 夜雨聆风
夜雨聆风
01 全球AI产品宏观认知
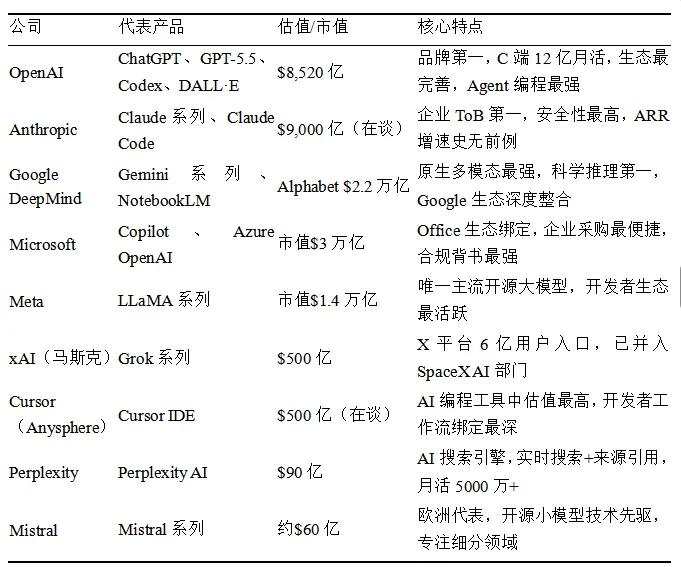
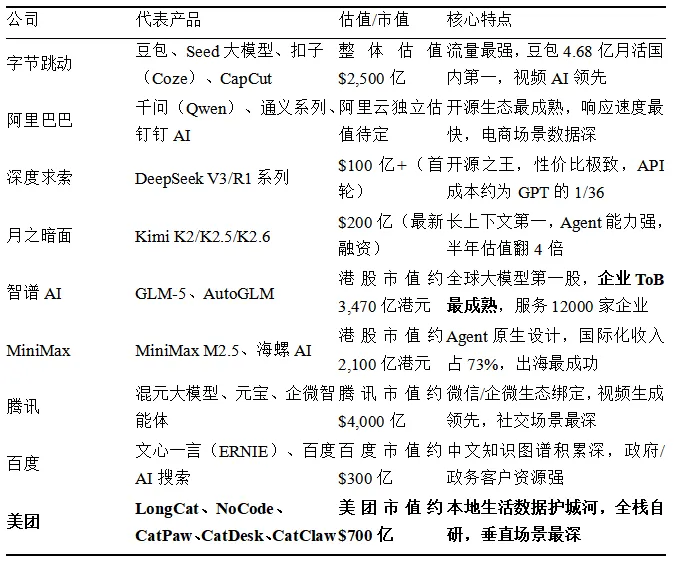
1、海外公司及旗下AI 产品
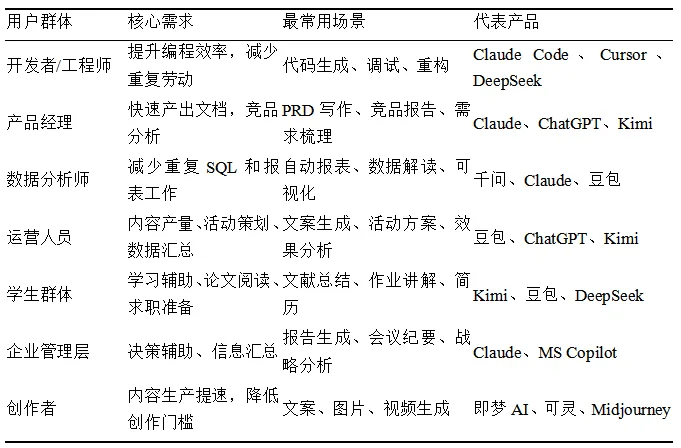
3、按用户群体划分应用场景
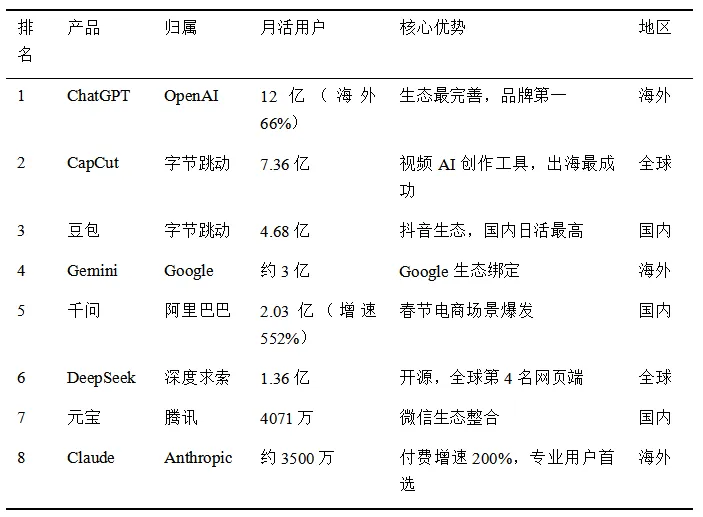
02 需掌握的核心概念
1、AI的核心构成(算力、算法、数据)
算力是AI运行的物理基础,本质是计算资源。模型训练需要对海量数据反复做矩阵运算,没有足够的GPU/TPU算力,再好的算法也跑不起来。
算力决定了模型能做多大、训练多快。
算法是AI的思维方式,定义了模型如何从数据中学习规律。深度学习、Transformer架构、强化学习等,都是算法层面的突破。
算法决定了同样的数据和算力能榨出多少智能。
数据是AI的原材料,模型学到的所有知识和能力都来自训练数据。
数据的规模、质量、多样性直接决定模型的上限。垃圾数据进,垃圾结果出。
三者的关系是:数据提供素材,算法提供方法,算力提供执行能力,缺一不可。
历史上每一次AI的重大突破,背后都是这三者中至少一个维度的跃升。三者之间并不是简单的并列关系,而是一个相互驱动的正向飞轮。
数据是起点。原始数据经过清洗和标注后,喂给算法模型进行训练。
训练的过程本质上是算法在算力的支撑下,反复从数据中提取规律、调整参数的过程。
模型训练完成后,部署到真实场景中产生新的用户交互,这些交互又沉淀为新的数据,反哺下一轮训练,数据在这个循环里是自我增殖的。
算法是枢纽。它向下依赖算力来执行计算,向上依赖数据来学习规律。
但算法的进步也会反向改变另外两者的需求:更高效的算法(比如注意力机制的稀疏化)可以降低对算力的消耗;更好的数据处理算法(比如合成数据、数据蒸馏)可以在数据量不足时提升数据的有效利用率。
算力是加速器。算力的提升让算法能够处理更大规模的数据、跑更深的网络,从而涌现出原本不可能出现的能力。
反过来,算力的瓶颈也会倒逼算法创新,历史上很多算法优化,本质是在有限算力下逼出来的。
整个循环可以概括为:更多数据训练出更强模型,更强模型产生更多有价值的数据;更好的算法降低算力门槛,算力的释放又让更复杂的算法成为可能。
三者互为因果,共同推动AI能力螺旋式上升。
2、大模型(LLM)
基于海量文本数据训练的神经网络模型,能理解和生成自然语言。是所有AI产品的技术底座,相当于"引擎"。
代表:GPT-5.5、Claude 3.7、DeepSeek V3、Qwen3。区别于AI助手:大模型是底层技术,AI助手是基于大模型建的产品。
3、AI Agent(AI智能体)
能够自主规划、决策并执行多步骤任务的AI系统。和普通AI助手的本质区别:助手是"回答你的问题",Agent是"替你把事情做完"。
例如:你告诉Agent"帮我整理本周竞品动态",它会自动搜索、筛选、归纳、生成报告,全程不需要人工干预。2026年是Agent商业落地元年,美团CatClaw/CatDesk的核心就是Agent。
4、OpenClaw
2026年初爆火的开源AI Agent框架,GitHub获得超24万Star,是本年度最热开源项目。
核心能力是让AI在本地环境自主执行任务,浏览器操作、文件处理、代码运行、跨系统数据搬运。被称为"小龙虾"(Claw=爪/龙虾)。
原名Clawdbot,后改名OpenClaw,2026年2月被OpenAI收购,成为ChatGPT Workspace Agents的技术底座。
最大短板:部署需要Terminal命令行,普通用户无法直接使用。
QClaw 腾讯基于OpenClaw开源生态打造的本地化AI Agent产品,昵称"小龙虾AI"。
核心创新是把OpenClaw的部署门槛降到最低,并通过微信小程序直连。用户在微信里发一条消息,电脑就自动执行任务。
支持Windows/macOS双平台,内置国产大模型,内置5000+技能(Skill)生态。2026年3月公测,是美团CatClaw最直接的国内竞品。
5、Skill(技能/能力封装)
把一个复杂的AI任务流程标准化、可复用地封装起来,让用户不需要写提示词,直接调用就能完成特定工作。
类比:相当于软件里的"插件"或"模板"。
例如:一个"竞品分析报告"Skill,封装了"输入竞品名→自动搜索→按固定框架整理输出"的完整流程,产品经理只需填入竞品名字就能得到结构化报告。
Skill的价值:对用户降低使用门槛(从"会写提示词"降到"会选模板"),对平台积累用户粘性(用得越多越难迁移)。
6、RAG(检索增强生成)
让AI在回答问题时,先从外部知识库中检索相关信息,再生成答案。
解决的问题是大模型训练数据有截止日期、不知道企业内部信息。
企业内部知识库问答系统的核心技术:员工问"我们公司的差旅报销标准是什么",AI先检索内部文档,再给出准确答案。
7、提示词 / Prompt
用户输入给AI的指令或问题。
提示词工程(Prompt Engineering)是设计高质量提示词的技巧,决定AI输出质量的上限。
Skill本质上是把经过优化的提示词模板封装起来,让普通用户不需要懂提示词工程就能用好。
8、Token
AI模型处理文本的基本单位,大约相当于0.75个英文单词或0.5个中文字。
Token是AI产品API计费的基础单位。
上下文窗口(Context Window)是AI一次能处理的最大Token数量:Claude 3.7支持100万Token(约75万英文单词),Kimi K2.5支持200万Token。
Token越多,能处理的文档越长。
9、多模态(Multimodal)
AI能同时理解和生成多种类型内容,文字、图片、音频、视频。
代表产品:Gemini 2.0(原生多模态,能看视频、听声音)、GPT-4o(支持语音实时对话)。
区别于纯文本模型:DeepSeek V3只处理文字,是单模态;Gemini能看图听声,是多模态。
10、MAU(月活跃用户)
每月至少使用一次产品的用户数量。
ToC产品最重要的规模指标。
ChatGPT 12亿MAU,豆包4.68亿MAU,是衡量产品渗透率的核心数据。
11、MaaS(模型即服务)
把AI大模型能力以API形式对外提供,按调用量计费。企业不需要自己训练模型,直接调用就能用上顶尖AI能力。
智谱AI的主要商业模式,美团对外推CatClaw也可能走这条路。
12、SaaS(软件即服务)
通过订阅制提供软件服务,按用户数或用量收费。Microsoft Copilot($30/用户/月)是典型SaaS定价。
区别于MaaS:SaaS按席位,MaaS按调用量。
13、私有化部署
把AI系统部署在企业自己的服务器上,数据不流出企业内网。
国内企业ToB的核心需求:数据安全、合规、隐私保护。DeepSeek开源可本地部署、大厂数据不出境,都是私有化部署的竞争优势。
14、PS倍数(Price-to-Sales)
估值/年收入,衡量市场对公司未来成长性的预期。Cursor估值$500亿÷ARR $20亿≈25倍PS,说明市场认为其场景绑定深度值得高溢价。
目前AI公司普遍享有20-25倍PS,远高于传统软件公司的5-10倍。
15、MoE(混合专家架构)
把一个大模型拆成多个"专家"子模型,每次只激活其中一小部分处理当前任务。
DeepSeek V3和Qwen3都用了这个架构:总参数量大,但实际激活参数只有4%,推理成本极低、速度极快。
这是国产模型实现"以小胜大"、API价格低至GPT的1/36的核心技术原因。
16、微调(Fine-tuning)
在预训练大模型基础上,用特定领域数据继续训练,让模型更擅长某个垂直场景。
例如:用美团本地生活业务数据微调LongCat,让它更懂餐饮、零售场景。区别于RAG:RAG是检索外部知识,微调是改变模型本身。
17、API(应用程序接口)
让不同软件系统之间互相通信的接口。企业调用ChatGPT API,就是通过API把OpenAI的模型能力接入自己的产品。API调用量是Anthropic等公司ToB收入的主要来源。
18、SWE-bench
评估AI代码能力的权威基准测试,考察模型解决真实GitHub软件工程问题的能力。Claude Opus 4.6的SWE-bench得分80.8%,代表其代码修复能力较高,属于全球顶尖。
19、Terminal-Bench
评估AI Agent执行命令行复杂任务能力的基准测试。GPT-5.5得分82.7%全球第一,代表其Agent自动化能力最强。
20、RLHF(基于人类反馈的强化学习)
通过人工标注者对AI输出打分,用强化学习让模型更符合人类偏好,ChatGPT的核心训练方法。
Anthropic在此基础上发展出"宪法AI":用一套规则让AI自我评估输出,减少对人工标注的依赖,安全性更高。
21、Vibe Coding
用自然语言描述需求、让AI直接生成可运行代码或应用的编程范式。分两类:面向零基础用户(Lovable、美团NoCode)和面向有基础开发者(Cursor、Claude Code)。
其他未分享到的AI知识,欢迎评论区补充。
大家一起长期关注AI,终身学习。

您好!我是德华学长,现任美团外卖校园俱乐部华南大区负责人,曾任高顿集团总部hi实习项目全国校园大使运营,加入美团外卖校园俱乐部可扫码👇

