 夜雨聆风
夜雨聆风检测器所关心的是"这个句子的统计特征是否和人工智能一样",而不是"是谁写的"。整个赛道已经销售了三年,但是它所回答的问题本身是错的。

到了2024年,有一种人工智能检测系统可以对朱自清先生于1927年写的散文《荷塘月色》进行检查。
得出的结果是62%,由AI生成。
机器没有出现问题。它只做它被设计成要做的工作,那就是对词频分布、句式结构、语义流畅度进行分析,判定该段文字是否在它所认定的"AI区间"内。朱自清的文字非常清晰,而且很匀称,结构也十分工整。这也正是GPT所擅长的输出方式。
所以:62%。
这件事我觉得很重要,并不是因为荒唐,而是因为很准确。把生意中最关键的问题以死者的名字说出来就是:
检测器从来都不用来看出是谁写的,而只需要看这句话的统计分布是不是像AI写的一样。
这两者是不一样的问题。三年来,整个赛道都把前者答案当成了后者的解答,并且用这个答案去售卖给了上百万所学校。
一、这个生意是如何走到今天这个地步的
2019年:造枪的人先说死掉的话

2019年2月,OpenAI发布了GPT-2,但是没有全部开放。
一个谨慎的安全声明:由于该模型可以生成非常逼真的文本,因此目前只提供给研究人员使用。在AI公司中,这是很少见的自我约束。
但是很少有人会提到同年八月份发布的跟踪报告。这篇文章的名字是《GPT-2:六个月之后》,其中有这样一句话很少有人引用:
Statistical detection of text needs to be supplemented with human judgment and metadata.
用统计的方法去检测AI生成的文字,还要配合上人工审核以及元数据等手段,单凭机器是行不通的。
说出这句话的是OpenAI本身。
最早提出"检测很难"的不是之后批判检测器的学者,也不是被错判的学生,而是正在制作生成模型的那家公司的人员。早在2019年的时候他们就把这句话写进了文档,并且把它挂在了官网上面。
没有人会去认真看这句话。
同年,MIT-IBM Watson AI Lab发布了GLTR,这是最早出现的可视化检测工具。它与之后出现的"给用户显示一个AI比例"的产品逻辑不一样。GLTR并没有为你做决定,只是给你看:这个句子当中每一个词被模型预测出来的概率是多少。
起的作用只是扩大,并不是当做重锤来使用的。
这个差异,之后整个行业都忘记了。
我认为这部剧里最真诚的部分就是2019年。造枪的人说盾很难做,做工具的人只做放大镜不做法官。从2022年11月之后就没有再出现过。
在2020-2022年10月期间,检测差不多已经被学术界放弃了。GPT-3来了、Codex来了、DALL-E来了,没有专门做「AI文字检测」的,因为没有这个需求。
过去三年并非没有发生这事,只是到了时间还没有到期而已。
ChatGPT发布之后的第62天,就有数百万名教师提出了同一个问题

2022年11月30日开始ChatGPT公测。
学校很紧张。并不是因为有足够的证据证明学生在使用它,而仅仅是因为任何一个人打开浏览器就可以使用它——这样的可能性本身就已经使老师对每一项作业都产生了怀疑。
需求并不是逐渐产生的。一夕之间就由零变成了「紧急」。
Edward Tian当时正在多伦多过寒假。他有着普林斯顿NLP实验室的研究经历,也曾担任过BBC调查记者。他在一家咖啡馆里,经过几天的时间就做出来了GPTZero,并于2023年1月2日上线。
有名。
理由并不复杂,就是回答了数百万个老师一起提出的这个问题:这篇作业是不是ChatGPT写的?答案是"可能可以",但是在恐慌的状态下,"可能可以"听起来就是"可以"。
1月31日,OpenAI站出来表态了。他们推出了自己的AI文本分类器。但是公告中的一个句子压在文件的后面一些的地方:
It is impossible to reliably detect all AI-written text.
一家公司发布一个产品的时候,在同一个文件里面写着这个产品不能做到的事情。
不是因为他们做错了什么——而是他们很清楚这件事情的边界是什么,但是仍然发了出来。
市场的声音太大,什么都不做的政治代价太高,所以他们给出的答案虽然知道不理想,但是仍然把"不够格"三个字写在下面。但是没有人去看那三个字。
在这62天中,大家关心的是有没有,没有时间去想是否足够。
速度与科学在这里第一次分道扬镳,并且分得非常干净利落。之后发生的事情都是由于这次分叉所引起的。
产品上线还不足三个月的时候,学术界就把底座拆了
2023年3月17日,马里兰大学的研究人员发布了预印本论文。
标题是个问句:《Can AI-Generated Text be Reliably Detected?》
答案不能用疑问句来回答。答案是:不可以。
主要结论就是,只要稍微对AI生成的文本进行一些简单的修改,现有的检测工具就会失效。不需要很高的技术,也不需要特殊的器械,改一下就行了。
两周之后,Stanford的研究小组又发布了一篇文章。也是一篇很让人心惊动魄的文章。
它并不是说检测器不准确,而是说检测器的错误是有方向性的:对于非母语英语写作的人,系统的误判率更高。James Zou认为:
Current detectors are clearly unreliable and easily gamed.
随机出错的工具就是不好的工具。对某一类人犯错误的工具就是有偏见的工具。
国际学生、英语非母语学者的写作方式本身就比较规范,而且会大量使用固定的句式结构,这就与检测器所认定的「AI风格」不谋而合。检测器实际上是在惩罚一种写作的习惯,并不是在检测写作的来源。
坏秤最糟糕的一点是,它是单向坏的。
7月20日,OpenAI悄悄在它的发布页面上加了一行字:
The AI classifier is no longer available due to its low rate of accuracy.
上线时间是1月31日,下线时间是7月20日。不满六个月。
Vanderbilt随后也宣布停用Turnitin的AI检测功能,并且用了「for the foreseeable future」这个措辞,即"可预见的未来"。
但是Turnitin并没有被下线。
造模型的人走了,卖工具给学校的留了下来。这是整个故事情节中最主要的一个分支。
科学结论已经出来了,但是市场的走向正好相反

2023年10月11日,美国教师联合会AFT和GPTZero进行合作。AFT有170万名会员。
这背书的时间很不正常。离UMD、Stanford研究揭穿的时日也仅有五个月左右。
在2024年6月完成了1000万美元的A轮融资后,GPTZero总计已经融资了1350万美元。
我一直有个疑问就是,这些学校和机构都不看论文吗?Stanford HAI得出的结论在官方网站上非常明确。
后来我觉得他们应该读了,但是需求不同。
买的是准确率之外的东西。他们买的是一个可以拿出来的程序。
当一个院系主任在面对家长、面对申诉、面对上级的时候,说「我们用的是行业标准的工具来查证」要比说「我们凭直觉判断」在制度上安全很多。
坏秤的价值并不在于它本身能够准确称重,而是在于它可以让人觉得整个交易过程是有依据的。
但是程序的代价是由具体的个人来承受的。
在Reddit上有一个老师的账号这样写到:
Turns out all three were false positives… One of them cried in my office.
三个学生都判断错了,其中有一个还在老师的办公室里哭了起来。
有人做过一个非常直观的计算:如果有1000名学生,按照1%的误判率来算的话,就有60个假阳性。要么是几率,要么就是人。
Turnitin的官方说法一直都没有改变过:误判率为小于1%,并且我们不做学术不端行为最后的定论。从数学上讲可以成立,但是具体到现实中又会怎样呢?哭着的学生能给出答案。
到2026年,所有人都会说:我们现在换个问题来回答

2026年5月,OpenAI发布了一条公告,标题为《Advancing Content Provenance》。
主要的不是检测,而是追根溯源:Content Credentials、SynthID、公开验证门户。公告中有一句被放得很不显眼的是:
No single provenance technique is enough on its own.
从"检测困难"到现在的这句话中间相隔了七年的时间。
意思是相同的。
行业的做法就是把同样的一个认可,用一套新的词汇来重新包装一下。
Google SynthID、Grammarly Authorship、Turnitin Clarity、AP Verify等口径一致,时间段集中。这几家公司的思路并不是同时想出来的。这是整个行业用产品迭代的方式在说一句话:上一条路已经走不通了。
没有谁公开发表意见说「我们做错了」。但是做了动作。
溯源路线的逻辑要比分类路线严谨很多。水印被嵌入到生成的过程中,并不需要事后去推测文字的风格。就技术层面而言,这要比"看这段话的token分布是否符合AI"的方式更加靠谱一些。
但是它存在一个基本的问题,很少有人直接提到:
溯本求源的办法只能以后才生效。
从2022年11月到现在,这三年半以来所生成的所有AI的内容都没有水印、没有Credentials,也无法被溯源系统所查证。该部分内容已经上传到了互联网上、作业库中、论文数据库里。
溯本求源路线图所展示出的未来是干净的、舍弃掉以往混乱的历史。
过去的这批内容真实性的问题将会一直存在。
二、把场上的五个玩家放在一起看,没有一个护城河是由于把问题解决得更好而产生的

GPTZero:获得了品类的同时,也将品类所带来的一切问题都揽到了自己身上
Edward Tian得到的第一件东西不是用户,而是品类定义权。
GPTZero成为"AI检测器"这个词在人们心里的第一个具象化的东西。这是商业上的一个大优势,但是在该领域里就变成了双刃剑。
当一个品牌就代表了一个品类的时候,品类所面临的所有问题也就变成了品牌所要面对的问题。之后每次出现误判的情况,GPTZero都会被最先提及,并不是因为它误判次数多,而是因为它的名字最响亮。
2024年9月,GPTZero发布了作者身份工具:写作回放、粘贴记录、写作报告。官方没有说"检测不够用",但是该产品的举动已经说明了。它把问题由"这段话是人工智能写的吗?"改为"这段话的创作过程是怎样的"。
这可能是GPTZero做出的最聪明的一次转身,也是它最难公开承认的一次转身。因为它整个品牌的立足点就是"我可以检测AI"。
Turnitin的护城河是1998年,而不是算法
Turnitin创建于1998年。
它在2023年进行人工智能检测之前,在高校系统内已经存在25年了。时间差就是它的主要的竞争优势,比所有的算法都要强。
从2023年4月份开始,Turnitin就开启了AI写作检测的功能。学校不需要再对供应商进行审核,也不需要启动新一轮的采购程序。管理员登录进去,勾选一个选项,AI检测就可以开启了。
GPTZero要得到用户的青睐,Originality.ai要获得客户的认可,Turnitin只要不让现有的客户流失就可以了。三者之间难易程度相差很大。
Turnitin官方的说辞是两句话,这两句话一直并存:「误判率小于1%」和「Turnitin不做最终的学术不端判断」。
这两句话合在一起就是一道责任划分得十分仔细的界限。第一句话就为机构提供了一个数据依据。第二句话从法律的角度把所有的责任都归咎于机构。
Turnitin售卖的是一个比例,而用这个比例去和学生交谈的人是教师以及学院,出现任何问题都是他们自己做出的选择,并不是由Turnitin来判定的。
从2026年1月开始,Curtin大学将不再使用Turnitin的AI检测功能了。这不是Turnitin的问题,而是整个"事后检查文字"的系统出现了问题。
Originality.ai:找到了正确的敌人,但是要到一个完全不同代价的战场上去了
Jon Gillham创建Originality.ai最初的目的不是"如何检测学生的作弊行为",而是"我如何判断外包来的文章是不是由AI修改过的"。
由于出发点不同,所以这家公司的性质与其它公司有本质的区别。
教育场景中的焦虑就是道德焦虑,即学生是否欺骗了老师?内容营销场景中的焦虑就是商业焦虑,客户会不会用AI骗我?前一种情况要的是权威性,后一种情况要的是准确性。Originality.ai自始至终都在回答第二个问题。
Springer的研究给出的一组数据是:Originality.ai的整体准确率为0.69,Turnitin为0.61。这个差距是存在的。
但是到2026年1月的时候,Originality.ai推出了学术模型Academic Model,并且开始往学校场景中转移。
内容代理商买了这个,错误判断的代价就是"再查一遍稿子"。学校使用它时,错误判断的后果就是一个学生要被叫到处分委员会去。把为商业信任设计的工具带入一个后果相差很远的战场。
Copyleaks:看到了结局,但是目前的产品却在给结局投反对票
Copyleaks成立于2015年,比当前的热潮早了八年。它一开始就不是把自身当做"AI检测工具",而是作为"内容真实性平台"来使用的,包括抄袭、AI文本、版权合规等。
到2026年5月为止,Copyleaks会为消费者推出一款新的AI图像检测器。文字是起点,图片紧接着就出现了,视频也就不远了。押注的是「内容的真实性」本身就会成为基础设施——不是选择不使用的技术手段,而是一个个平台迟早都必须具备的能力。
若赌注能够实现的话,Copyleaks的布局将会比所有仅仅进行文本检测的服务都要领先。
但是有一个用户的评论说得很清楚:
I had one come back at 0% and another at 100% in the last week.
同样的文件,在一周之内被扫描了两次,一次是0%,另一次是100%。
一个不很准确的工具,用户还可以用来作参考。不稳定的工具连参考价值都消失了。
Copyleaks在这几个玩家中战略方向是最正确的,而且现在的产品和战略之间的差距也最大。
Grammarly Authorship:宣称「我们不是检测器」之后就把大家绕过去了
Grammarly Authorship产品页面中有一句在该领域里比较特殊的话:
Authorship isn't a form of AI detection.
当别的公司都在争先恐后地声称自己的检测器最准确的时候,这家公司却站出来宣布,我们并不是做检测的。并不是谦虚,而是对自己做了准确的定位、适当的划分。
把问题由"这段话是人工写的还是机器写的"改为了"这段话是如何被写出来的"。前者是已经证明很难回答的问题。后者是可以被直接记录的过程。
它可以完成这样的事情,其他玩家没有的一个先决条件就是:它本身就在写作现场。Grammarly的编辑器里有数以百万计的用户在用它来写作。它不用等到一篇文章写完了再去猜作者是谁,在写作进行的时候它就参与其中了。
到2025年5月可以扩展到Microsoft Word,9月份进入Canvas LMS,在2026年3月可以区分具体的AI工具并进行归因。此路正在快速地建设当中。
但是有一个用户对这个产品的评价把实际情况说得很清楚:
But I am cautiously optimistic. This may be too good to be true.
小心谨慎,但是持有积极的态度。好的太不真实了。
Authorship只能够记录Grammarly编辑器中发生的写作行为。想要避开它的话,方法也很简单,换一个地方写作就可以了。
写作一定要在可以看见的地方进行。这个前提是否能够成立,就看有多少场景会把写作交由它来监督了。
三、只有把前两部分合在一起看才能看得出来
三个护城河并排在一起,没有一个属于技术护城河
把五个玩家的优势来源并排放在一起来看:
Turnitin依靠的是从1998年开始签订的采购合同。GPTZero是利用了2023年1月的一个完美的叙事契机。Grammarly Authorship依靠的是从始至终都没有参与到此次比赛当中去。Originality.ai服务的是一个不同的市场。
没有哪一个优势来自于"把文本分类做更准确"这样的事情。从一开始,这条赛道的竞争壁垒就没有建立在核心技术的问题得到解决的基础上。
一个亟待解决的问题,与这个问题能够被解决,并非是同一回事。
恐慌市场的胜利带来的一种优势,以及一个对称的弱点捆绑在一起
靠情绪叙事获得品类优势的,在误判丑闻中也将收件人的名字也登记在了自己的名下。当GPTZero获得"AI检测"这个词语的时候,也就成了每一次假阳性事件最容易被指责的罪魁祸首。
以免责声明来推脱责任的,在机构开始追究责任的时候会最先受到追究。Turnitin把判责的权利留给使用者单位,但是使用者单位却越来越发觉:用一个声称「不负责任」的工具来处分学生,在法律申诉以及道德舆论中越来越难以立足。
通过拒绝参加比赛来获得的护城河,也是三种方式当中最稳定的。Grammarly Authorship从不声称可以"辨别AI",所以它不会因为被说错而丢脸。
在这条赛道上有一个反常识的生存法则:最有力的防守姿态就是从一开始就不说你能解决根本的问题。
朱自清得了62分,并不是由于机器出错
人们把《荷塘月色》被打到62%的事情看作是"工具出bug"或者是"需要更好的训练数据"。
我认为这种读法是不正确的。
探测器没有出现问题。它做的是它被设计成要做的工作,即寻找统计规律,并判定该段落的词频分布是否处于"人工智能区间"。朱自清的文字清晰、匀称、结构工整,这是GPT最擅长模仿的一种风格。检测器得到62%的原因是根据统计学上存在重叠。
问题不在于校准,而是在于这件事从理论上来说是不可能做到的。
好的人类写作和好的AI写作在高质量区间的分布非常重合。随着人工智能生成的质量不断提高,两个分布的重叠区域也会越来越大。任何想用统计的方法将两者区分开来的工具都会碰到一道硬天花板:
你想把好的人类写作与好的AI写作区分开来,但是这两种写作风格本身就应该是相似的。
Stanford在2023年表示检测器会对非母语英语作者产生系统性的偏差,其背后的机制就是一样的:规整、正式、符合学术规范的非母语写作,在统计上更加接近于AI生成的结果。
这并不是通过更多的训练数据就可以解决的偏差,而是方法论本身存在的结构上的问题。
溯源路线提出一个干净的未来的同时也抛弃了混乱的过去
溯源方案只对将来的内容起作用。从2022年11月到现在,这三年半以来所有的AI生成的内容都没有水印、没有认证信息,在溯源系统中都会被显示为空白。
更深层次的问题是,水印只有在全行业都采用的情况下才有意义。目前世界上有多少个开源模型、微调模型、私有部署模型在运行呢?该类模型的输出,在任何溯源系统中都是静默的。
溯源路线解决了一个较小的问题,即可以证明"该段落出自已知的AI系统"。但是它不能解决"该段落的内容来源于未知或者不合作的人工智能系统"的问题。后一种情况正是真正的威胁当中最危险的一种。
接下来可能发生的事情中,最有可能发生的就是最无趣的那件
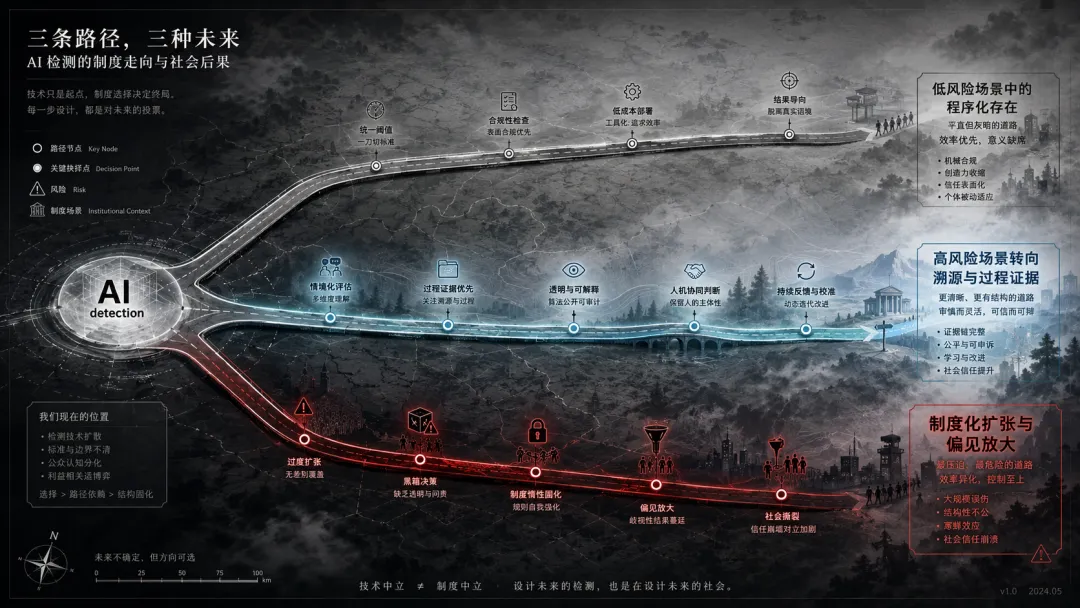
最可能发生的情况是:文本分类器在低风险场景中生存下去,并且成为机构中的"程序性存在",不是因为它准,而是因为它便宜、已经安装好了、可以让管理者说出"我们已经检查过了"。高风险场景(学术处分、法律诉讼、新闻核查等)将会逐渐迁移到过程证据和追溯系统当中。两套逻辑并行不悖地存在着,市场依然模棱两可地运行着,直到下一个比较大的错误判断事件出现才使某家机构做出正式转变。
最危险的是:政府和学校迫于必须对AI作弊采取措施的社会舆论,在此压力之下把文本分类器纳入更为正式的制度程序中来决定入学资格、奖学金评定、职业晋升等事宜。Stanford研究中所提到的偏见会在上述场景中被放大,而受害者主要是已经处于弱势地位的人群,如国际学生、非母语写作人等。最应引起重视的并不是教室里对作业评判的标准,而是一套这样的逻辑蔓延到不可挽回的情形,移民申请材料审查、专业资格认证论文审核等。在这样的情况下,假阳性的结果不是"被叫到办公室",而是申请被拒绝或者资格取消。
最乐观的情况是某一个法院或者某一个监管部门做出裁决,即认为概率分数不能作为处罚的充分理由,只有可以验证的溯源证据才有效。如果这个裁决真的出现了的话,那么文本分类器在高危场景中所占的地位将会在很短的时间内就烟消云散了。技术已经有了,缺少的是一个明确定义标准的判决。
三个剧本当中,最有可能出现的情况,也就是最无趣的一种:两种工具同时使用,高危场景逐步转移,低危场景依旧用坏秤。
朱自清没有等到那天。但是下一个被机器告上法庭的人,恐怕也不会是最后一个。
