 夜雨聆风
夜雨聆风systematic-debugging逼AI先找根因再修bug,verification-before-completion要求AI跑完命令才能说"搞定了"。两个Skill配合,从"猜-改-猜-改"变成"定位-修复-验证"三步闭环
写在前面
你用AI修bug,大概率是这样的:
报了个错,把错误信息贴给AI,AI说"试试改这个",改了,还是报错。再贴,AI说"那试试改那个",改了,新错误出现了。来回几轮,bug没修好,倒是多出来3个新bug。
这不是AI能力不行,是AI缺少调试纪律。
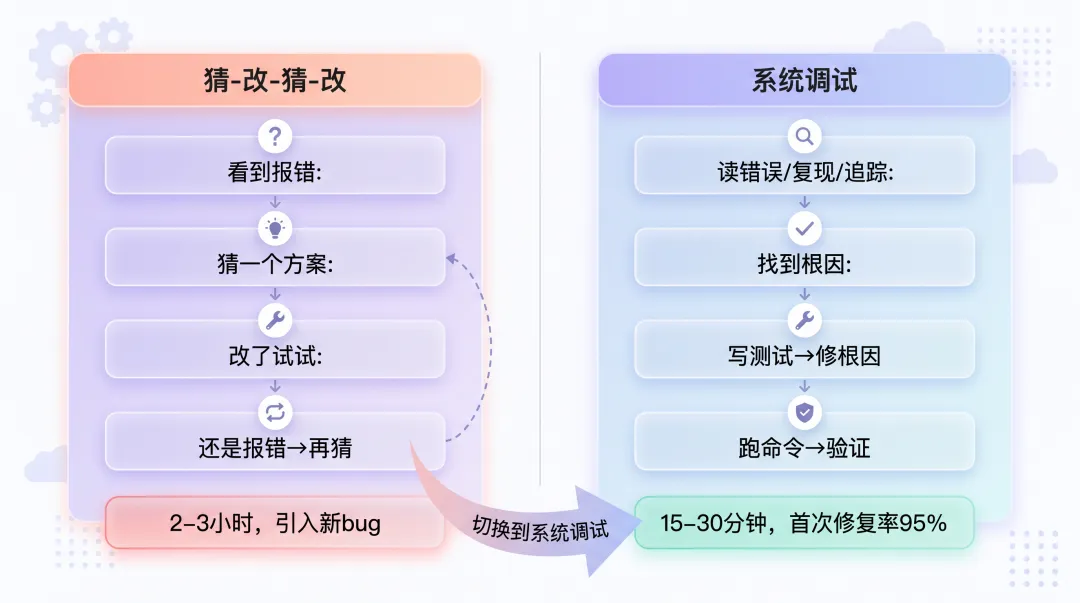
没有纪律的调试就是猜。猜一次两次可能蒙对,但猜的效率远低于系统排查——根据实际使用经验:系统调试15-30分钟搞定的问题,猜-改-猜-改要2-3小时;首次修复率从40%提升到95%;系统调试引入新bug的概率接近零,猜-改-猜-改引入新bug是常事。
这篇文章讲Superpowers的调试体系:systematic-debugging(系统调试)和verification-before-completion(完成前验证)怎么配合,把"AI猜bug"变成"AI定位bug→修bug→验证修复"的闭环。我会用两个真实场景走一遍完整流程,每一步的输入输出都写出来。
一、为什么AI修bug容易越修越烂
AI修bug有3个天生的坏习惯:
1. 猜着改,不找根因
你贴了一行报错,AI直接给方案。它没有先读完整的错误信息、没有复现、没有追踪数据流,就是看到报错关键词就给修改建议。
结果:修了症状,根因还在。换个场景,同一个bug换个方式冒出来。
2. 一次改多个地方
AI觉得"既然在改,顺便把这几个相关的也优化一下"。一次改3个地方,有一个改对了,另外两个引入了新bug。但你不知道哪个改对了、哪个改错了,因为改了太多。
结果:旧bug没修好,新bug来了。
3. 没验证就宣布修好了
AI改完代码,说"应该没问题了"。"应该"两个字是关键——它没跑测试,没确认报错消失,只是觉得代码逻辑上没问题。
结果:你部署上去,发现bug还在。
Superpowers的systematic-debugging和verification-before-completion两个Skill就是针对这3个坏习惯的。三条铁律:
二、systematic-debugging:4个阶段,不能跳步
systematic-debugging把调试拆成4个阶段,每个阶段必须完成后才能进入下一个:
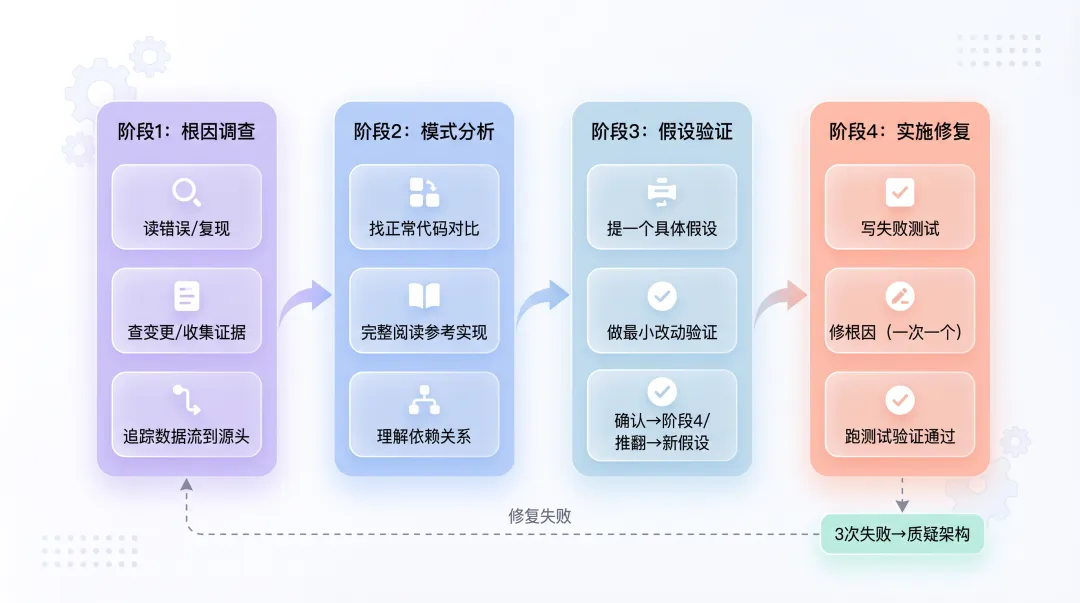
注意阶段3和阶段4的区别:阶段3是验证假设(改了看效果),阶段4是正式修复(写测试、改代码、跑验证)。
阶段3验证后有两条路:
还有一条原则很多人忽略:不知道就承认。Skill原文明确说"Say 'I don't understand X'"——不确定的时候,去问人、去研究,不要假装知道然后瞎猜。
什么时候最该用systematic-debugging?
不是闲的时候,是最急的时候。Skill原文写得很明确:"Use this ESPECIALLY when under time pressure."(在时间压力下尤其要使用这个Skill。)
紧急的时候,猜的诱惑最大。但猜的代价也最大——猜一次5分钟,猜错一次5分钟加回滚10分钟,3次猜错就1小时了。系统排查15-30分钟搞定,省下来的时间远超"先试试"省下的时间。
三、调试流程速查
在进入实战之前,先给一个完整的流程概览,方便后续对照:
发现bug时:
声称修好时:
修复失败时:
找不到根因时:
系统性调查后确实可能遇到环境因素、时序依赖或外部原因导致的bug。此时应该:记录调查过程、实现防御性处理(如重试机制、超时兜底、友好的错误提示)、加监控日志以备后续排查。但要注意:绝大多数"找不到根因"其实是调查不充分。
四、实战1:报错位置和根因很近
场景:React + TypeScript项目,用户反馈"提交表单后页面白屏"。
阶段1:根因调查
1.1 完整读错误信息
AI的第一反应不是给方案,而是先读错误:
TypeError: Cannot read properties ofundefined (reading 'map') at OrderList (src/components/OrderList.tsx:23:18) at renderWithHooks (react-dom.js:16175:18) at mountIndeterminateComponent (react-dom.js:20919:18)错误在 OrderList.tsx 第23行,对 undefined 调用了 .map()。这说明某个数组变量是 undefined,不是空数组。
1.2 稳定复现
AI尝试复现:
复现条件确认:只有提交新订单后才会白屏,刷新后恢复。
1.3 检查最近变更
git diff HEAD~3 -- src/components/OrderList.tsx发现最近一次提交把订单接口的返回类型从 Order[] 改成了 { orders: Order[]; total: number },但 OrderList 组件还在直接对整个响应做 .map()。
1.4 多组件系统收集证据
这个bug涉及前端和BFF两层。AI在组件边界加诊断日志:
// 在API调用处console.error('DEBUG fetchOrders:', { url, params, response: data });// 在Hook处console.error('DEBUG useOrders:', { rawData: data, extractedOrders: data?.orders });// 在组件处console.error('DEBUG OrderList:', { orders, type: typeof orders, isArray: Array.isArray(orders) });跑一次,收集到的证据:
DEBUG fetchOrders: { url:'/api/orders', params: {page:1}, response: {orders: [...], total:42} }DEBUG useOrders: { rawData: {orders: [...], total:42}, extractedOrders:undefined }DEBUG OrderList: { orders: {orders: [...], total:42}, type:'object', isArray:false }证据显示:API返回格式正确,但useOrders没有从返回值中提取 .orders,直接把整个对象传给了组件。
1.5 追踪数据流
AI追踪数据从接口到组件的完整路径:
api/orders.ts 的 fetchOrders() 返回 { orders: Order[], total: number } ✓hooks/useOrders.ts 的 useOrders() 把返回值直接存到 state ✗(应该提取 .orders)OrderList.tsx 从 useOrders() 拿到 state,直接对 state 做 .map() ✗问题在第2步和第3步:Hook没有提取 .orders,组件对整个对象做 .map()。
根因找到了:接口返回格式变了,Hook和组件没有同步更新。
到这一步,AI还没有改任何代码。
阶段2:模式分析
2.1 找正常工作的类似代码
AI搜索项目中其他使用了 fetchOrders 的地方:
grep -rn "fetchOrders" src/发现 Dashboard.tsx 也调用了 fetchOrders,但它在渲染时用了 data.orders.map(),没有白屏。
2.2 对比参考实现
AI完整阅读了 Dashboard.tsx 中调用 fetchOrders 的部分,确认它正确地从返回值中提取了 .orders。这个参考实现就是"正常工作的代码"。
2.3 对比差异
const { data } = useOrders() | const orders = useOrders() | |
data.orders.map() | orders.map() | |
差异确认:Dashboard 正确地从返回值中取了 .orders,OrderList 没有。
2.4 理解依赖
AI检查了 useOrders Hook的依赖:它依赖 fetchOrders 的返回格式。当 fetchOrders 的返回格式变更时,所有调用方都需要同步更新。Dashboard 更新了,OrderList 漏了。
阶段3:假设验证
AI提出假设:"OrderList组件需要从useOrders返回值中取 .orders 属性"。
做最小改动验证:
// 修改前const orders = useOrders();// 最小改动const { orders } = useOrders();只改了这一行,其他都不动。提交表单测试:白屏消失,订单正常显示。
假设确认。(这个case比较简单,阶段3的验证改动和阶段4的正式修复恰好一样。在复杂场景中,阶段3可能是临时加一行日志或hardcode一个值来验证假设,确认后阶段4才写正式的修复代码和测试。)
阶段4:实施修复
systematic-debugging要求先写失败测试,再修代码。
4.1 写失败测试
test('fetchOrders返回新格式时,OrderList正确渲染订单列表', () => {// 模拟新格式的API返回 mockFetchOrders.mockResolvedValue({orders: [{ id: 1, name: '测试订单' }],total: 1, });render(<OrderList />);// 验证组件能正确从 { orders, total } 中提取 orders 并渲染expect(screen.getByText('测试订单')).toBeInTheDocument();});运行测试:失败。因为组件还在对整个返回值做 .map()。
4.2 修复根因
// 修改前const orders = useOrders();// 修复后const { orders } = useOrders();运行测试:通过。
4.3 验证没有其他测试被破坏
npm test全部通过。
到这里,这个bug修好了。但这个例子太简单了——看报错信息基本就能猜到根因。下面看一个报错位置和根因远离的场景,这才是systematic-debugging真正发挥价值的地方。
五、实战2:报错位置和根因隔了4层
场景:一个Node.js工具链项目,测试环境跑CI时,git init 在源码目录执行了,而不是在临时目录。这导致 .git 文件夹出现在了 packages/core/ 里,污染了源码仓库。
报错信息指向的是 git init 命令本身,但根因在4层调用之外。
阶段1:根因调查
读错误信息:git init 在 /Users/jesse/project/packages/core 执行了,而不是在临时目录。
复现: 每次跑测试都会在 packages/core/ 下生成 .git 目录。
检查最近变更: 最近改了 Session.create() 的初始化逻辑。
追踪数据流(5层):
git init 在 process.cwd() 执行 ← 空的 cwd 参数WorktreeManager.createSessionWorktree(projectDir, sessionId) ← projectDir 是空字符串Session.initializeWorkspace() ← 传了空字符串Session.create() ← 传了空字符串beforeEach 之前就访问了 context.tempDir ← setupCoreTest() 返回 { tempDir: '' }根因找到了:不是 git init 本身有问题,是测试代码在初始化之前就访问了临时目录变量,拿到空字符串,一路传到底,git init 拿到空字符串作为工作目录,解析为 process.cwd()(源码目录)。
报错位置和根因隔了4层调用。如果只看报错位置修——给 git init 加个目录检查——能修掉这一个场景,但下次其他命令拿到空路径,同样的问题还会出现。修根因(让 tempDir 在被提前访问时抛错)才能一劳永逸。
阶段2:模式分析
AI找到项目中其他地方使用 tempDir 的代码,发现所有正常使用的地方都在 beforeEach 之后访问。只有这一个测试在 beforeEach 之前访问了。
阶段3:假设验证
假设:"把 tempDir 改成 getter,在 beforeEach 之前访问就抛错"。
最小改动:把 tempDir: '' 改成 get tempDir() { if (!this._tempDir) throw new Error('...'); return this._tempDir; }。
跑测试:.git 不再出现在源码目录。假设确认。
阶段4:实施修复
写失败测试:访问 context.tempDir 在 beforeEach 之前,断言抛错。
修复根因:实现 getter。
跑测试:通过。
但systematic-debugging还要求一步:纵深防御。修完根因后,在数据流经过的每一层都加校验,让同类bug在结构上不可能发生:
Project.create() 校验 workingDirectory 不能为空、必须存在、必须是目录WorkspaceManager 校验 projectDir 不能为空git init 拒绝在临时目录之外执行git init 前记录目录、cwd、调用栈为什么4层而不是1层?不同的代码路径可能绕过某一层。入口校验能拦住大多数情况,但mock和测试可能绕过;业务逻辑校验能拦住边缘情况,但跨平台差异可能绕过;环境守卫能拦住特定上下文。4层一起,同类bug极难再发生。
如果手动追踪走不通怎么办?
上面的例子是手动逐层追踪找到的根因。但有些调用链很深,手动追踪会断。这时候有两个技术可以用:
加栈追踪: 在问题操作前打印完整调用链:
asyncfunctiongitInit(directory: string) {const stack = newError().stack;console.error('DEBUG git init:', { directory,cwd: process.cwd(), stack, });awaitexecFileAsync('git', ['init'], { cwd: directory });}用 console.error 而不是 logger(logger在测试中可能被静默)。跑测试后搜索 DEBUG git init 就能看到完整调用链。
二分查找污染源: 如果某个测试污染了全局状态导致其他测试失败,但不知道是哪个测试,可以用二分法:逐个跑测试,找到第一个污染源。Superpowers提供了一个脚本 find-polluter.sh 来做这件事。
六、verification-before-completion:没跑命令,不能说"搞定了"
systematic-debugging修完bug后,怎么确认真的修好了?靠verification-before-completion。
这个Skill的铁律:
它定义了一个5步门禁函数:
常见的错误声明和正确声明对比:
npm test,34/34通过,0个失败" | |
npm test -- --coverage,覆盖率87%,0个失败" | |
npm test -- OrderList,白屏测试通过,回归测试通过" | |
git diff,变更2个文件,+5行-3行" |
"刚才跑过了"为什么不行? 因为你可能在两次运行之间又改了代码。上一次的测试结果不能证明当前代码没问题。verification-before-completion要求的是"新鲜的证据"。
容易踩的信号
Skill原文列举了几个典型的"快要违反铁律"的信号,看到这些信号就该停下来了:
Skill原文记录了多次违反验证铁律的失败案例,包括:代理报告"成功"但实际有未定义函数、功能不完整就声称完成、信任代理报告导致浪费时间返工。这些案例的共同点:没跑命令就声称完成,结果部署后出问题。
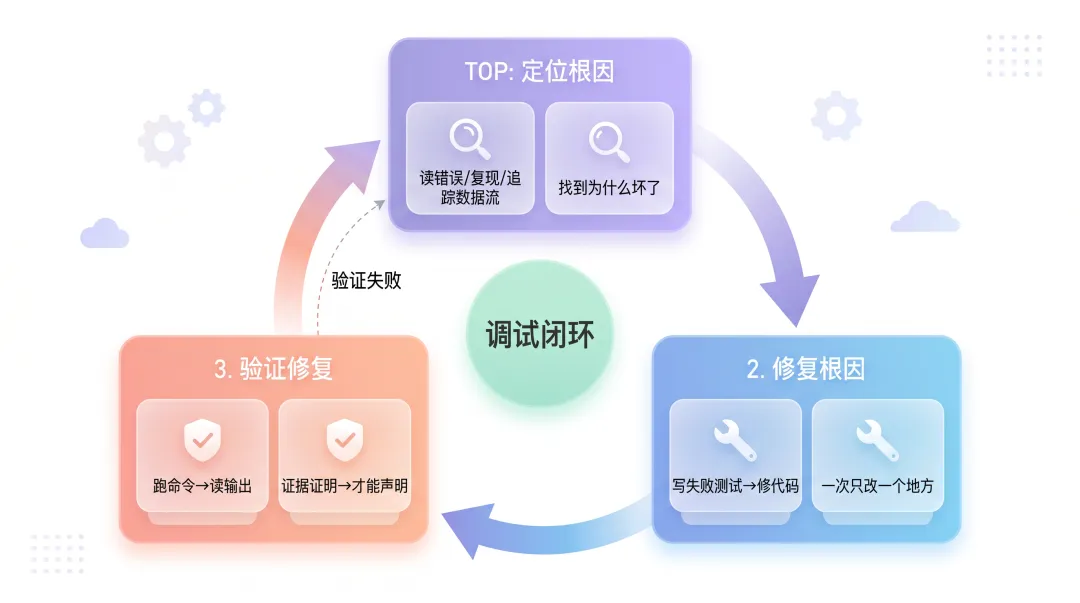
七、两个Skill怎么配合
systematic-debugging和verification-before-completion不是孤立的两个Skill,它们组成一个闭环:
少了第3步和第4步,修bug就少了闭环。你可能修了A但破坏了B,自己还不知道。
一个完整的调试闭环示例:
你:提交表单后页面白屏,帮我修一下AI(进入systematic-debugging阶段1): 读错误信息:TypeError: Cannot read properties ofundefined (reading 'map') 复现条件:提交新订单后白屏,刷新后恢复 检查变更:最近提交改了接口返回格式 多组件收集证据:在API、Hook、组件边界加日志,确认数据在Hook层丢失 追踪数据流:接口返回{orders, total},Hook没有提取.ordersAI(进入阶段2): 找正常代码:Dashboard.tsx用了data.orders.map(),没问题 对比参考实现:完整阅读Dashboard的调用方式 对比差异:OrderList没有取.orders属性 理解依赖:useOrders依赖fetchOrders的返回格式AI(进入阶段3): 假设:OrderList需要从返回值取.orders属性 最小改动:const { orders } = useOrders() 验证:白屏消失 假设确认 → 进入阶段4AI(进入阶段4): 写失败测试:模拟新格式API返回,断言组件正确渲染 运行测试:失败(确认测试能捕获bug) 修复根因:改解构赋值 运行测试:通过AI(进入verification-before-completion):IDENTIFY:什么命令能证明bug修好了?RUN:npm testREAD:34/34通过,0个失败VERIFY:全部通过,确认修复 声明:运行npm test,34个测试全部通过,0个失败。OrderList白屏bug已修复。你:确认,提交代码注意最后一个声明。AI不是说"修好了",而是说"运行npm test,34个测试全部通过,0个失败"。前者是主观判断,后者是客观证据。
八、3个辅助技术
systematic-debugging带了3个辅助技术,它们不只是"特定场景才用"的可选工具——根因追踪是阶段1的核心技术,纵深防御是修复后的必要步骤,条件等待是修时灵时不灵bug的唯一可靠方法。
8.1 根因追踪(root-cause-tracing)
适用于:错误发生在调用栈深处,你不清楚数据是从哪里开始错的。
方法:从报错位置开始,逐层向上追踪,找到数据的源头。如果手动追踪走不通,加栈追踪(new Error().stack)打印完整调用链。如果是测试污染问题,用二分法逐个跑测试找到污染源。
核心原则:永远不要只修报错位置,要修源头。 报错位置是症状,源头是根因。修症状,同一个根因会换个方式冒出来。
8.2 纵深防御(defense-in-depth)
适用于:修完一个bug后,想防止同类bug再次出现。
方法:在数据流经过的每一层都加校验。4层模型:入口校验、业务逻辑校验、环境守卫、调试日志。
为什么需要4层而不是1层?不同的代码路径可能绕过某一层。入口校验能拦住大多数情况,但mock和测试可能绕过;业务逻辑校验能拦住边缘情况,但跨平台差异可能绕过;环境守卫能拦住特定上下文,但正常使用不会触发。4层一起,同类bug极难再发生。
8.3 条件等待(condition-based-waiting)
适用于:测试中有 setTimeout、sleep 等硬编码等待,导致测试时灵时不灵。
方法:用"等待条件满足"替代"等待固定时间"。
// 错误:猜时间awaitnewPromise(r =>setTimeout(r, 50));const result = getResult();// 正确:等条件awaitwaitFor(() =>getResult() !== undefined);const result = getResult();3个常见错误:
setTimeout(check, 1) 浪费CPU,应该10ms轮询一次什么时候不该用条件等待:测试实际的时序行为(debounce、throttle间隔)时,应该用固定等待,但必须注释说明为什么需要固定等待。
根据实际使用反馈:一批时灵时不灵的测试改成条件等待后,通过率可以从60%左右提升到接近100%,执行时间也明显缩短。
九、AI修bug的借口,和Superpowers怎么堵
systematic-debugging的借口:
verification-before-completion的借口:
第4条借口"我试了2次都没修好"特别值得注意。3次规则不是"试3次就放弃",而是:
写在最后
调试的本质不是"改代码让报错消失",而是"找到根因,修掉根因,验证修复"。systematic-debugging逼AI走完"定位-修复-验证"的完整闭环,verification-before-completion逼AI用命令输出说话而不是用"应该没问题"糊弄。两个Skill配合,把修bug从猜谜游戏变成工程流程。
修bug的纪律比写代码的能力更容易被忽视,但大部分开发时间不是在写新代码,是在修旧bug。让AI修bug修得靠谱,比让它写代码写得快更有价值。
