夜雨聆风
夜雨聆风阅读导引:
传统数据产品架构拆解
AI新数据产品架构
新架构分阶段实施
实施保障说明
正文开始:
在跨境电商竞争日趋白热化的今天,“数据驱动”早已不是选择题,而是生存题。多平台、多语言、多场景的复杂业务特性,让传统运营模式难以为继,AI+数据的深度融合,成为跨境卖家突破增长瓶颈、构建核心壁垒的关键。
今天,我们就来拆解一套可落地、可量化的跨境电商AI数据产品架构实施路线图,从基础筑基到生态领先,一步步实现从“看数”到“用数”,再到“智能决策”的跨越,助力跨境业务高效增长。
一、传统数据产品架构拆解:
传统架构以离线批处理、人工驱动、烟囱式建设为核心,适配跨境电商早期 “多平台分散运营、报表驱动决策” 的需求,核心是解决 “数据存得下、报表出得来” 的基础问题。
1、核心架构分层(五层模型)
(1)数据采集层:多源异构、手动为主
数据源:覆盖亚马逊 / Shopee 等电商平台、ERP、WMS、物流商、支付网关、广告平台(Facebook/Google)、税务系统等,数据格式含结构化(订单 / 库存)、半结构化(API 日志)、非结构化(评论 / 图片)。
采集方式:以定时脚本 + API 拉取 + 数据库直连为主,依赖人工配置同步任务;无统一采集入口,多为点对点对接,形成 “数据蜘蛛网”。
痛点:跨平台数据同步延迟高(T+1 为主)、数据丢失 / 重复频发、人工维护成本极高。
(2)数据存储层:数仓主导、孤岛林立
存储架构:采用OLTP 数据库(MySQL/PostgreSQL)+ 离线数仓(Redshift/BigQuery) 分离模式;结构化数据入数仓,非结构化数据零散存储在对象存储或业务系统中。
数据建模:遵循传统数仓建模(ODS-DWD-DWS-ADS),依赖人工预建宽表,维度组合固化,无法灵活适配跨境多区域、多品类的分析需求。
痛点:数据孤岛严重(平台数据、供应链数据、营销数据割裂)、非结构化数据无法有效利用、存储扩展性差。
(3)数据计算层:离线批处理、人工开发
计算模式:以Spark/Hive 离线批处理为核心,T+1 生成报表;少量实时场景用 Flink,但仅覆盖订单监控等基础场景。
计算逻辑:所有指标(ROAS、ACOS、库存周转、退货率)均由数据工程师硬编码 ETL 脚本实现,业务口径变更需重新开发、回刷数据。
痛点:计算延迟高、响应业务需求慢(需求到上线需 1-2 周)、人工成本高、技术债务累积。
(4)数据服务层:接口固化、复用性差
服务形式:提供固定报表 API、看板数据接口,无统一数据服务网关;数据口径分散在各业务线,同一指标(如 “有效订单”)多部门定义不一致。
服务能力:仅支持预设查询,无法应对运营人员的发散性分析需求(如 “对比欧美市场 TikTok 与 Facebook 广告对 A 品类新客的 ROI”)。
痛点:服务复用率低、数据口径混乱、取数门槛高(需懂 SQL)。
(5)数据应用层:报表驱动、被动决策
核心应用:以固定看板、周 / 月报表、Excel 分析为主,覆盖销售统计、库存监控、财务核算、广告效果复盘等场景。
用户交互:运营 / 分析师手动导出数据、整理报表,决策依赖人工解读历史数据,无预测、无智能推荐。
痛点:决策滞后、分析深度浅、无法支撑实时运营优化(如旺季库存调整、突发营销活动)。
2、传统架构核心痛点(跨境电商专属)
数据孤岛:多平台、多系统数据割裂,无法实现全链路(营销 - 订单 - 供应链 - 物流)数据分析。
口径混乱:跨境多区域、多币种、多平台导致指标定义不一致,财务与运营数据对账困难。
实时性差:旺季订单、广告流量爆发时,无法实时监控 ROI、库存,易出现超卖 / 缺货。
人力依赖:数据采集、清洗、建模、报表全流程依赖人工,规模扩张后成本指数级增长。
二、新AI数据产品架构
新架构以湖仓一体为底座、AI 大模型为大脑、实时流处理为神经、自然语言交互为入口,实现 “数据自动流动、模型自主决策、业务实时优化” 的闭环,彻底解决传统架构痛点。
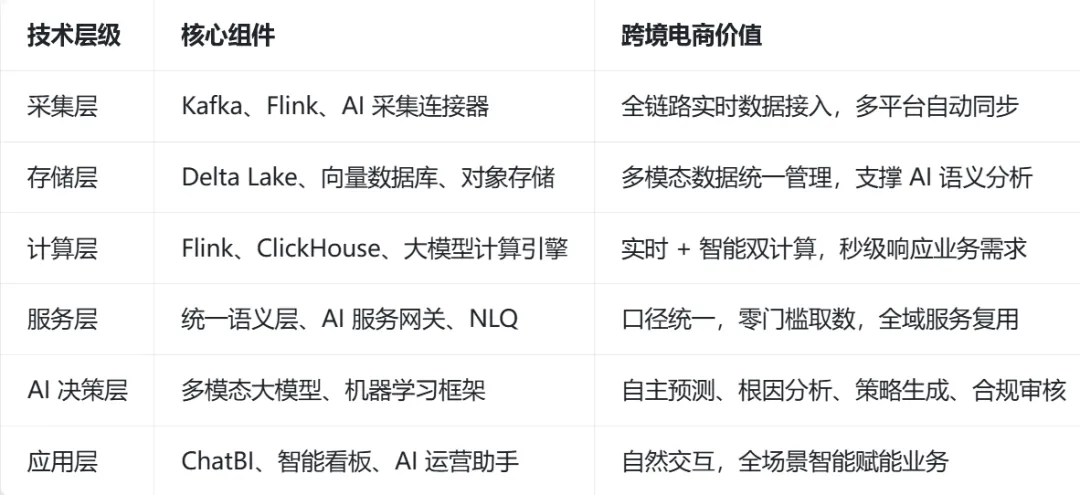
1.核心架构升级(六层 AI 原生模型)
(1)数据采集层:AI 驱动、全域实时接入
升级点:从 “手动定时” 变为AI 自动采集 + 实时流接入,覆盖全链路数据。
多源统一接入:通过预置跨境数据源连接器(亚马逊 / Shopee/ERP/WMS/ 物流 / 广告),自动拉取结构化 / 半结构化 / 非结构化数据,无需人工配置。
AI 数据清洗:大模型自动识别脏数据(重复 / 缺失 / 错误)、标准化多币种 / 多语言数据、补全缺失字段,清洗效率提升 90% 以上。
实时流采集:用 Kafka+Flink 实现订单、广告点击、物流轨迹等数据的毫秒级采集,支撑实时决策。
核心价值:消除数据采集盲区,数据一致性、实时性、完整性全面提升。
(2)数据存储层:湖仓一体、多模态统一管理
升级点:从 “数仓 + 零散存储” 变为湖仓一体(Data Lakehouse),统一管理结构化、半结构化、非结构化数据。
存储架构:底层用对象存储(S3/COS)存原始数据,上层用 Delta Lake/Iceberg 构建事务层,兼具数据湖的灵活性与数仓的治理能力。
多模态存储:统一存储订单数据、用户行为、商品图片 / 视频、多语言评论、物流轨迹、广告素材等,支持跨模态分析。
向量数据库:新增向量数据库(Pinecone/FAISS),存储商品、用户、评论的向量 embedding,支撑 AI 语义检索、推荐、相似性分析。
核心价值:打破数据孤岛,实现全域数据统一存储、统一治理,支撑 AI 多模态分析。
(3)数据计算层:实时 + AI 双引擎、自主建模
升级点:从 “离线批处理 + 人工编码” 变为实时流计算 + AI 智能计算双引擎,计算逻辑自主生成。
实时计算引擎:Flink+ClickHouse 支撑毫秒级实时指标计算(如实时 ROAS、实时库存、实时物流时效),覆盖旺季监控、突发营销场景。
AI 计算引擎:大模型 + 机器学习框架(TensorFlow/PyTorch)自动完成数据建模、指标计算、根因分析;无需人工写 ETL,业务口径变更自动适配。
自助计算:支持业务人员通过自然语言生成计算逻辑,平台自动解析、执行、输出结果。
核心价值:计算实时化、智能化,响应业务需求从 “周级” 降至 “秒级”,大幅降低数据团队人力成本。
(4)数据服务层:统一语义 + AI 服务网关、全域复用
升级点:从 “固化接口 + 口径混乱” 变为统一语义层 + AI 服务网关,实现数据服务全域复用、口径唯一。
统一语义层:AI 自动构建跨境电商全域指标体系(ROAS、ACOS、库存周转、退货率、现金周转周期等),统一指标定义、计算逻辑、数据口径,消除部门间数据差异。
AI 服务网关:提供标准化 API、自然语言查询(NLQ)、向量检索接口,支撑前端应用、AI 模型、自动化系统调用。
服务编排:AI 自动编排数据服务,支持复杂业务场景(如 “分区域分品类广告预算优化”)的一站式数据调用。
核心价值:实现 “一处定义、全域使用”,数据服务复用率提升 80%,取数门槛降至零。
(5)AI 决策层:大模型驱动、自主决策闭环(新增核心层)
核心定位:新架构的 “大脑”,替代传统人工分析与决策,实现从 “数据支撑” 到 “数据驱动” 的质变。
智能预测:自动预测分区域 / 分品类销量、库存需求、广告效果、物流时效,准确率提升 30%+。
根因分析:自动定位销量下滑、退货率上升、广告 ROI 降低的核心原因(如竞品降价、物流延迟、评论差评)。
策略生成:自动生成运营优化策略(如广告预算分配、商品定价、库存补货、Listing 优化),并模拟效果。
合规审核:自动审核多区域税务、海关、平台规则合规性,规避合规风险。
多模态大模型:集成 GPT-4o、文心一言等大模型,具备多语言理解、多模态分析、自主决策能力。
核心能力:
决策闭环:AI 决策结果直接推送至执行层(ERP / 广告平台 / 物流系统),实现 “分析 - 决策 - 执行 - 反馈” 的全自动闭环。
核心价值:决策从 “人工经验” 变为 “AI 智能”,响应速度、精准度、覆盖度全面提升。
(6)数据应用层:自然交互、全场景智能赋能
升级点:从 “固定报表 + 手动分析” 变为自然语言交互 + 全场景智能应用,覆盖运营、营销、供应链、财务全链路。
营销端:AI 自动优化广告投放、生成多语言 Listing、智能推荐商品、精准用户画像。
供应链端:智能库存补货、分仓调拨、物流路径优化、头程 / 尾程成本核算。
客服端:AI 多语言客服、自动处理差评、舆情监控与应对。
财务端:自动多币种核算、利润分析、现金流预测、税务申报辅助。
ChatBI 交互:运营 / 管理层用日常语言提问(如 “分析欧洲站 Q2 销量下滑原因,并给出 3 个优化方案”),AI 自动生成分析报告、可视化图表、执行建议。
智能看板:实时动态看板,自动预警异常(如库存不足、广告 ROI 低于阈值、物流延迟),并联动 AI 给出解决方案。
全场景应用:
核心价值:全员可用数据,业务全链路智能化,运营效率提升 50%+。
2.新架构核心技术组件
3.新架构核心优势(对比传统)
全域数据打通:湖仓一体 + 统一语义层,彻底消除跨境多平台、多系统数据孤岛。
实时智能决策:实时流计算 + AI 大模型,实现毫秒级数据处理与自主决策,支撑旺季快速响应。
零门槛数据使用:自然语言交互,业务人员无需懂技术,直接获取数据洞察与执行方案。
全链路自动化:从采集、清洗、计算到决策、执行全流程 AI 驱动,人力成本降低 70%+。
多模态分析能力:支持文本、图片、视频、音频等多模态数据分析,挖掘非结构化数据价值。
弹性扩展:云原生 + Serverless 架构,适配跨境电商业务波动(如黑五、旺季),按需扩展资源。
三、新架构分阶段实施
整个实施过程遵循“基础筑基→AI赋能→闭环优化→生态领先”的路径,每个阶段有明确目标、关键任务和里程碑,兼顾技术可行性与业务价值快速兑现,避免盲目投入。
阶段一:基础筑基期
核心目标:
解决数据孤岛问题,搭建统一的数据底座和指标体系,为后续AI能力落地筑牢基础,让数据从“杂乱无章”变得“有序可用”。
关键任务重点推进三点:
一是数据盘点与接入,优先接入亚马逊、Shopee、TikTok Shop、速卖通、独立站(Shopify)等10+核心平台,覆盖订单、流量、广告、库存、物流、评论、财务、汇率等核心数据,通过API对接、CDC、爬虫等技术,结合Airbyte、Flink、Kafka等工具,实现数据定时同步与实时采集。
二是数据治理与标准化,制定统一的指标字典,明确GMV、ACoS、ROI、转化率、库存周转、退款率等50+核心指标的口径,建立数据清洗规则,处理数据去重、补全、异常值等问题,同时实现多语言数据归一,搭建数据质量监控机制,对字段缺失、数据突变、延迟等情况进行告警。
三是湖仓基础建设与基础看板上线,搭建湖仓一体的存储架构,建立用户、商品、订单、广告、供应链、财务等主题模型,同时上线核心运营看板,实现销售、广告、库存、财务等数据的实时监控,将数据需求响应时间从3-5天缩短至1-2天。
本阶段里程碑:
完成10+核心数据源接入,50+核心指标标准化;
统一数据仓库上线,基础运营看板可用;
数据质量合格率≥95%。
阶段二:AI能力构建期
核心目标:
从“看数”升级为“用数”,构建核心AI能力,落地高价值业务场景,让AI真正为运营减负、提效、增收。
关键任务分为三大模块:
首先是AI基础设施搭建,搭建统一的特征平台,实现特征的存储、复用与在线/离线服务,同时搭建模型训练与推理平台,支持机器学习、深度学习、大模型微调,采用MLflow、TensorFlow、PyTorch、向量数据库(Pinecone)等工具,完善AI技术底座。
其次是核心AI模型开发与部署,聚焦四大高价值场景:智能选品(实现市场趋势分析、竞品分析、爆款预测、需求预测,准确率≥85%)、智能广告(实现关键词挖掘、智能出价、ROI归因、预算优化,目标ACoS降低30%+)、智能客服(实现多语言NLP、情绪识别、自动回复、工单分流,响应时间<10s)、供应链预测(实现库存预警、补货建议、物流时效预测,断货率降低40%)。
最后是数据服务开放,提供统一API接口(不少于300个),支持业务系统、RPA、第三方工具对接,同时搭建自助分析平台,让业务人员无需技术支持,即可自主取数、制作报表,提升数据使用效率。
本阶段里程碑:
4大核心AI模型上线,试点场景验证有效;
广告ROI提升50%+,运营效率提升2倍;
数据服务API全面开放,支持业务自助分析。
阶段三:全链路智能闭环期
核心目标:
打通“数据→AI决策→自动执行→反馈优化”的全链路闭环,实现运营决策自动化、执行一体化,大幅降低人力成本,提升决策效率。
关键任务重点突破四点:
一是搭建智能决策中枢,整合多模型输出结果,形成统一的决策引擎,覆盖价格调整、库存分配、广告启停、Listing优化等核心运营场景,支持规则+AI混合决策,兼顾效率与安全。
二是构建自动执行层,通过对接平台API+RPA工具,实现自动上架、调价、广告投放、订单处理、评论回复等日常运营操作,同时实现多语言自动翻译、合规审查(覆盖欧盟GDPR、各国电商法),减少人工干预。
三是建立闭环优化机制,将执行结果实时回传至AI引擎,实现模型持续迭代,同时搭建A/B测试平台,通过策略对比、效果量化,快速优化AI决策方案。
四是深化垂直行业适配,针对3C、家居、服装等跨境热门垂直品类,优化行业专属模型与规则,提升AI决策的精准度。
本阶段里程碑:
80%日常运营决策由AI自动生成并执行;
决策响应时间从天级压缩至分钟级,人力成本降低50%+;
垂直行业解决方案成熟,可复制推广。
阶段四:生态扩展与领先期
核心目标:
构建开放生态,探索前沿AI技术,形成核心竞争壁垒,成为跨境电商AI数据产品领域的标杆,支撑业务全球化扩张。
关键任务聚焦三大方向:
一是开放平台建设,开放API/SDK接口,支持第三方开发者、服务商接入,打造专属应用市场,汇聚选品、广告、物流、金融等各类垂直应用,丰富生态场景。
二是前沿技术探索,重点布局多模态AI(图片/视频生成、直播智能分析)、大模型深度应用(跨境运营专家AI、数字人客服、市场洞察报告自动生成),同时强化数据安全与隐私保护,采用联邦学习、差分隐私等技术,满足全球合规要求。
三是全球化扩展,适配东南亚、欧洲、拉美等新兴市场的本地化数据与合规要求,实现多语种、多币种、多税制的智能适配,支撑业务全球化布局。
本阶段里程碑:
开放生态上线,第三方应用≥50个;
多模态AI、大模型应用全面落地,创新场景规模化;
成为行业AI数据产品标杆,市场份额领先。
四、技术选型与实施保障
要确保路线图顺利落地,合理的技术选型和完善的实施保障必不可少,避免“技术脱节”“业务脱节”等问题。
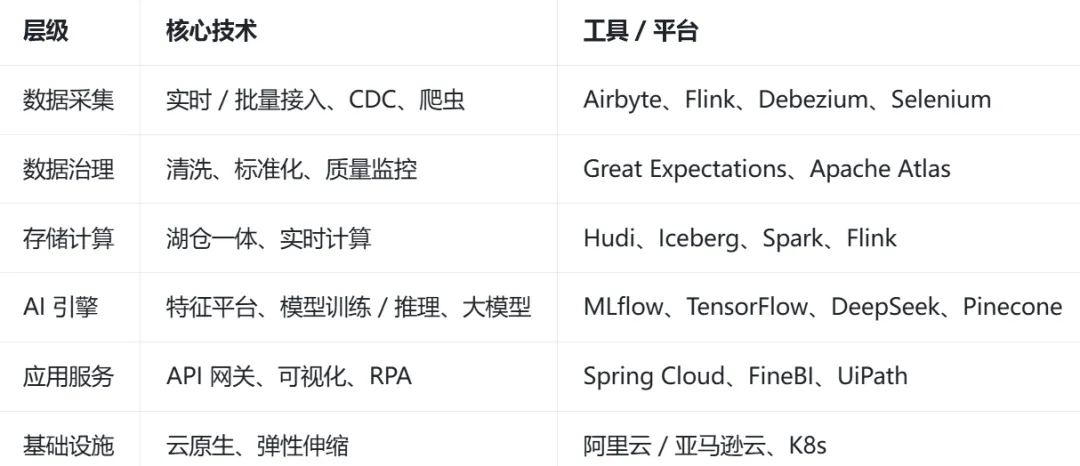
在技术选型上,坚持“适配业务、灵活可扩展”的原则,核心技术栈如下:
数据采集层采用实时/批量接入、CDC、爬虫技术,搭配Airbyte、Flink、Debezium、Selenium等工具;
数据治理层依托Great Expectations、Apache Atlas等工具,实现数据清洗、标准化与质量监控;
存储计算层采用湖仓一体架构,搭配Hudi、Iceberg、Spark、Flink等工具,兼顾存储灵活性与计算高效性;
AI引擎层采用MLflow、TensorFlow、DeepSeek、Pinecone等工具,支撑模型训练、推理与大模型应用;
应用服务层采用Spring Cloud、FineBI、UiPath等工具,实现API网关、可视化与RPA自动执行;
基础设施采用云原生技术,搭配阿里云/亚马逊云、K8s,实现弹性伸缩,适配业务增长需求。
在实施保障上,重点做好三点:
一是组织保障,成立跨部门项目组,由数据产品经理牵头,联合数据、AI、业务、IT、合规等多个部门,确保业务需求与技术落地同频;
二是风险控制,合规先行,严格遵守GDPR、数据安全法等相关规定,做好数据脱敏、加密与权限管控,同时采用小步快跑、灰度发布、快速回滚机制,降低技术与业务风险,坚持“先试点再推广”,量化效果、快速迭代;
三是价值量化,每个阶段设定明确的KPI,聚焦效率提升、成本降低、收入增长,定期复盘,及时调整路线,确保投入产出比。
总之
跨境电商的竞争,本质上是数据与技术的竞争。这套AI数据产品架构实施路线图,不追求“一步到位”,而是“小步快跑、稳步落地”,让每一个阶段都能兑现业务价值,让AI真正成为跨境业务增长的“加速器”。
后续将持续拆解各阶段的具体执行细节,助力每一位跨境从业者,都能借助AI+数据的力量,突破增长瓶颈,实现高质量发展~
~END~
🎖关注我的公众号,了解更多数据相关信息