 夜雨聆风
夜雨聆风


01
前言
很多人做知识库、RAG、文献分析、合同审查、论文整理时,第一步就卡在一个非常现实的问题上:PDF 看起来很规整,但机器读起来很痛苦。
尤其是科研论文、技术手册、财报、扫描件、表格型文档,里面往往混着标题、正文、公式、图片、表格、脚注、页眉页脚。人眼看没问题,但一旦丢给大模型,就可能出现顺序混乱、表格丢失、公式乱码、图片说明断裂等问题。
这也是 MinerU 这类文档解析工具存在的价值。
02
MinerU2.0-2505-0.9B 是什么
MinerU2.0-2505-0.9B 是 OpenDataLab 发布的一款面向文档理解与解析场景的开源模型。在 ModelScope 页面中,它被归类为“文档理解”模型,参数规模约 1.03B,权重格式为 Safetensors,张量类型为 BF16,模型大小约 2.06GB,并采用 Apache License 2.0 开源协议。用户可以通过 ModelScope SDK 或 Git clone 下载模型。
从定位上看,它不是一个普通的聊天大模型,而更像是面向 PDF、文档结构识别、内容抽取和格式转换任务的“文档解析底座”。
简单理解:它的目标不是陪你聊天,而是帮 AI 把复杂文档先读明白。
03
解决的核心痛点
传统 PDF 解析最常见的问题,不是“能不能提取文字”,而是:
✅ 文字顺序乱了;✅ 表格结构散了;✅ 公式识别错了;✅ 图片和说明分家了;✅ 双栏论文变成一锅粥;✅ 扫描件还要额外做 OCR。
MinerU 官方文档中提到,它可以将 PDF、图片、DOCX、PPTX、XLSX 等输入转换为 Markdown、JSON 等机器可读格式,并支持保留标题、段落、列表等原始文档结构;同时还能提取图片、表格、表格标题、脚注,并将公式转换为 LaTeX、表格转换为 HTML。
这意味着,它更适合放在 AI 应用的前置环节:先把文档拆干净、理清楚,再交给大模型做总结、问答、检索或分析。
04
适合做知识库和RAG
很多知识库项目效果不好,不一定是大模型不行,而是“入库数据太脏”。比如一篇论文原本是:
标题 → 摘要 → 方法 → 实验 → 表格 → 结论
结果被粗暴抽取后变成:
页眉 → 页码 → 表格碎片 → 正文半句 → 图片说明 → 公式乱码
这种内容进入向量库后,召回质量自然会下降。大模型不是背锅侠,前面的文档解析才是关键工序。
MinerU 的优势就在于,它输出的是更适合后续处理的 Markdown、JSON 和中间结构化文件。MinerU 生态仓库也明确将其定位为面向 LLM 预训练、RAG 和 Agent 工作流的高精度文档解析引擎。
对于企业知识库来说,这类能力尤其重要。因为企业文档往往不是纯文本,而是合同、制度、报告、标书、PPT、扫描件、表格的混合体。文档解析质量越高,后续问答、摘要、审查、抽取的效果就越稳定。
05
应用场景
1️⃣ 科研文献解析
论文中最难处理的不是文字,而是公式、表格、图注和多栏排版。MinerU 可用于将论文转换成 Markdown 或 JSON,方便后续做文献综述、实验方法提取、指标对比和知识图谱构建。
2️⃣ 企业知识库入库
企业内部制度、产品手册、培训材料、合同模板,都可以先通过 MinerU 解析成结构化内容,再进入 RAG 流程,减少“答非所问”和“引用错位”。
3️⃣ 合同与报告自动化处理
合同、审计报告、财务报告通常版式复杂,直接复制文本容易丢失结构。通过文档解析,可以先提取章节、条款、表格,再交给大模型做风险点分析或信息抽取。
4️⃣ AI Agent 文档工作流
MinerU 官网还提供在线 API、离线部署和桌面客户端等形态,面向 PDF 中表格、公式、文字和图片提取,并支持转换为 Markdown、JSON 等格式。 这使它可以接入自动化流程,比如“上传 PDF → 自动解析 → 生成摘要 → 建立知识库 → 输出结构化报告”。
06
部署与使用方式
根据你提供的 ModelScope 信息,模型可以通过 ModelScope SDK 下载:
from modelscope import snapshot_downloadmodel_dir = snapshot_download('OpenDataLab/MinerU2.0-2505-0.9B')# 也可以通过 Git clone 获取:# bashgit clone https://www.modelscope.cn/OpenDataLab/MinerU2.0-2505-0.9B.git
需要注意的是,文档解析模型通常不仅看模型权重,还要看配套推理框架、MinerU 主程序版本、显卡环境、依赖库是否匹配。MinerU 官方更新日志显示,后续 VLM 后端已经升级到 2.5,并且最后支持 MinerU2.0-2505-0.9B 的版本是 mineru-2.2.2。
所以如果是为了复现 MinerU2.0-2505-0.9B,建议优先锁定兼容版本;如果是新项目落地,则可以同时评估 MinerU 后续版本或 pipeline 后端。
07
模型下载
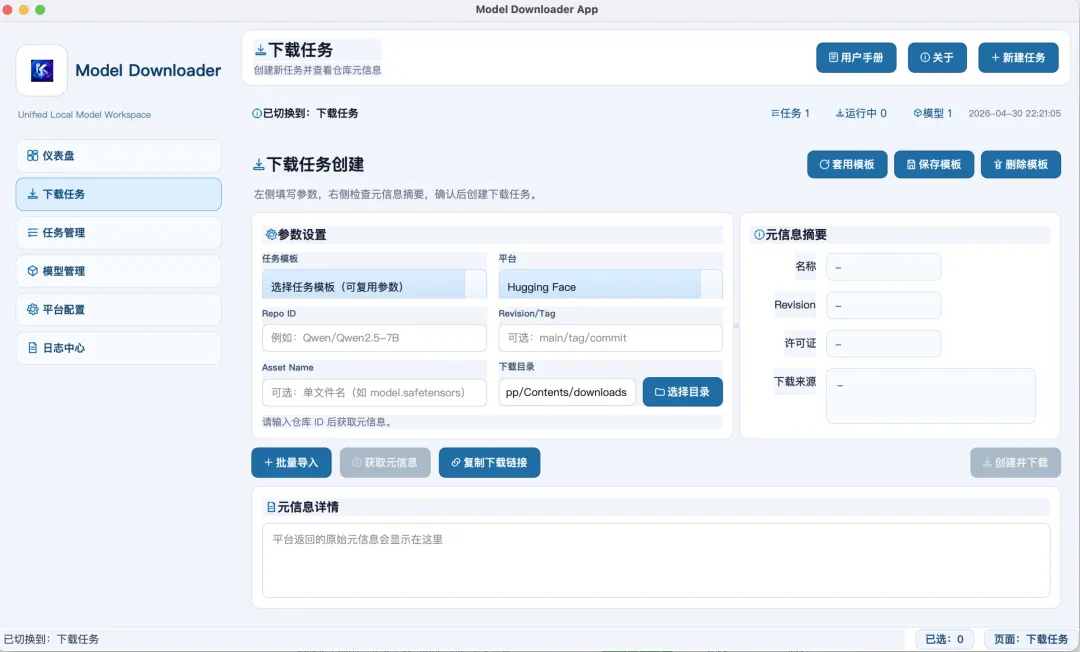
1️⃣ 打开model-downloader-app;
2️⃣ 创建下载任务;
3️⃣ 选择开源模型平台;
4️⃣ 输入repo id

如果你也经常被 PDF 论文、报告、合同、表格文档折磨,MinerU2.0 这类文档解析工具值得重点关注。它真正解决的不是“把 PDF 变成文字”,而是让文档变成 AI 能理解、能入库、能检索、能分析的数据。后续我会继续分享更多 AI 文档解析、知识库 RAG、科研工具和大模型落地案例。觉得有用的话,欢迎点赞👍、推荐❤️、转发📄给正在做知识库或文献分析的朋友。想了解更多 AI 工具实战,也可以关注我,一起把复杂文档变成可用数据。



往期推荐
MGeo地址解析:让中文地址从“看不懂”变“可计算”
emotion2vec+large:让机器听懂语气背后的情绪
TabPFN-3来了:表格数据建模可能要换一种玩法了
地铁里也能听清?ZipEnhancer让语音降噪更进一步
Lyra 2.0来了:一张图生成可探索3D世界

分享给你第一个想到的人
