 夜雨聆风
夜雨聆风做 IT 运维,工具其实非常多,但真正落地到企业现场之后,会发现一个问题:
工具不是越多越好,而是能不能把设备、IP、配置、巡检、告警、知识库和故障处理串起来。
很多企业的实际情况是: 设备台账在 Excel 里,IP 地址在另一个表里,配置备份靠脚本,巡检靠人工命令,故障排查靠经验,知识库又散落在文档、聊天记录和个人笔记里。
所以我理解的 IT 运维工具,不应该只是“能用的工具清单”,而应该按照运维场景来分类。
一、资产管理类工具
资产管理是 IT 运维的基础。
常见工具包括:
Excel / WPS 表格 GLPI iTop Snipe-IT NetBox Nautobot 自研 CMDB
这类工具主要解决几个问题:
有多少设备 设备在哪里 谁在使用 什么时候上线 属于哪个系统或业务 资产生命周期如何管理
在网络和基础架构场景里,单纯的资产管理还不够,还需要关注:
设备 IP 厂商 型号 序列号 软件版本 管理地址 所属机房 / 机柜 上联关系 配置备份状态 巡检状态
很多时候,资产数据最大的问题不是“没有系统”,而是系统里的数据不准。
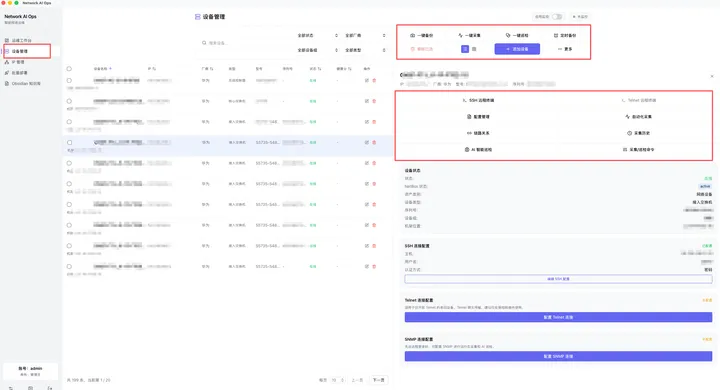
所以我现在更倾向于把资产管理和自动化采集结合起来,让系统可以从设备上自动采集型号、版本、序列号等信息,然后反向校准资产台账。
二、IP 地址管理工具,也就是 IPAM
IPAM 是很多企业容易忽略,但实际非常重要的一类工具。
常见工具包括:
phpIPAM NetBox IPAM GestióIP Infoblox BlueCat Excel 表格
很多企业仍然用 Excel 管 IP 地址,这种方式前期很方便,但一旦网络规模变大,就会出现很多问题:
IP 是否已使用不清楚 设备实际占用和表格记录不一致 MAC 地址和 IP 关系不明确 不知道某个 IP 接在哪台交换机上 VLAN、子网、地址段之间缺少关联 离职、搬迁、替换设备后记录没有同步更新
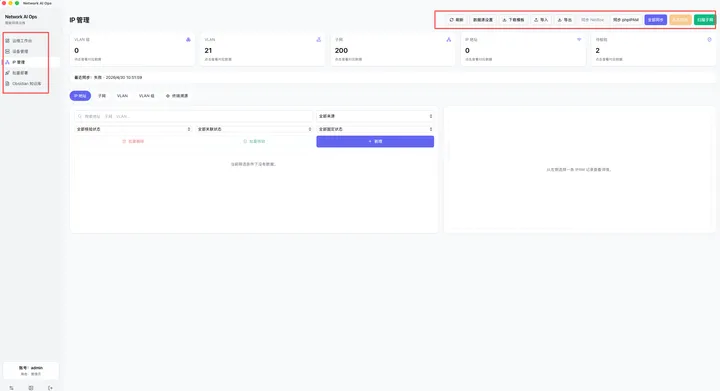
我觉得 IPAM 真正有价值的地方,不只是登记 IP,而是要和现场网络数据关联起来。
比如:
从 ARP 表发现 IP 和 MAC 从交换机 MAC 地址表定位接入端口 关联到接入交换机 关联到接口 关联到 VLAN 再沉淀到 IPAM 记录里
这样 IPAM 才不是一个静态地址表,而是一个能反映现场状态的动态资产视图。
我自己的工具 Network AI Ops 里也把 IPAM 作为核心模块之一,支持 IP 地址、MAC、关联设备、学习接口、描述和备注等字段搜索,也支持通过采集结果把 ARP 发现的地址写入 IPAM。
三、远程终端和批量命令工具
运维人员最常用的工具,一定少不了远程终端。
常见工具包括:
Xshell SecureCRT MobaXterm Tabby Termius PuTTY Windows Terminal iTerm2 OpenSSH
这些工具解决的是登录和操作问题。
但在企业运维场景里,单纯能 SSH 上去还不够。实际使用中还会需要:
统一管理设备登录信息 快速打开 SSH / Telnet 常用命令模板 多厂商命令区分 Linux 和网络设备命令区分 会话保持 全屏终端 页面切换不中断 批量命令执行 命令执行结果留痕
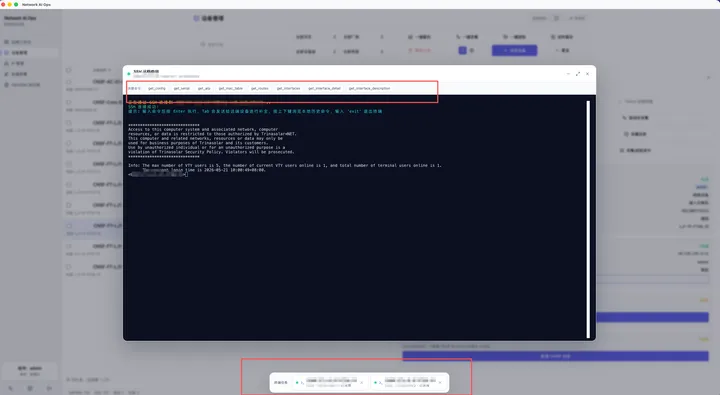
传统终端工具很强,但它更多是“个人工具”。 如果要做团队级、平台级运维,就需要把终端能力和资产管理、权限管理、采集任务、巡检报告结合起来。
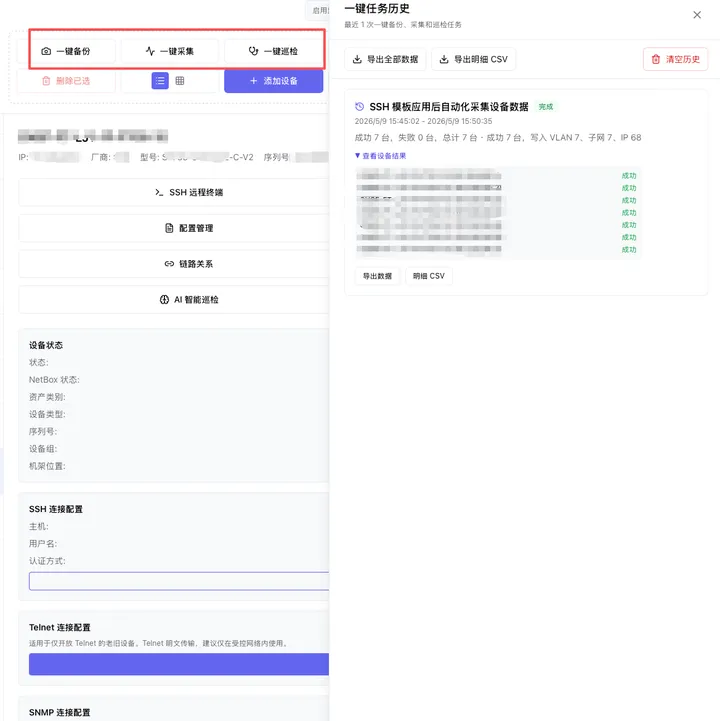
比如这次我在 Network AI Ops v1.1.5 中重点优化了远程终端能力:
支持 SSH / Telnet 远程终端 支持 Linux 服务器纳管 支持终端最小化 支持全屏 支持后台会话保持 支持页面切换不中断 支持常用命令快捷入口 Tab 键可以直接发送给远端系统做原生命令补全
这样终端就不再是一个临时窗口,而是平台化运维的一部分。
四、监控和告警工具
监控是 IT 运维绕不开的一类工具。
常见工具包括:
Zabbix Prometheus Grafana LibreNMS Cacti Nagios Open-Falcon 夜莺 WGCLOUD Uptime Kuma
监控工具主要解决:
设备是否在线 CPU / 内存 / 磁盘是否异常 接口流量是否异常 服务是否可用 告警是否及时触达 历史趋势是否可追溯
网络运维里,LibreNMS、Zabbix、Prometheus + Grafana 都比较常见。
但监控平台也有一个典型问题: 它能告诉你有问题,但不一定能告诉你为什么。
比如一个接口告警,可能背后涉及:
物理链路问题 光模块问题 对端设备问题 环路问题 配置变更问题 上游业务流量突增 设备性能瓶颈
所以监控系统最好能和自动化采集、配置备份、日志分析、AI 分析结合起来。否则告警越多,运维人员越容易麻木。
这也是我认为 AIOps 后续真正有价值的方向:不是简单地“告警通知”,而是自动做证据收集、告警降噪和根因分析。
五、日志分析工具
日志类工具主要用于排障、审计和安全分析。
常见工具包括:
ELK / Elastic Stack OpenSearch Loki Graylog Splunk Kafka + ClickHouse rsyslog / syslog-ng
日志系统在服务器、网络、安全场景中都很重要。
常见用途包括:
Linux 系统日志分析 应用日志分析 防火墙日志分析 VPN 日志分析 交换机日志分析 安全事件分析 操作审计 故障追溯
但日志工具的痛点也很明显:
日志量大 噪声多 查询门槛高 需要懂字段和语法 很难直接给出结论
所以日志系统和 AI 结合会有很大价值。 比如把告警、日志、设备状态、配置变更、巡检结果放在一起,让 AI 帮助运维人员做关联分析。
不过这里要注意一点:AI 分析不能完全替代工程师判断,尤其是生产网络和核心系统,最终操作仍然需要人工确认。
六、配置备份和自动化工具
网络运维里,配置备份是非常基础但很容易被忽略的工作。
常见工具和方案包括:
Oxidized RANCID Ansible Nornir Netmiko Napalm Python 脚本 自研批量备份平台
配置备份主要解决:
设备配置是否有备份 变更前后能否对比 故障时能否回滚 离职交接是否有依据 是否符合审计要求
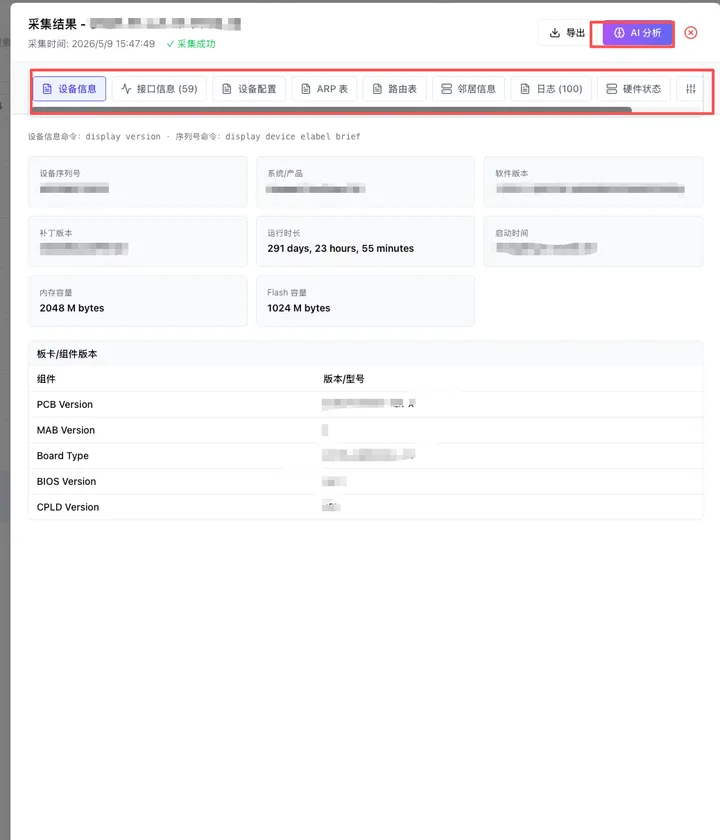
在实际环境里,配置备份最好和设备资产管理结合起来。 也就是说,不要单独维护一套备份设备清单,而是从资产台账里直接选择设备,一键执行备份、采集和巡检。
我自己的思路也是这样:
设备先进入资产库 然后可以执行一键采集 一键备份 一键巡检 采集结果进入报告 关键字段同步到 IPAM 或资产信息
这样可以减少重复维护多套数据的成本。
七、知识库和文档工具
运维工作非常依赖经验沉淀。
常见工具包括:
Confluence Wiki.js GitBook Notion 飞书文档 语雀 Obsidian MkDocs Docusaurus
知识库主要沉淀:
故障处理流程 设备命令模板 变更方案 应急预案 网络拓扑说明 系统架构说明 厂商设备差异 常见问题处理经验
很多团队的问题是: 故障处理经验都在个人脑子里,或者散落在聊天记录里。
所以我个人比较喜欢把运维知识库和工具平台结合起来。比如:
命令模板来自知识库 故障处理流程来自知识库 AI 分析可以参考知识库 巡检报告可以沉淀到知识库 故障案例可以反向补充知识库
这样知识库就不是一个“写完没人看的文档系统”,而是可以参与运维流程的经验底座。
八、AI 运维工具和 AIOps 平台
最近几年,AIOps 的概念很热。
但我个人理解,真正有价值的 AI 运维不是简单接一个大模型聊天窗口,而是要让 AI 参与真实运维流程。
比如:
自动采集设备状态 自动收集故障证据 自动分析配置差异 自动识别异常风险 自动生成巡检报告 自动关联 IP、MAC、接口和设备 自动沉淀排障经验 在关键操作前给出风险提示
也就是说,AI 不能只会回答“交换机怎么配置 VLAN”,而应该能结合当前环境数据,帮你判断:
这台设备现在是否异常 这个接口是否有风险 这个 IP 是否已经入库 这个 MAC 接在哪个交换机端口 这次巡检有哪些重点问题 哪些采集结果需要人工关注
我自己正在做的 Network AI Ops,就是沿着这个方向去设计的。
它目前主要包括:
设备资产管理 Linux 服务器纳管 SSH / Telnet 远程终端 IPAM 地址管理 自动化采集 配置备份 批量命令 AI 巡检报告 提示词模板配置 Obsidian 知识库联动 企业主控和子客户端能力
这次 v1.1.5 版本重点增强了几个能力:
支持 Linux 服务器作为资产类型纳管 远程终端支持后台会话保持、最小化和全屏 支持常用命令快捷入口 支持设备序列号等资产信息自动识别 IPAM 支持按 MAC、关联设备、学习接口、备注等字段搜索 ARP 采集结果可以自动写入 IPAM AI 巡检支持提示词模板,可以按现场关注点调整报告结构
我觉得这些能力比单纯做一个“AI 问答页面”更重要。 因为企业运维真正需要的是流程闭环,而不是单点工具。
【插图建议 5:放你的“AI 巡检报告 / AI 分析”页面截图】 建议展示 AI 巡检报告、提示词模板、风险分析、建议项等内容。 如果报告里有设备真实信息,建议替换成测试数据。
九、我现在更推荐的运维工具组合
如果是中小企业或园区网络,我会建议这样的组合:
资产与 IPAM
NetBox / phpIPAM / 自研平台 或者直接使用一体化平台管理设备和 IP
监控
Zabbix LibreNMS Prometheus + Grafana
日志
ELK / OpenSearch Loki Graylog
自动化
Ansible Python + Netmiko / Nornir 自研采集和备份工具
远程终端
Xshell / SecureCRT / MobaXterm 平台内置 SSH / Telnet 终端
知识库
Obsidian Wiki.js Confluence 飞书文档 / 语雀
AI 运维
本地大模型 Dify / Coze / FastGPT 自研 AIOps 平台 结合实际数据的智能巡检和故障分析系统
如果只是个人学习,工具可以分散一些; 如果是企业生产环境,最好逐步往平台化、一体化方向走。
十、最后说一下我的理解
IT 运维工具的价值,不在于工具本身有多复杂,而在于它能不能减少重复劳动、降低人为失误、提升问题定位效率。
早期运维更多依赖人:
人工登录设备 人工执行命令 人工复制结果 人工写巡检报告 人工维护 Excel 人工判断故障原因
但未来的运维平台应该逐步做到:
资产自动校准 配置自动备份 状态自动采集 IP 自动关联 告警自动降噪 故障自动取证 巡检自动生成 经验自动沉淀
这也是我做 Network AI Ops 的原因。
我希望它不是一个简单的工具集合,而是一个面向真实企业现场的 AI 网络运维控制台。 从设备管理、IPAM、SSH 终端、自动化采集、配置备份,到 AI 巡检和后续故障诊断,逐步形成一个完整的运维闭环。
如果你也是做网络运维、基础架构、企业 IT 或制造业基地 IT 的,可以一起交流真实现场里最难解决的问题。
目前 Network AI Ops 还在持续迭代和小范围内测中。
如果你也是做网络运维、基础架构、企业 IT、园区网络或制造业基地 IT 的,欢迎交流真实运维场景。后续我也会开放一批内测名额,优先邀请有真实设备管理、IPAM、巡检、配置备份和自动化运维需求的朋友一起测试。
