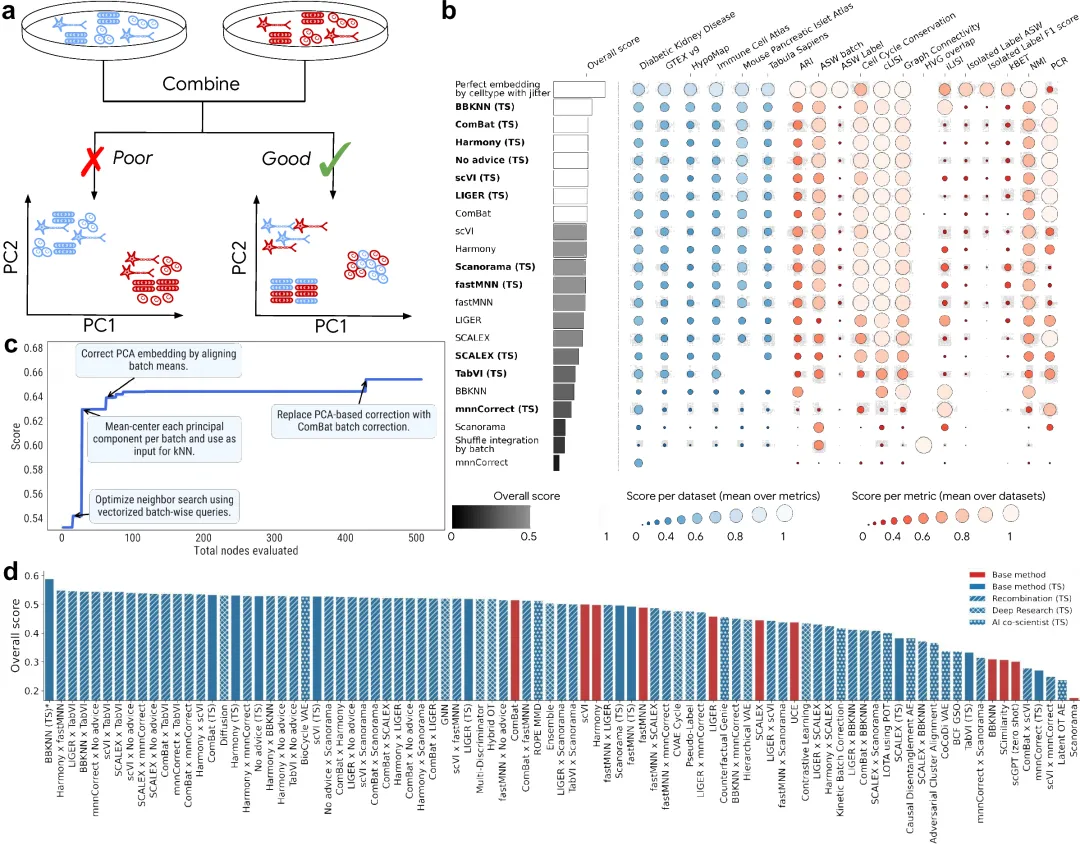
图 1 | ERA 系统架构:LLM 代码 mutation + Tree Search 多分支候选解树 + 高被引论文/教科书/AI Co-Scientist 想法注入 + 方法重组 (Recombination)。
四核心结果
▍ 1. 单细胞 RNA-seq 批次校正 — 击败最强人工 14%+
在 OpenProblems v2.0.0 上,ERA 一开始就给出比当前 leaderboard 第一名 (ComBat) 略好的方案;后续加入 9 篇代表性方法的 paper PDF 作为 prompt context,ERA 与 8/9 个对应方法做"重新实现"竞争——8 个都被 ERA 改进版超过。其中"BBKNN_TS"(基于 ComBat 校正后的 PCA 做近邻图)**比官方 BBKNN 实现在 11/13 个指标上更强,在 6 个数据集都做最优,整体得分比 ComBat 高 14%**。
论文进一步系统性地**程序化组合 (recombination)** 11 种方法,55 对配对中 24 对 ERA 实现超越双亲;再用 Gemini Deep Research + AI Co-Scientist 给 ERA 提供 21 个新想法——**40 / 87 当前 leaderboard 公开方法被这套 ERA 流程完全超越**。
▍ 2. CDC COVID-19 入院预测 — 14 个模型超过官方 Ensemble
在 2024-2025 赛季滚动验证窗口下,ERA 平均 WIS = **26 (越低越好)**,vs CDC 官方 CovidHub Ensemble 的 **WIS = 29**,在过半数州达到更低 WIS。ERA 通过 recombination 把 climatology baseline + 自回归 + ML + epidemiological renewal-equation 等不同范式混合,**最成功的 hybrid 是 CMU-climate-baseline + UMass-ar6-pooled + UMass-gbqr + CEPH-Rtrend-covid 的组合**——这种"统计稳健 + ML 响应 + 流行病学先验"的三合一架构是人类专家难以系统搜索出来的。
▍ 3. GIFT-Eval 时间序列 — 击败 5 月 2025 全 leaderboard
在 28 数据集 × 7 领域的 GIFT-Eval 基准上:• Per-dataset 模式:ERA 用 scikit-learn / statsmodels / xgboost 等通用库,**超过 May 18 2025 全 leaderboard,包括基础模型 (Time-LLM 等) 和深度学习模型**;• Unified 模式:ERA 自写一个"自适应配置"的通用预测库,8 个 preset hyperparameter 套餐 + validation 自选最佳——单一代码全 28 数据集通吃。
▍ 4. 其他生医/地理/科研任务
在 ZAPBench (斑马鱼 70,000 神经元 4D 影像)、地理分割、积分求解上,ERA 全部达 expert-level。论文还展示了在分子动力学 (Density Functional Theory 启发的 toy DFT 问题) 上,ERA 能自主提出"基于 rule-based construction"的全新数值方案——这是科研代码自动化的另一个范式跨越。
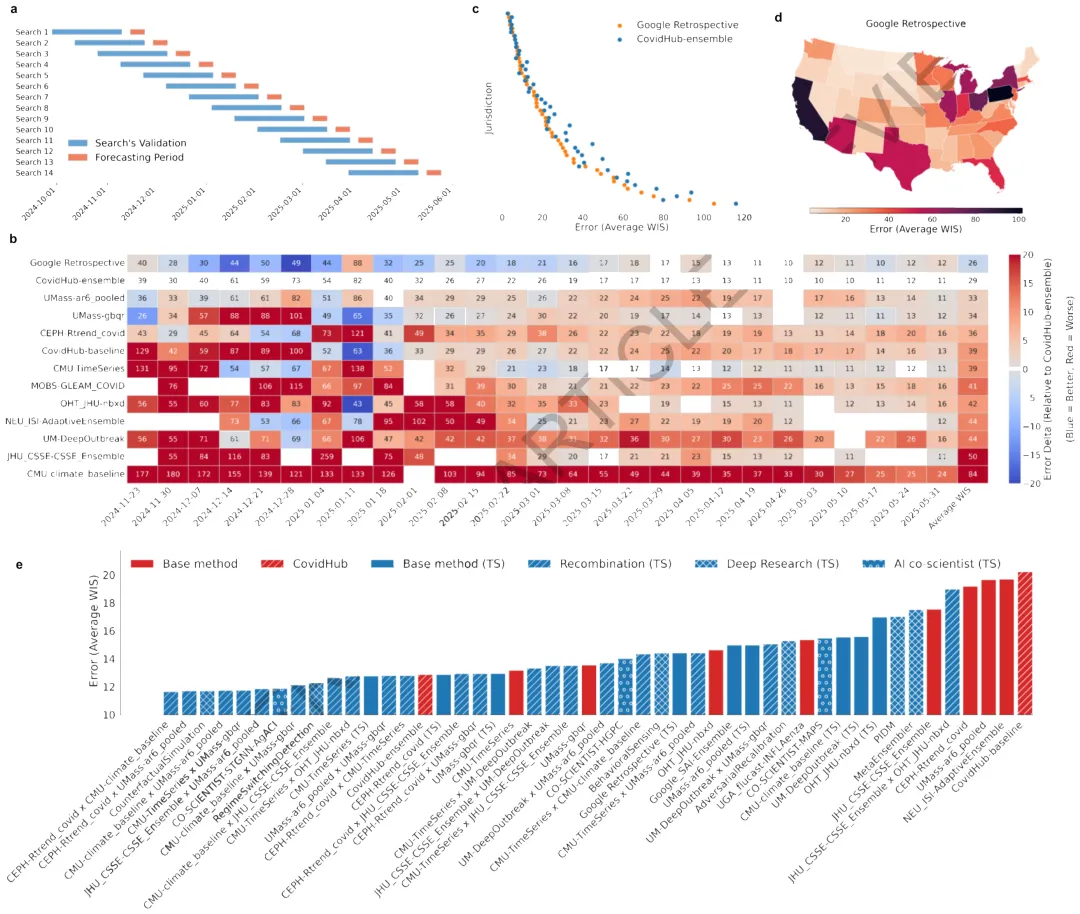
图 2 | ERA 在 6 大基准上的表现:scRNA-seq 批次校正(40 个新方法击败 OpenProblems leaderboard)+ CDC COVID 入院预测(14 模型击败 CDC Ensemble)+ GIFT-Eval 时序全 leaderboard 被超越。
五技术栈与原理
▍ 1. LLM Code Mutation 的本质 — "微生物进化"模型
把代码看成一个生物基因组,LLM 是"突变酶",评估器是"选择压力"。每一轮 ERA 让 LLM 读上一版代码 + 任务描述,生成新版本 (mutation);通过得分高低决定保留还是淘汰。**这本质上是 evolutionary search 的 LLM 版本**——但 LLM 的"知识带宽"远大于随机突变,所以收敛极快。
▍ 2. Tree Search 与单线程 mutation 的差距
单线 mutation 容易困死在 local optimum;tree search 维护多分支候选,使用 UCB1 / 类 AlphaGo 的 PUCT 公式决定哪个节点扩展,**保留 promising 但暂时打不破的"次优分支"**,后期当主分支停滞时回退继续。这是 ERA 比 AIDE 强的核心。
▍ 3. Research idea injection
关键创新:每个 mutation 步骤的 prompt 可以注入外部"研究想法",来源包括 (a) 高被引论文 PDF 的 Gemini 2.5 Pro 摘要;(b) 特定教科书段落;(c) search engine 现场检索结果;(d) Gemini Deep Research 或 AI Co-Scientist 自动产出的 hypotheses。**这把 ERA 从"代码 mutator"升级为"代码 + 科研创意 mutator"**。
▍ 4. Recombination — 把已有方法做"基因杂交"
在 scRNA-seq 上,ERA 程序化生成 11 个方法的所有 C(11,2)=55 对组合,把双亲的核心思想拼成一段 prompt 喂给 LLM;LLM 写出"杂交后代"代码,运行评估。**44% 的组合击败双方双亲**——这是首次有研究把"方法学杂交"自动化、规模化并量化。
▍ 5. Kaggle 校准 + 人手抽检 + embedding 多样性可视化
为防止 LLM 偷懒输出"漂亮但错"的代码,作者每个任务都有专家手动审核高分代码节点,确认其确实遵守任务约束;同时用 Gemini text embedding + cosine 距离把 ERA 生成的所有代码可视化,**确认其搜出来的解集真实多样化**(分群覆盖深度学习与非深度学习两大类)。
六讨论与意义
▍ 1. 科研生产力的新维度
ERA 把"代码写作"这一长期主导科研时间的环节自动化,效果不是"略好"而是"全面超过当下最强人类 + 最强基准"。这意味着任何有可打分指标的科研任务,理论上都能让 ERA 在数小时内产出 expert-level 实现——这是 AlphaFold 之后,AI for science 在"系统通用性"维度的又一次跨越。
▍ 2. 临床/产业价值
✅ 公共卫生预测 — CovidHub 等官方 Ensemble 可以被 ERA 直接增强,无需新建团队✅ 单细胞分析自动化 — 中等规模实验室不再需要专门的算法工程师就能跑出 SOTA-level 批次校正✅ 临床预测建模 — 凡是有 leaderboard / 评分指标的医学任务(影像分割、心电分类、风险预测)都可被 ERA 自动优化✅ 软件包加速研发 — 把 Nobel-prize 级的 DFT / 分子动力学软件让 ERA 提案下一代实现,可能压缩 10-20 年研发周期
▍ 3. 局限
(1) 只适用于"可打分"任务——开放式问题(无 ground truth metric)仍需人;(2) Tree search 计算量大,大任务下 cost 不低(虽然论文已展示 best-of-1000 LLM 不如 ERA 经济);(3) 输出代码仍需专家审核确认是否"作弊"(如学习到了 evaluation set 漏洞);(4) 多任务的代码 mutation 仍以 Python 为主,跨语言泛化未充分测试。
七结论
ERA 是首个让 LLM 与 Tree Search 协同写出"经过严格 leaderboard 验证、超越人类专家"的科研代码的系统。在 6 个差异极大的科研任务上 (scRNA-seq 批次校正 / CDC COVID 入院预测 / GIFT-Eval 时序 / ZAPBench 神经元活动 / 地理分割 / 数值积分) 全部达到 expert-level,**40 个新单细胞方法击败现有 leaderboard、14 个 COVID 模型击败官方 CDC Ensemble、整套 GIFT-Eval leaderboard 被超越**。
其一,"可打分科研任务"的人工瓶颈已被 AI 全面攻破——未来 5 年,任何有 leaderboard 的子领域都可能被 ERA 类系统"洗一遍"。其二,**Recombination + tree search + research idea injection** 这种组合是新的"科研创意工厂",能把人类专家几十年积累的方法学做自动化杂交。其三,**Gemini Deep Research + AI Co-Scientist + ERA** 形成了一个 hypothesis → idea → code → benchmark 的完整闭环——这是 AI for science 从"工具人"到"虚拟同事"的跨越。
八原文信息
原文标题An AI system to help scientists write expert-level empirical software
作者Eser Aygün*, Anastasiya Belyaeva*, Gheorghe Comanici*, Marc Coram*, Hao Cui*, Jake Garrison*, Renee Johnston*, Anton Kast*, Cory Y. McLean*, Peter Norgaard*, Zahra Shamsi*, David Smalling*, James Thompson*, Subhashini Venugopalan*, Brian P. Williams, Chujun He**, Sarah Martinson**, Martyna Plomecka**, Lai Wei, Yuchen Zhou, Qian-Ze Zhu**, Matthew Abraham, Erica Brand, Anna Bulanova, Jeffrey A. Cardille, Chris Co, Scott Ellsworth, Grace Joseph, Malcolm Kane, Ryan Krueger**, Johan Kartiwa, Dan Liebling, Jan-Matthis Lueckmann, Paul Raccuglia, Xuefei (Julie) Wang**, Katherine Chou, James Manyika, Yossi Matias, John C. Platt, Lizzie Dorfman, Shibl Mourad†, Michael P. Brenner†
单位Google DeepMind, Montréal & New York · Google Research, Cambridge · Google Platforms & Devices, Mountain View · MIT · Harvard SEAS · McGill · Caltech
期刊Nature (Accelerated Article Preview, 2026)DOIhttps://doi.org/10.1038/s41586-026-10658-6
核心方法LLM-driven code mutation + Tree Search (类 AlphaGo PUCT) + 高被引论文/教科书 idea injection + Recombination of base methods
6 大基准OpenProblems v2.0.0 (scRNA-seq batch) · CovidHub (CDC COVID hospitalization) · GIFT-Eval (28 时序数据集) · ZAPBench (斑马鱼 70K 神经元) · 地理影像分割 · 数值积分
关键词Tree Search; Generative AI; Scorable Scientific Tasks; Empirical Software; LLM code mutation; OpenProblems; CovidHub; GIFT-Eval; AI for Science
—— ◆ ——
— END —
本文仅用于学术研究分享,图片均来源于原文献,版权归原作者和期刊所有。
