 夜雨聆风
夜雨聆风> 上月 Claude Code 源码泄露,作为目前最成功的工业级 AI agent 之一,其架构设计值得深入学习。本文不纠结代码实现细节,只聚焦设计范式——即 Harness Engineering,深度解析下 AI 从 Demo 到生产级落地核心痛点的系统化工程方法论。
1. Agent Loop:双层循环
> 核心:将"会话周期"与"模型调用循环"进行解耦与隔离,为 Agent 系统奠定了高弹性、易维护且高度可控的工程化基石。
1.0 简单 React Loop 的问题
简单 React Loop 是一个单层循环:
while (模型调用工具) { 执行工具 → 注入结果 → 继续调用}返回最终回答
单层循环有三个根本性问题:
问题 | 表现 | 后果 |
状态混淆 | 会话状态(历史消息、累计花销、权限) 和 单轮状态(当前要执行什么工具、结果如何)混在同一个循环里 | 代码纠缠,难以单独测试某个能力 |
预算失控 | Token 预算、USD 成本、最大轮次 全都在循环内判断 | 当一个会话跑了 50 轮后,突然告知"超预算"——之前的钱和时间都浪费了 |
恢复粒度粗 | 遇到 PTL 错误(上下文太长)只能终止循环告诉用户"上下文满了" | 用户体验断裂,要么手动压缩,要么从头开始 |
这三个问题的根源:单层循环把"会话管理"和"单轮执行"这两个不同生命周期的职责揉在了一起。
1.1 Claude Code 的答案:双层循环
内层循环就是“单轮任务”的执行引擎,外层循环就是“整场对话”的管理员。
Claude Code 将 Agent Loop 拆成两个各自有明确职责的层次:
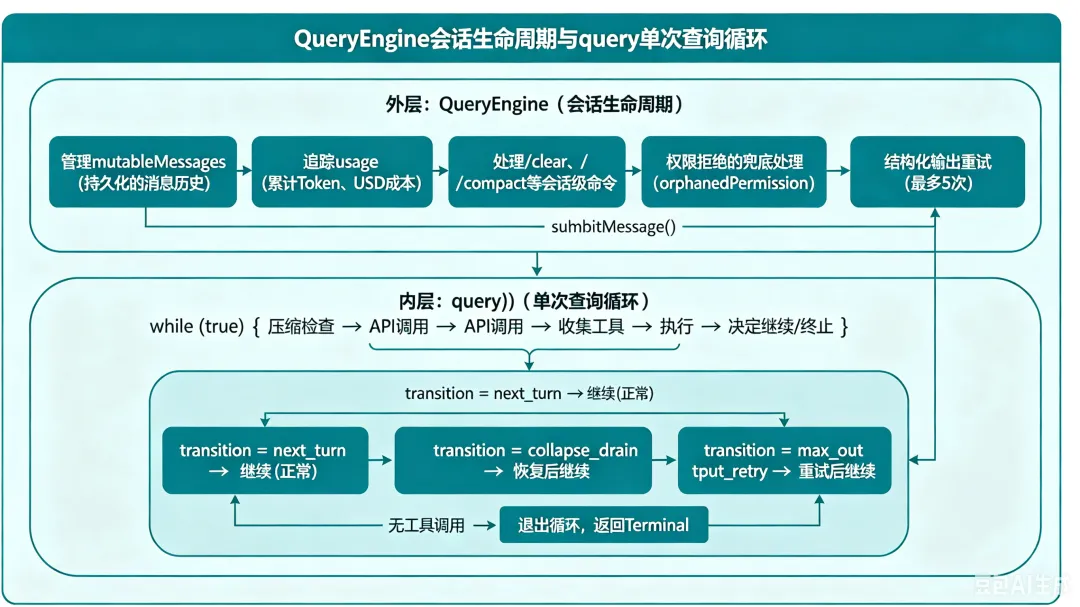
1.2 双层循环的价值
职责分离:QueryEngine vs query()
维度 | QueryEngine(外层) | query()(内层) |
生命周期 | 对话全生命周期 | 单次 API 调用周期 |
状态 | mutableMessages(持久化)、usage 累计 | State 对象,每次迭代整体赋值 |
关心的问题 | "用户说了什么、花了多少钱、这轮是否成功" | "消息需不需要压缩、API 返回了什么、工具执行成功吗" |
退出条件 | 用户主动结束会话 | 模型决定不调用任何工具 |
错误类型 | USD 超限、权限拒绝、孤儿权限 | PTL 错误、max_output_tokens、资源耗尽 |
范式洞察:把这两个职责混在同一个循环里,是大多数 Agent 框架犯的错误。Claude Code 的 insight 是:会话管理关心的是"对话整体",单轮执行关心的是"这一轮能不能做完"——它们的关注点不同、变化节奏不同、退出条件不同,强行合并只会让每一层都变得脆弱。
三个问题的对应解决
1.0 的问题 | 双层循环的解法 |
状态混淆 | 外层管会话状态(mutableMessages、usage),内层只管单轮执行(State 对象) |
预算失控 | 外层独立判断 USD 超限 → 提前终止;内层 PTL 在外层不知情的情况下自动恢复 |
恢复粒度粗 | 内层 7 条恢复路径处理各种错误;只有内层完全失败才通知外层 |
关键洞察:三个问题在单层循环里是交织的,在双层循环里是分治的。每层只关心自己的职责,恢复逻辑也在最近的一层完成。
工程价值:可测试性与防御性
以 PTL(Prompt-Too-Long)错误为例:
传统单层循环:PTL 错误 → 循环终止 → 告诉用户"上下文满了,请手动压缩"Claude Code 双层循环:PTL 错误在内层 query() 发生 ├─ Context Collapse 尝试排水(释放暂存的折叠) │ ├─ 成功 → 重试 → 用户无感知,继续 │ └─ 失败 → 触发 Reactive Compact(子 Agent 生成摘要) │ ├─ 成功 → 重试 → 用户无感知,继续 │ └─ 失败 → 才 yield 错误给外层 QueryEngine
关键区别:PTL 恢复在内层完成,不需要外层知道。外层 QueryEngine 只在乎"最终有没有成功",不在乎中间经历了多少次重试。这带来一个工程上的巨大好处:
- query() 可以独立测试:你可以用固定的 mock messages 测试 PTL 恢复逻辑,不需要启动完整会话
- QueryEngine 可以独立测试:你可以测试"跑了 100 轮后 USD 超限"的行为,不需要真实调用 API
范式洞察:分离的核心价值不是"让代码更好看",而是让每一层的失败范围可控。内层可以优雅地自我恢复的 error,不应该冒泡到外层。
1.3 错误处理范式:错误是信号,不是停止信号
内层:错误格式标准化
任何阶段的错误 → 转换为 tool_result(is_error: true) → 返回给模型自我纠正
传统 React Loop的错误处理:模型上下文被错误信息污染。
Claude Code 的错误处理:模型看到的是一条格式良好的 tool_result 消息,而不是被错误信息污染的上下文。
内层:七条恢复路径
错误不是循环的终点,而是分叉点。Claude Code 定义了 7 条明确的恢复路径:
# | 错误类型 | 恢复策略 | 示例 |
1 | 工具不存在 | 静默跳过,继续 |
|
2 | 权限拒绝 | 提示用户授权 | "Allow 0 tools?" |
3 | 工具执行失败 | 注入错误信息,重试或跳过 |
|
4 | 内容截断(Tool Result Budget) | 自动截断,附加 guidance | 大输出被截断并提示处理方式 |
5 | 上下文过长(PTL) | 触发压缩,继续 | History Snip / Microcompact |
6 | 连续拒绝(Denial Loop) | 注入引导提示 | "模型似乎拒绝了任务..." |
7 | MCP 连接失败 | 降级处理,不阻塞 | MCP 工具不可用时跳过 |
为什么是 7 条? 每条路径对应一种真实场景中常见的中断模式。不是 try-catch 的通用异常处理,而是针对每种错误类型量身定制的恢复策略。
Harness 思想的核心体现:
传统思维 | Harness 思维 |
关注"什么是错误"(负面清单) | 关注"如何继续"(正面清单) |
错误 = 结束信号 | 错误 = 分叉信号 |
模型遇到错误就停止 | 模型遇到错误就走恢复路径 |
传统 Agent 的设计是"错误 → 停止 → 等待人类处理"。Claude Code 的设计是"错误 → 7 条恢复路径之一 → 继续"。
这不是让模型更聪明,而是给模型一个"遇到任何情况都能继续"的执行框架。 再聪明的模型,如果没有继续信号,也会在第一个错误前卡住。好的 Harness 不消灭错误,而是确保错误永远不是终点。
2. 上下文工程:带着镣铐跳舞的缓存博弈
> 核心:每次 API 调用模型从零开始,Claude Code 必须将系统提示词、环境/项目上下文、消息历史三大支柱组装为完整请求。在有限上下文窗口和前缀缓存的双重约束下,通过精细化设计实现"给模型最好上下文"与"缓存效率"之间的动态平衡。
2.1 上下文构成
每次调用 Claude API,模型没有跨请求的持久记忆。Claude Code 必须在每次 API 调用前,将模型需要的所有信息组装成一个完整的请求。这个组装过程涉及三大组成部分:
1. messages:会话消息数组,包括用户的提问、模型的回答、工具调用和结果。这是变化最快、占用空间最大的部分。
2. tools:工具 schema 数组,告诉模型有哪些工具可用、每个工具的参数和约束。
3. 系统提示词(System Prompt):定义模型的身份、能力边界和行为规则。这是最稳定的部分,跨请求基本不变。
这三者加在一起决定了"模型看到什么",上下文工程的核心挑战就是:前两者(messages + tools)动态易破缓存,后者(系统提示词)稳定可缓存,必须在有限窗口内平衡给模型的上下文质量和前缀缓存的命中率。
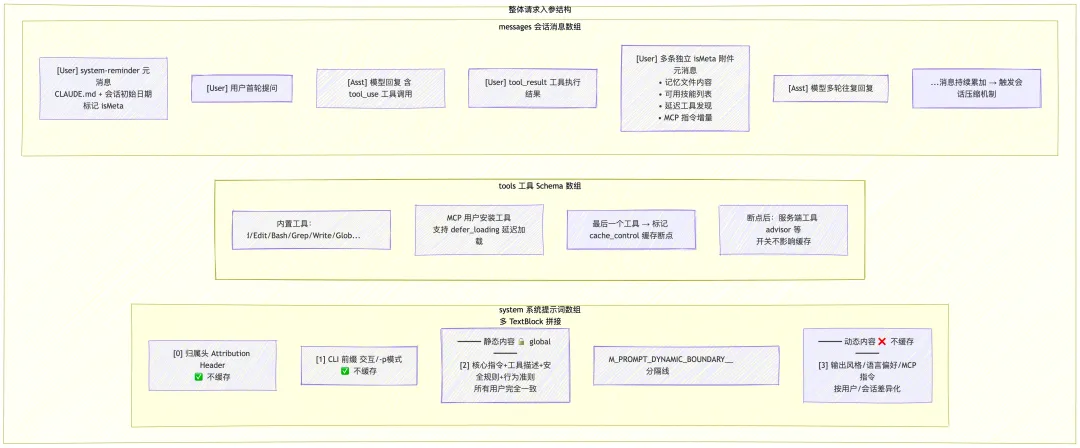
2.2 缓存最大化:哨兵边界 + 分区排序
KV Cache 的命中规则很残酷:前缀必须字节级完全一致。任何一个字节的变化都会导致整个前缀缓存失效。Claude Code 通过两个核心策略最大化缓存命中率:
策略一:系统提示词的静态/动态边界
用一个哨兵字符串 __SYSTEM_PROMPT_DYNAMIC_BOUNDARY__ 将 System Prompt 数组切成两半:
索引 | 内容 | 缓存策略 | 说明 |
[0] | 归属头 | 不缓存 | 每次请求不同 |
[1] | CLI 前缀 | 不缓存 | 每次请求不同 |
[2] | 核心指令 + 工具描述 + 安全规则 | global scope 缓存(全球共享) | 所有用户完全相同 |
[3] | 输出风格、语言偏好、MCP 指令等 | 不缓存 | 因用户/会话而异 |
边界之前用 `scope: 'global'` 全球共享缓存,边界之后不缓存。找出所有用户都共享的部分,放到缓存友好的位置。
策略二:工具定义的分区排序
API 缓存在最后一个内置工具之后设置断点。分区排序确保添加/移除 MCP 工具只影响后缀部分,内置工具前缀块的缓存始终命中。
范式洞察:System Prompt 和工具定义本质上面对同一个问题——"前缀中的哪部分是稳定的,哪部分会变?" 答案都是:把稳定的部分聚拢在一起成为前缀块,把变化的部分甩到后缀。缓存不是事后优化,它是从 System Prompt 组装到工具排序都被主动设计的资源。
2.3 五级渐进式压缩:成本从低到高,风险也逐级放大
每一级压缩,成本更高,风险也更大:
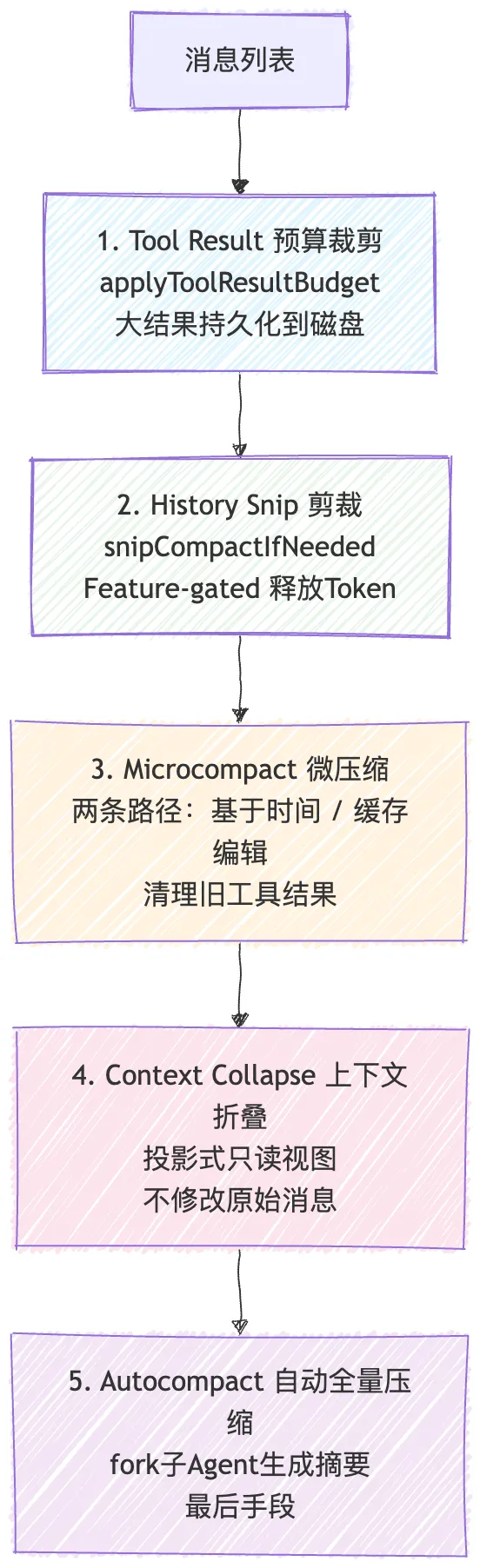
级别 | 触发方式 | API 成本 | 信息损失风险 | 可逆性 |
Tool Result Budget | 自动 | 零 | 极低(只是截断大结果) | 无损失,无需恢复 |
History Snip | 自动 | 零 | 低(移除未引用的旧工具结果) | 无损失 |
Microcompact | 自动 | 近零 | 低(压缩单条结果体积) | 无损失 |
Context Collapse | 自动 | 中等 | 中等(分组折叠,但原始历史保留) | 可逆,内存中保留完整历史 |
Autocompact | 自动 | 高 | 高(子 Agent 生成摘要,细节永久丢失) | 不可逆 |
范式洞察:
压缩的本质不是"选最优方案",而是在成本和风险之间找平衡。Claude Code 的策略是"先用便宜的低风险方案试,万一就够了呢"——但更重要的是,每一级都清晰地知道自己的风险边界在哪里。
其中 Context Collapse 的设计最值得关注:原始完整历史保留在内存中,发送给 API 的是折叠后的视图。 可逆性意味着你可以大胆压缩——如果压缩后模型行为异常,可以回退到完整历史。这种"写时分离"(写保留完整,读取折叠视图)是数据库领域 MVCC 在 Agent 上下文中的体现。Context Collapse 的可逆不是偶然的——因为它是"中等成本"级别,需要一道安全阀;而 Autocompact 作为最后的手段坦然接受不可逆,因为只有走到那一步才说明真的没有别的办法了。
作为最后防线,Autocompact 自身有两个精妙设计:
设计一:Chain-of-Thought Scratchpad。 子 Agent 生成摘要时,先让模型进行"链式思考"推理分析,再基于推理结果生成最终摘要。推理过程本身质量很高但如果保留在上下文中会浪费大量 Token,所以——丢弃分析、保留结论,两全其美。
设计二:压缩后恢复。 压缩意味着"失忆"——模型会丢失压缩之前的细节。因此压缩时主动为"必须记住"的信息(最近编辑的文件、当前技能上下文等)预留空间,压缩完成后立即将这部分关键信息重新注入,让模型迅速恢复"现场感",不因压缩而中断工作流。
3. 工具系统:统一接口 + 纵深防御
> 核心:通过统一 Tool 接口将所有工具纳入同一执行流水线,结合 Fail-Closed 默认值与多层安全防御,确保任何工具的错误都无法演变为系统级故障。
3.1 核心范式:Tool 接口 = 开闭原则的实体化
type Tool<Input, Output, P> = { // 契约方法 call(args, context, ...): Promise<ToolResult<Output>> description(input, options): Promise<string> // 安全语义编码为接口方法(不是外部配置) isReadOnly(input): boolean isConcurrencySafe(input): boolean isDestructive?(input): boolean checkPermissions(input, context): Promise<PermissionResult> // Schema 定义 inputSchema: Input // Zod}
范式洞察:新增工具只需实现 `Tool` 接口,无需修改执行流水线或权限系统。安全语义(`isReadOnly`、`isDestructive`)编码为接口方法而非外部配置——这确保安全属性与工具实现始终同步,不会出现"工具改了行为但安全配置忘了更新"的问题。这是开闭原则在 Agent 架构中的体现:对扩展开放,对修改关闭。
3.2 工具并发设计:流式工具预执行
串行执行: [======API 流式输出======][tool1][tool2][tool3]流式并行: [======API 流式输出======] [tool1] ← 利用流式窗口 (5-30s) [tool2] ← 覆盖 ~1s 工具延迟 [tool3] [==结果即时可用==]
范式洞察:模型流式输出需要 5-30 秒,但一个 tool_use block 可能在前几秒就已完整解析——为什么要等到最后?`StreamingToolExecutor` 在流式期间就分发已完成解析的工具调用。对用户来说,工具执行时间是"免费"的——它隐藏在模型生成的过程中。这是"隐藏延迟"设计模式。
3.3 错误是数据,不是异常
任何阶段发生的错误 → 转换为 tool_result (is_error: true) → 返回给模型 → 模型自我纠正
tool_result返回shell命令超长,模型自我纠错写入文档执行
{ "role": "tool", "tool_call_id": "call_8001d716787b46e283c737b8", "content": "[Error calling tool: command length exceed 1024 bytes, you need to split the command into smaller parts.]" }, { "role": "assistant", "content": "\n\n让我将内容写入文件后执行:\n\n", "tool_calls": [ { "id": "call_3f16311e17074f59a46b973c", "type": "function", "function": { "name": "write_to_file",
范式洞察:工具执行流水线中没有任何错误会导致进程崩溃或对话中断。Schema 验证失败、权限拒绝、运行时异常——全部被转换为 `tool_result` 消息返回给模型。Agent 系统中的错误处理哲学与 Web 服务完全不同:错误不是"需要人工介入的故障",而是"需要模型重新决策的信号"。
3.4 防御性编程护栏:把不该发生的事锁死
工具系统在多个维度上实施了防御性设计,不是"假设一切正常",而是"堵死所有可能的故障路径":
大结果三级截断——上下文不能失控:
限制层 | 阈值 | 作用 |
| 50,000 字符 | 单工具结果超限则持久化到磁盘,只返回文件路径 + 截断指示 |
| 100,000 token (~400KB) | 绝对上限,任何工具不能超过 |
| 200,000 字符 | 单轮所有工具结果的聚合上限 |
为什么需要三级?并发执行时 5 个工具各返回 50K 字符就是 250K——超过单消息限制。聚合上限确保即使并发,注入上下文的总数据量也不失控。模型只看到摘要和文件路径,按需通过 FileReadTool 主动拉取详细内容——"一次爆炸"转化为"可控增量"。
沙箱执行——让危险命令无路可走:
BashTool 支持沙箱隔离:macOS 用 sandbox-exec 配置文件,Linux 用 bubblewrap(bwrap)限制文件系统访问、网络和进程能力。排除命令列表允许管理员按需豁免特定命令。
> 实践心得:这类护栏思想在具体工具设计上也处处适用。长工具结果不直接塞回上下文而是写入文件按需读取、`replace_file` 前必须先 `read_file` 确认文件存在且没有并发修改、替换文件内容不依赖模型生成全文而是用文件索引或正则匹配精确操作——本质上都是同一个理念:用代码兜底防止假设崩塌。
范式洞察:防御性编程不仅是写安全的代码,更是把"不该发生的事"变成技术上不可能发生的事。大结果用三级截断锁死上限,危险命令用沙箱物理隔离,攻击向量用 23 道检查层层过滤。这不是祈求模型别犯错的信仰体系——是工程上的硬约束。
4. 记忆系统:记忆的生命周期管理
> 核心:遵循"互补性原则"——仅记忆代码无法自描述的信息(用户偏好、项目动态、外部定位),通过封闭分类法和验证机制确保记忆与现实不漂移。
4.1 只记忆不可推导的信息
> 核心约束:只记忆不可从当前项目状态推导的信息。
范式洞察:这不是为了省存储空间,而是防止记忆与现实漂移。如果记忆记录了"认证模块在 `src/auth/`",一次代码重构就会让这条记忆变成误导。代码模式、架构、Git 历史等信息是自描述的——从代码本身读取永远比从记忆中回忆更准确。互补性原则是记忆系统的第一性原理:记忆补代码之不可补。
4.2 封闭分类法
类型 | 记什么 | 示例 |
user | 用户身份、偏好、知识背景 | "数据科学家,专注可观测性" |
feedback | 行为纠正(成功+失败都记录) | "不要尾部总结" + WHY |
project | 项目进展、决策、截止日期 | "2026-03-05 合并冻结" |
reference | 外部系统的定位信息 | "Bug 追踪在 Linear INGEST 项目" |
范式洞察:为什么是封闭分类而非自由标签?封闭分类法强制 Agent 做出明确的语义分类,避免标签膨胀导致召回时的模糊匹配。每种类型有不同的保存结构和使用方式——这让模型在写入和读取时都有明确的行为指引。有约束的分类比无约束的自由更有助于系统行为的一致性。
4.3 类型深度分析
feedback 类型深度分析:不只记录失败
源码 memoryTypes.ts 中 feedback 类型的定义揭示了一个微妙的设计决策——feedback 不仅记录用户的纠正,还记录用户的肯定:
Guidance or correction the user has given you. These are a very importanttype of memory to read and write as they allow you to remain coherent andresponsive to the way you should approach work in the project.
为什么同时记录成功和失败?源码注释中有一段关键解释(意译):
如果你只保存纠正,你会避免过去的错误,但会偏离用户已经验证过的好方法,并可能变得过于谨慎。
这是一个深刻的观察。假设用户说"这次的代码风格很好,以后就这样写",如果不记录这个正面反馈,Agent 可能在下次会话中"改进"代码风格——结果反而偏离了用户满意的方向。
feedback 和 project 的结构化要求
这两种类型要求特定的正文结构:
Why: 用户给出这个反馈的原因——通常是一个过去的事故或强烈偏好。
How to apply: 什么时候/在哪里应用这条指导。
为什么需要 Why? 源码提示词中明确说明:"Knowing why lets you judge edge cases instead of blindly following the rule."
举个例子:如果记忆只记录"不要 mock 数据库",Agent 会在所有测试中避免 mock。但如果记忆还包含"Why: 上季度 mock 测试通过但生产环境迁移失败",Agent 就能判断——这条规则适用于集成测试,单元测试中的轻量级 mock 可能没问题。
project 类型:相对日期 → 绝对日期
project 类型有一个特殊要求:必须将相对日期转换为绝对日期。
当用户说"周四之后合并冻结",记忆必须存为"2026-03-05 后合并冻结"。原因很简单:记忆可能在几周后被另一次会话读取,此时"周四"已经毫无意义。
什么不该保存
记忆系统有一个明确的排除列表,来自源码中的 WHAT_NOT_TO_SAVE_SECTION:
- 代码模式、约定、架构、文件路径、项目结构——读当前代码即可获得- Git 历史、最近的改动、谁改了什么——git log / git blame 是权威来源- 调试方案或修复步骤——修复在代码里,上下文在 commit 消息中- 已经记录在 CLAUDE.md 中的内容- 临时任务细节:进行中的工作、临时状态、当前对话上下文
关键设计点:这些排除规则即使用户明确要求保存也生效。如果用户说"记住这个 PR 列表",Agent 应该引导用户思考"这个列表中有什么是不可推导的?是关于它的某个决策、某个意外发现,还是某个截止日期?"
4.4 索引而非容器
MEMORY.md(索引,每次会话完整加载,≤200行/25KB) ├─ user_role.md ├─ feedback_terse.md ├─ project_freeze.md └─ reference_linear.md
范式洞察:类比数据库——MEMORY.md 是索引,记忆文件是数据行。索引必须紧凑(每次会话都完整加载),实际内容按需读取。
4.5 语义召回
Sonnet 侧查询而非关键词匹配
用户查询 + 记忆清单(frontmatter description + ISO时间戳) → sideQuery(Sonnet) → 最多选 5 个最相关记忆 → 注入对话
为什么用 Sonnet 而非关键词匹配? "部署流程"的查询可能关联标题为"CI/CD 注意事项"的记忆——关键词匹配会错过,但语义理解不会。
recentTools 参数:精确的噪声过滤。 当 Claude Code 正在使用某个工具时:
- 该工具的参考文档型记忆是噪声——对话中已经包含了使用方法
- 但关于该工具的警告和已知问题仍然有价值
提示词中明确区分:"do not select usage reference docs for those tools. DO still select warnings, gotchas, or known issues about those tools."
alreadySurfaced 预过滤:在调用 Sonnet 之前就过滤掉已展示的记忆路径。这不是为了避免重复展示——而是为了不浪费 5 个召回槽位。如果不预过滤,Sonnet 可能选中 3 个已展示的记忆,只留下 2 个新记忆的空间。
4.6新鲜度防御:验证而非盲信
"记忆说 X 存在" ≠ "X 现在存在"
三条访问规则:
已知记忆与任务相关时 → 主动查阅
2. 用户明确要求时 → 必须访问
用户说"忽略记忆"时 → 视为不存在
范式洞察:
1.eval 数据证实——"验证而非盲信"规则让通过率从 0/2 提升到 3/3。
2.可读的时间距离("47 days ago"而非 ISO 时间戳)让模型更好地判断记忆新鲜度。
3.Agent 的记忆系统需要防御的不是遗忘,而是"过时的确信"。
5. 技能系统:AI 任务的脚本化
> 核心:通过将验证有效的提示词模板化并支持模型自动触发,实现 AI 工作流的自动化复用,让用户只需表达意图而非记忆命令。
5.1 核心问题:重复的 AI 工作流
对比传统 AI Workflow 核心优势
优势 | 说明 |
动态触发机制 | 由 LLM 根据语义意图自动判断并调用,无需预设僵化的线性流程,灵活应对复杂场景。 |
模块化与复用 | 将专业能力封装为独立单元,像搭积木一样跨任务、跨项目复用,大幅降低重复开发成本。 |
生态系统拓展性强 | 支持社区共享与第三方集成,能力边界可无限扩展,轻松汇聚全球开发者的智慧。 |
热加载 | 多数 Skills 仅由 Prompt 构成,修改即生效,无需重新编译或重启服务,迭代极其敏捷。 |
渐进式披露 | 核心指令与扩展资源分层加载,仅在需要时读取细节,极大节省上下文窗口与 Token 消耗。 |
执行标准统一 | 内置统一的判断标准与 SOP,减少 AI 的主观偏差,确保同类任务输出结果的高度一致性。 |
极低参与门槛 | 自然语言可读,非技术人员也能通过自然语言编写 Markdown 文件来创建 Skill,极大降低了 AI 能力封装的门槛。 |
5.2 技能系统架构
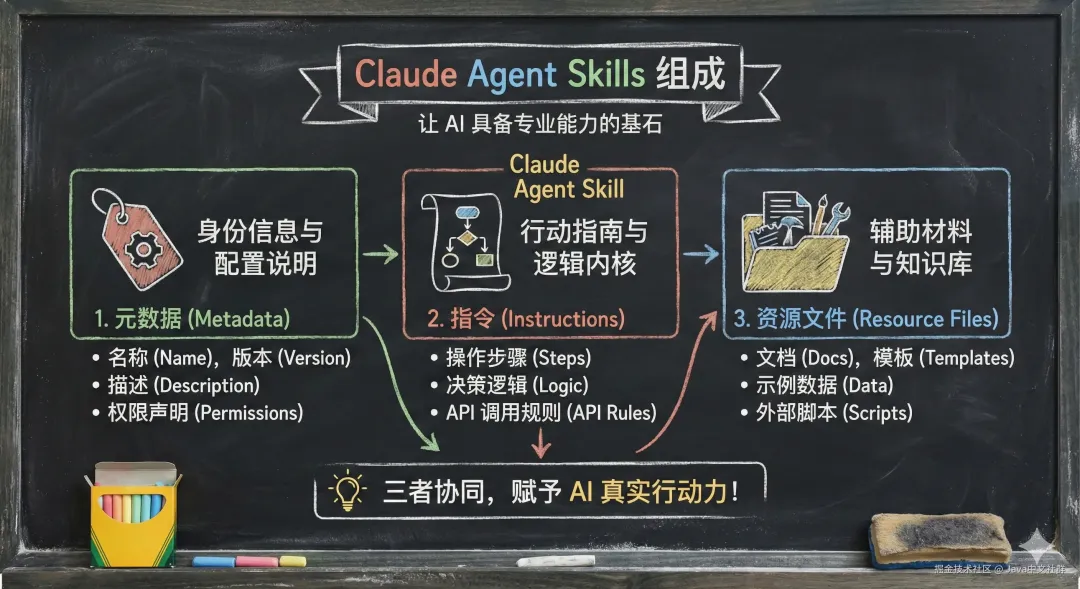
元数据 (Metadata): 包含对这个技能的简短描述。它保存在全局上下文中,因为体积小,所以非常节省 Tokens(省钱又省心)。
行动指南 (Action Guide): 这部分才是真正的提示词,规定了 AI 每一步该怎么做。
资源文件 (Resources): 这是最厉害的地方!它可能包含 Python 代码 或其他执行程序,保证程序在调用 Skill 时能完成复杂的动作。
实际目录结构
技能 = Markdown 文件(frontmatter + 提示词模板) ├── frontmatter:name / description / when-to-use / allowed-tools / context └── 提示词内容:$ARGUMENTS 占位符 / !`shell` 内联命令 / ${ENV_VAR} 环境变量
5.3 双重调用:手动 + 自动
Claude Code 的技能有两条调用路径,这才是技能系统的关键创新:
调用方式 | 触发者 | 示例 |
用户手动 | 用户输入 | 用户明确需要某个流程 |
模型自动 | 模型判断当前任务需要调用技能 | 用户说"帮我提交代码",模型识别意图后自动触发 |
为什么双重调用是好设计? 传统 slash command 只能手动触发——用户必须知道命令名、记住语法。双重调用让技能成为 Agent 行为的一部分:用户不需要记住命令名,只需要表达意图,模型自己会选择合适的技能。
whenToUse 字段是自动触发的关键:
when-to-use: 当用户修改了多个文件并想在提交前检查代码质量
好的 whenToUse 应该:
- 描述用户意图,而非用户的措辞:"当用户需要审查代码质量时" 好于 "当用户说 review 时"
- 包含否定条件:帮助模型区分相似场景,减少误触发
- 具体而非笼统:模糊的描述几乎匹配所有场景,导致频繁误触发
5.4 懒加载:发现与执行分离
技能内容不在启动时加载。 系统只预加载 frontmatter(name、description、whenToUse),完整的 Markdown 提示词内容在用户实际调用时才读取。
为什么懒加载?
一个技能可能有几百行提示词,几十个加起来严重挤占上下文空间
大部分技能在当前会话中不会被使用
全量加载增加启动延迟,影响首次响应速度
范式洞察:这是展示成本低、执行成本按需付的模式。让模型知道"有哪些技能可用"只需要几十字节的 frontmatter,不需要把完整的提示词模板全部塞进上下文。发现和执行是两种不同成本的操作,应该分离处理。
6. 贯穿全局的元范式
> 核心:构建企业级 Agent 的关键不是让模型更聪明,而是设计一套"模型无法搞砸"的 Harness——通过防御性设计、缓存优先、错误恢复路径等机制,确保系统在各种异常情况下都能继续运行。
总结:五个模块的设计哲学
模块 | 核心哲学 | 关键范式 |
Agent Loop | 流式管道 + 状态机 | AsyncGenerator 全链路、双层分离、错误扣留 |
上下文工程 | 缓存最大化 | 静态/动态边界、分区排序、渐进式压缩 |
工具系统 | 统一接口 + 纵深防御 | Fail-closed、三层组装、流式预执行、三级截断、沙箱、23 道安检 |
技能系统 | AI 任务的脚本化 | 双重调用、懒加载、静态模板 + 动态组装、Fork 隔离 |
记忆系统 | 不可推导优先 | 互补性原则、封闭分类法、验证而非盲信 |
一句话总结:从"迷信模型"到"设计缰绳"。
构建企业级、高可用 Agent 的核心方法:再聪明的模型,如果没有一套严密的缰绳(Harness)去约束和引导,在复杂的真实环境中也一定会搞砸。 Claude Code 的架构正是这套缰绳的实现——不是让模型更聪明,而是设计一个模型无法搞砸的执行环境。
