 夜雨聆风
夜雨聆风
医药数据库是什么?今天,我们为你揭开「医药数据宝库」的神秘面纱!想知道如何免费使用这个「医药神器」?往下看,3分钟教你用对数据库,健康少走弯路!”


中文标题:酶介烷基化使得全转录组范围内的伪苷酸修饰能够识别
发表期刊:Nat Commun
发布时间:2026年3月
影响因子:15.7


01
研究背景
Hot
假尿苷(Ψ)是最丰富的 RNA 修饰之一,调控 RNA 结构、翻译、稳定性等,与疾病及 mRNA 疫苗效能密切相关。现有检测方法存在灵敏度低、RNA 易降解、无富集、分辨率不足、无法细胞内标记等局限,亟需高效、精准、温和的转录组水平 Ψ 鉴定新技术。
02
研究方法
Hot
1.筛选并改造古菌来源Mj1640 甲基转移酶,实现 Ψ 的 N1 位甲基化 / 炔基化特异性标记;
2.开发ELAP‑seq(酶促标记 + 富集下拉测序)技术流程;
3.结合 MALDI‑TOF、LC‑MS/MS、qPCR、RT‑stop、IGV 可视化验证;
4.在 HeLa、HEK293T 细胞开展转录组 Ψ 鉴定,结合 DKC1 敲低、IVT 对照、生信分析。
03
研究结果
Hot
1
Mj1640 可特异性对 Ψ 进行甲基化 / 炔基化标记
Mj1640 能在温和条件下高效、特异地将甲基或炔丙基修饰到 RNA 中 Ψ 的 N1 位点,几乎不识别 U,且不依赖 RNA 二级结构。MALDI‑TOF 显示 5 分钟即可完成 > 90% 标记;LC‑MS/MS 证实对细胞总 RNA、polyA RNA 的 Ψ 标记效率达 33%–60%,炔基化约 25%–30%,且 RNA 保持完整、几乎无降解。该酶还可在人细胞内发挥功能,实现内源转录本 Ψ 标记,突破化学法无法胞内标记的瓶颈。
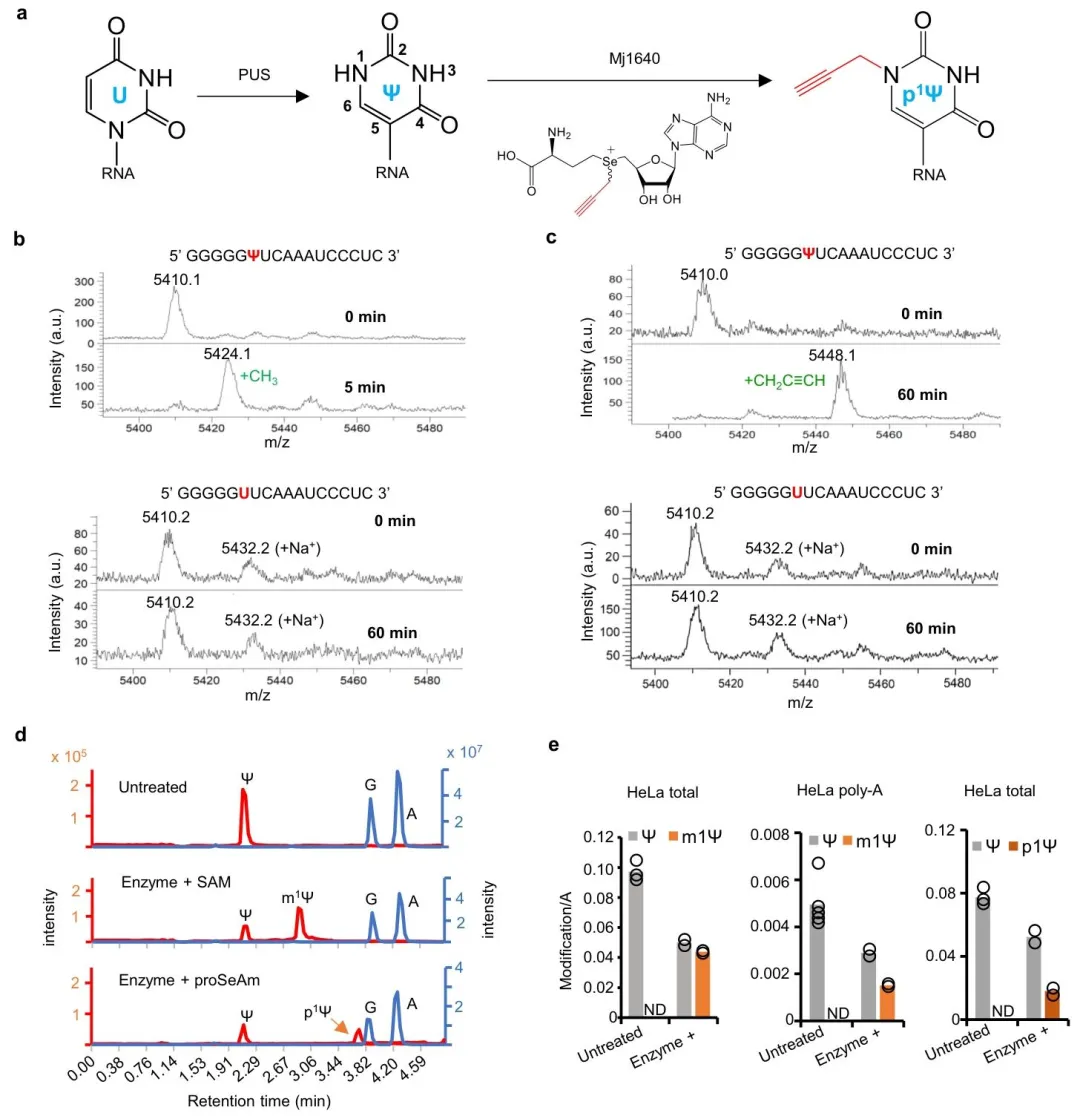
2
建立高信噪比的 ELAP‑seq 测序方法
ELAP‑seq 先将 RNA 片段化,用 Mj1640 进行炔基化标记,再通过点击化学连接生物素,经链霉亲和素磁珠富集含 Ψ 的片段,最后利用低 dNTP 引发 RT‑stop 实现单碱基分辨率。该方法对 Ψ‑RNA 富集倍数高达约 450 倍,背景极低;对 256 种 NNΨNN 序列检测显示,酶偏好 5′‑ΨU‑3′,但仍可标记绝大多数序列。方法重复性高(R²>0.98),显著提升信噪比、降低测序与计算成本。
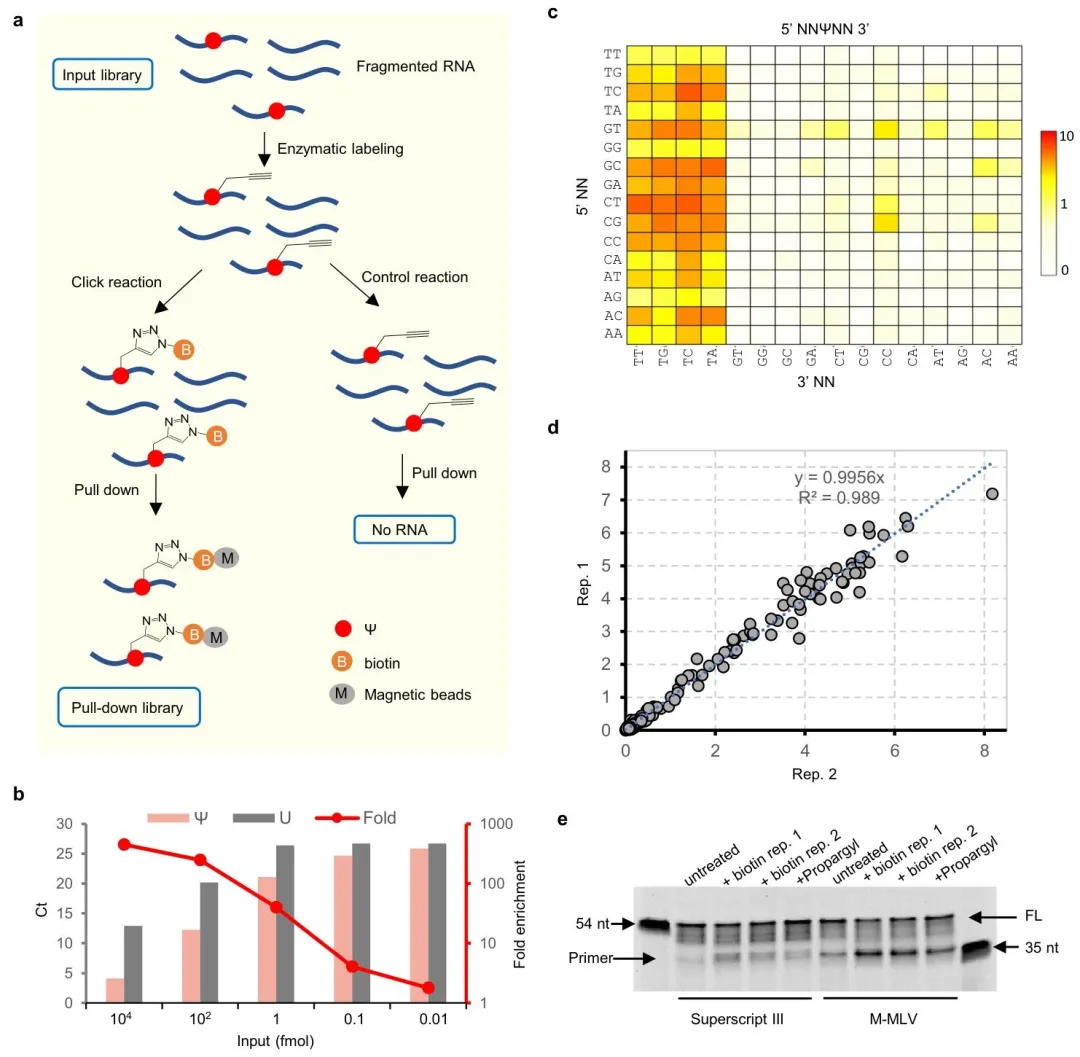
3
ELAP‑seq 精准鉴定 rRNA 中已知 Ψ 位点
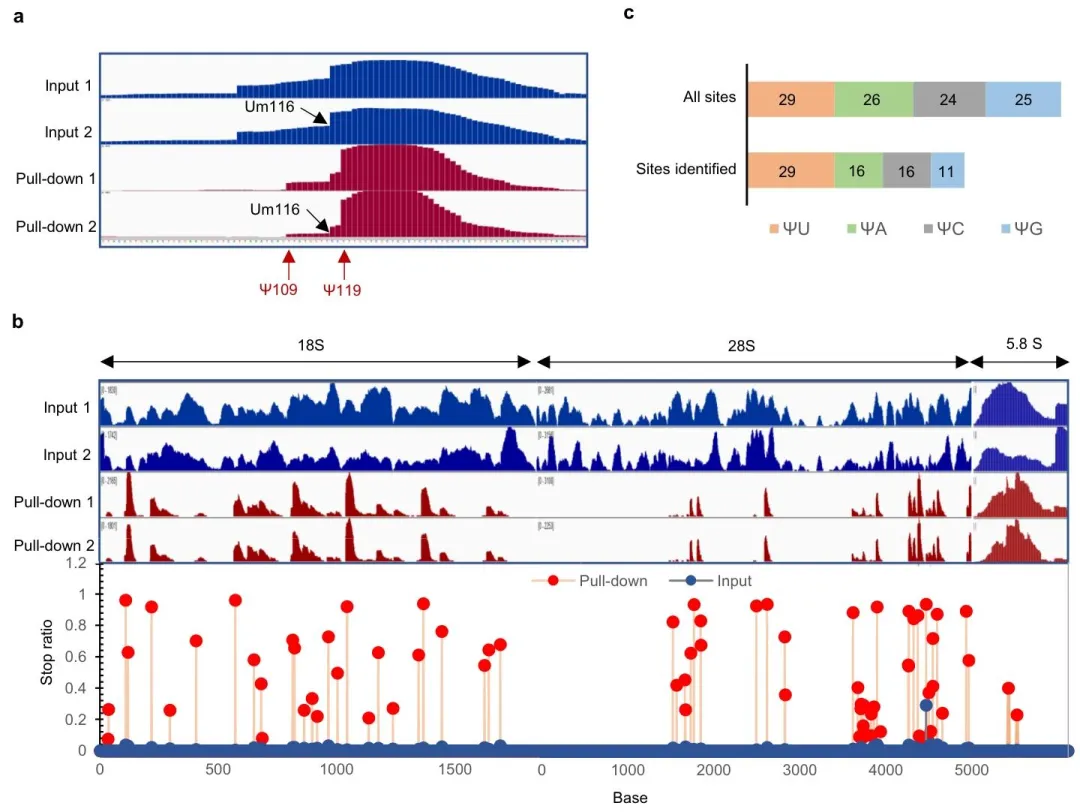
4
人转录组中鉴定数千个高置信度 Ψ 新位点
在 HeLa 与 HEK293T 细胞中分别鉴定出5366和5741个候选 Ψ 位点,约 96% 位于 U 位点,假阳性极低。两种细胞共享约 46% 位点,多数为低丰度修饰。IVT 对照、DKC1 敲低实验、CMC‑RT‑qPCR 三重验证可靠,其中 17/20 位点得到验证,包括大量新位点。方法灵敏度显著优于现有技术,可检出低丰度、低表达基因中的 Ψ。
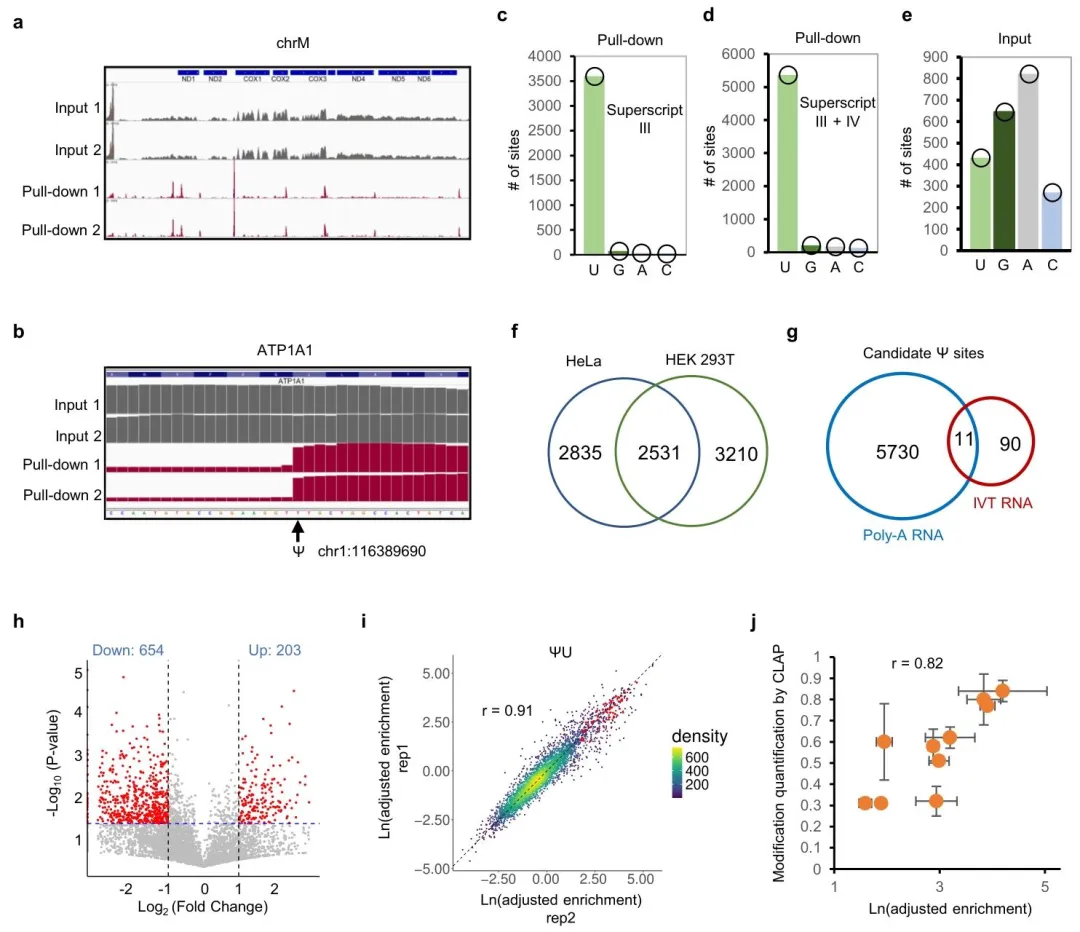
5
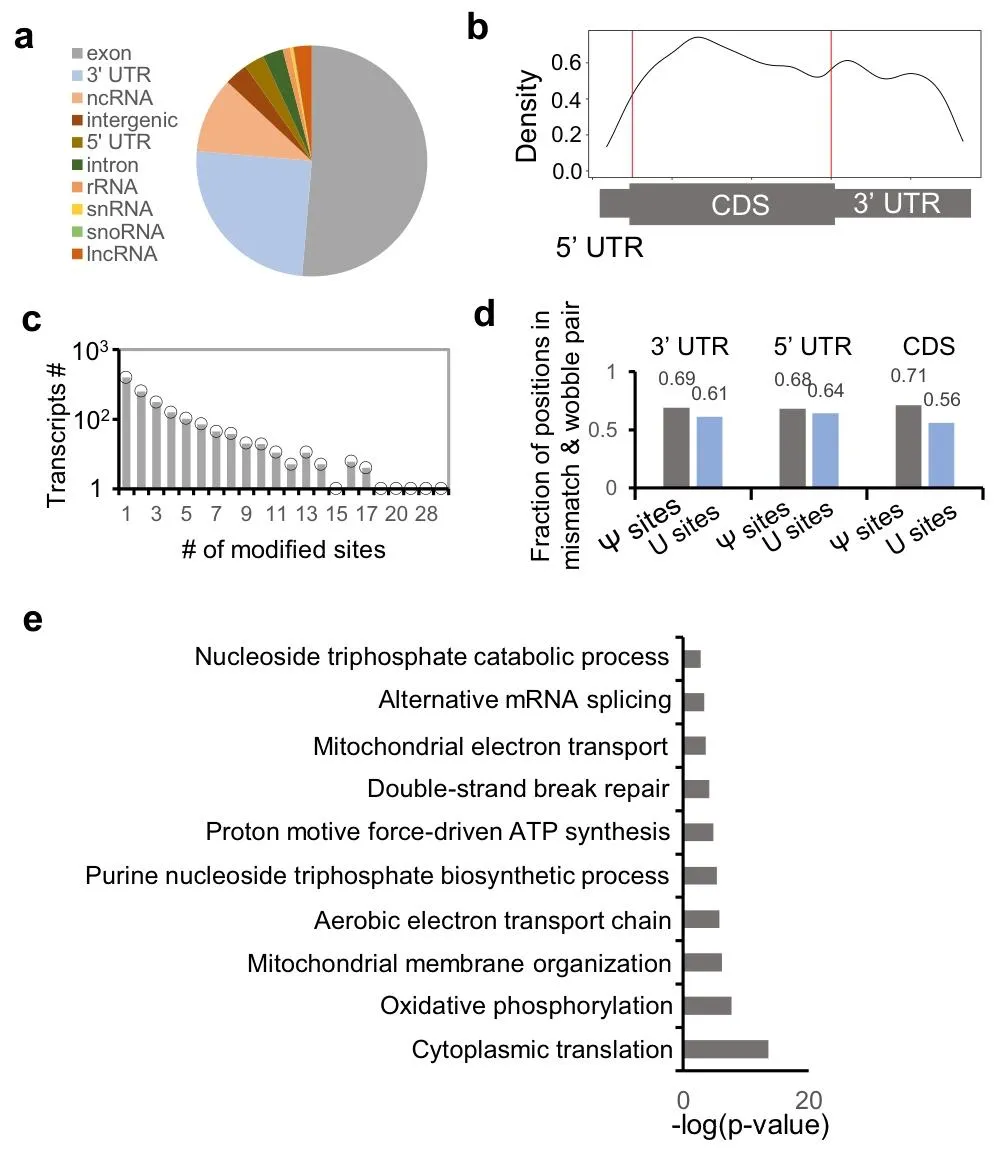
揭示 Ψ 分布规律与功能关联
Ψ 主要富集于 CDS 和 3′UTR,倾向位于 RNA 松散配对区域;多数转录本仅携带 1 个 Ψ。功能富集显示 Ψ 与线粒体电子传递、氧化磷酸化、翻译、DNA 修复密切相关,提示其在能量代谢与细胞应激应答中关键作用。为理解 RNA 表观转录调控、疾病机制与 mRNA 疫苗优化提供新靶点。
04
文章小结
Hot
本研究开发基于 Mj1640 酶促标记的 ELAP‑seq,实现温和、高特异、高富集、单碱基分辨率的转录组 Ψ 检测,可胞内标记并检出大量低丰度新位点。首次系统揭示人细胞 Ψ 分布、序列偏好与功能偏好,为 Ψ 研究提供革命性工具,推动 RNA 修饰生物学、疾病标志物与 mRNA 药物研发。
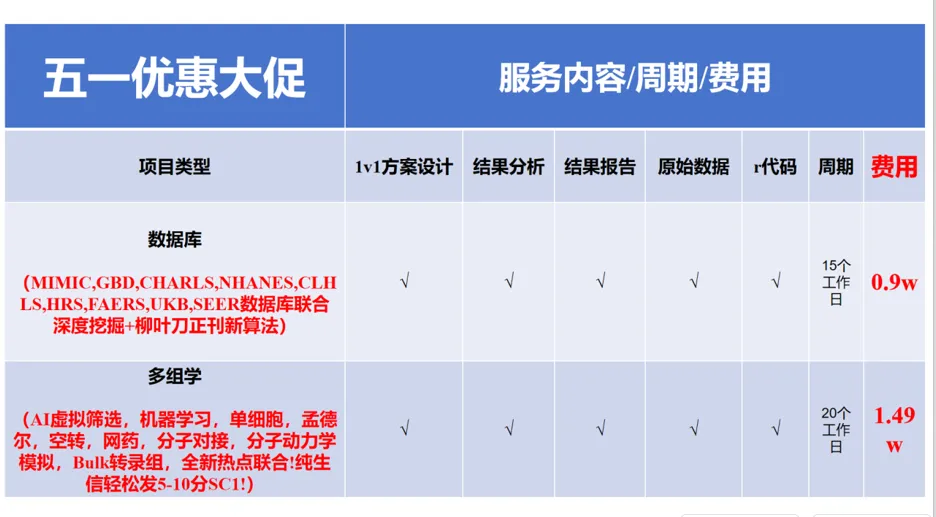
“医药无小事,一个正确的信息可能改变健康结局。希望这个数据库能成为你身边的「医药智囊团」,让每一次选择都更安心。转发给关心的人,或许TA正需要这份指南。医药之路,我们陪你一起走稳!

感兴趣的各位朋友,欢迎大家扫码咨询,我们一定竭尽全力为您答疑解惑!为了您能第一时间收到推送,欢迎各位朋友们关注我们哦!你们的支持是我们最大的动力!祝大家生活愉快!❀☀

往期回顾
4.2/Q2,多组学数据库助力发现!血浆 EVs 中 3 类 lncRNAs 破解 PCOS 合并 MetS 诊断难题
3.4/Q1,儿童和青少年偏头痛负担的上升趋势:1990 年至 2021 年的综合分析及未来预测
3.9/Q3,多组学 “透视” 肝癌!西湖大学团队用 scTrio-seq2+TCGA 揭秘:甲基化距离比基因表达更准推肿瘤进化
欢迎关注我们哦



