 夜雨聆风
夜雨聆风用过 Midjourney 或 Runway 的人大概都有过这种体验:为了调整一个细节(让品牌色保持一致,或者让视频里的人物动作连贯)需要疯狂修改提示词,反复试错,耗费大量时间却依然得不到稳定的结果。
这种"开盲盒"式的工作方式,在个人创作时尚可接受;但一旦进入业务场景,需要批量、稳定、高质量地产出视觉物料,它就成了真正的瓶颈。
破局的思路其实并不复杂:既然写代码可以用自动化测试来保证质量,视觉生成为什么不行?这篇文章想聊的,正是如何把 Agentic Workflow(智能体工作流) 引入图像和视频生成,构建一套真正可落地的自动化媒体生产系统。
一、核心思路:Generate → Evaluate → Iterate
传统工作流的问题在于,"判断好不好"这件事完全依赖人工。人是循环里最慢的那个环节。
生成式媒体 Agent的核心,是把这个判断环节也自动化。整个系统围绕三个步骤不断循环:
生成(Generate):调用底层大模型(如 Google 的 Nano Banana 图像模型或 Veo 视频模型)生成初始素材;
评估(Evaluate):系统自动判断生成的结果是否符合要求;
迭代(Iterate):如果评估不达标,Agent 分析原因,自动调整 Prompt 或参数,重新生成,直到满足质量标准。
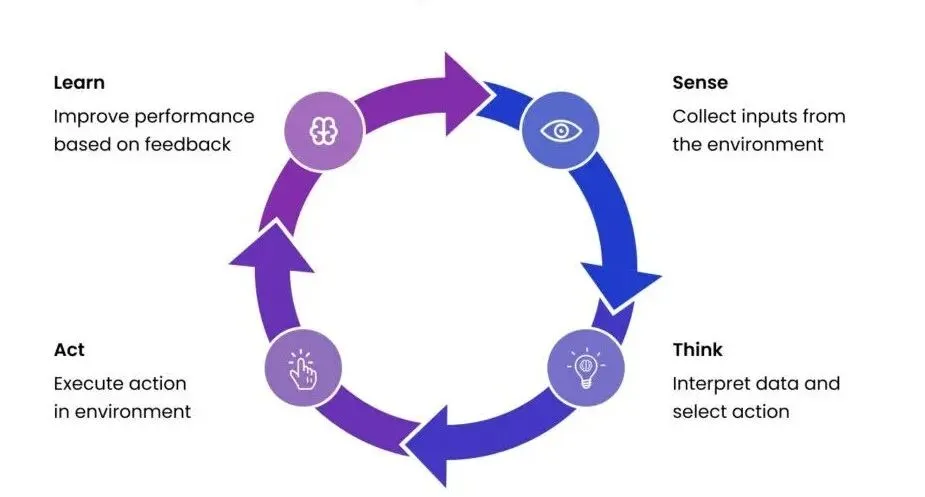
Agent核心循环:Sense - Thnk - Act - Learn四个环节构成闭环,驱动自主迭代
这个循环里,最大的挑战在于"评估"。视觉内容的质量往往是主观的,没有唯一的标准答案。如果 Agent 自己不知道什么是"好",它就无法自我修正。
下面这套三层评估管道,是解决这个问题的关键。
二、三道质量防线:让 Agent 学会"看懂"好坏
第一道防线:图像-文本相似度
这一层使用视觉-语言模型(如 Google 的 SigLIP 或 OpenAI 的 CLIP)来计算生成的图像与目标文本之间的匹配度,快速过滤掉那些明显"跑题"的废片。
SigLIP(Sigmoid Loss for Language Image Pre-Training)的原理是将图像和文本分别通过各自的编码器,映射到同一个特征空间中,然后计算两者的余弦相似度(Cosine Similarity)。如果生成的图和 Prompt 的匹配度低于设定阈值,系统直接将其淘汰重做,不需要进入下一环节。
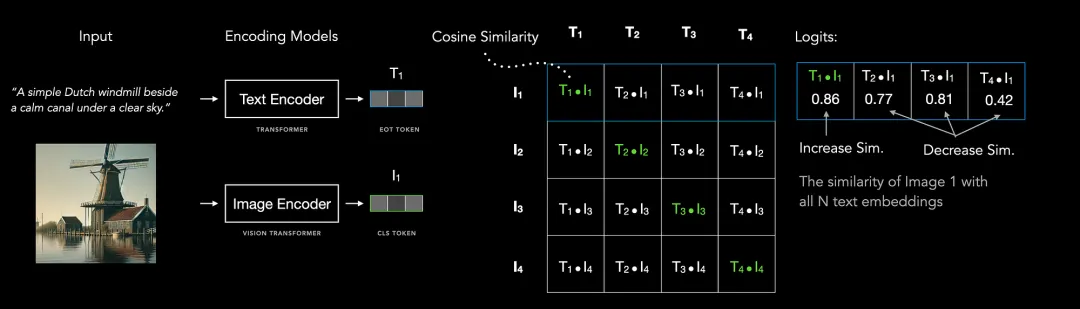
SigLIP架构:图像和文本分别编码后,通过余弦相似度矩阵计算匹配分数,高效过滤跑题废图
这种方法计算成本极低,适合作为第一道快速筛选关卡。
第二道防线:大模型裁判(LLM-as-a-Judge)
对于更复杂的逻辑判断,相似度分数就无能为力了。这时,需要引入多模态大模型(如 Gemini 1.5 Pro)作为"裁判"。
把生成的图片喂给 LLM,并向它提出具体问题:"这张图里有没有包含品牌 Logo?"、"视频中的人物动作是否连贯?"LLM 裁判不仅能给出"是/否"的判断,还能提供详细的反馈意见。这些反馈会被提取出来,输入回生成环节,指导下一次的迭代。
这本质上是让一个强大的 LLM 去当裁判,评估另一个生成模型的输出。
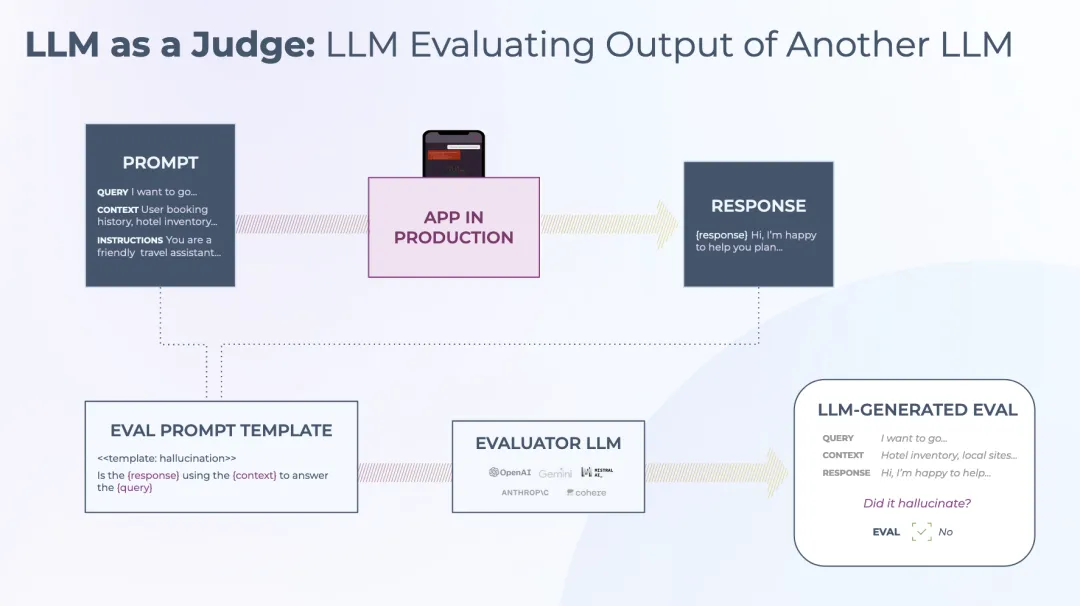
LLM as a Judge架构:生产应用的输出美送入评估LLM,结合评估模板生成结构化的评估报告
第三道防线:结构化评分表(Structured Rubrics)
为了让评估过程标准化、可量化,需要在 Agent 中硬编码明确的多维度打分标准。以 UI 设计图生成 Agent 为例:
评估维度 | 评估问题 | 评分方式 |
色彩一致性 | 是否使用了品牌主色调(RGB 值是否在容差范围内)? | 0–10 分 |
布局合理性 | 元素是否重叠?留白是否充足? | 0–10 分 |
文本准确性 | 按钮上的文字是否拼写正确? | 通过 / 不通过 |
品牌符合度 | Logo 是否出现在正确位置? | 通过 / 不通过 |
三道防线层层把关,Agent 就能像一位不知疲倦的严苛艺术总监,自动把控输出质量。
三、图像生成:让 LLM 帮你写 Prompt,再用参考图锁死风格
用 LLM 扩写"超级 Prompt"
不必自己绞尽脑汁写长难句。更高效的做法是:先用自然语言向 LLM 描述需求,让 LLM 帮你扩写成结构化、细节丰富的"超级 Prompt",再喂给图像模型。
例如,只需说"帮我生成一张光合作用的儿童科普信息图,风格要可爱",LLM 会自动补充构图、色彩、字体风格、元素布局等细节。下图是 Google Nano Banana 模型用这种方式生成的结果——注意它在文本渲染和图文排版上的能力,这正是许多老一代图像模型的弱项:
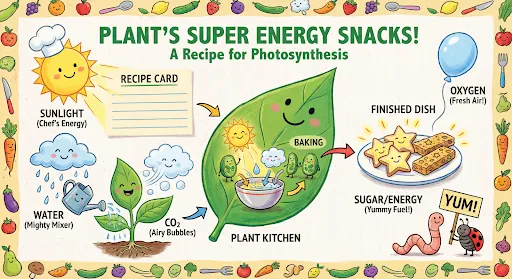
Nano Banana生成的光合作用信息图,展示了模型在文本渲染和信息图排版上的强大能力
Nano Banana 模型目前提供三个版本,各有侧重:
模型 | 适用场景 | API 名称 |
Nano Banana 2 | 高速、大批量开发测试 | gemini-3.1-flash-image-preview |
Nano Banana Pro | 专业资产生产,支持复杂指令和高保真文字 | gemini-3-pro-image-preview |
Nano Banana(基础版) | 高效率、低延迟的轻量任务 | gemini-2.5-flash-image |
用参考图锁死品牌风格
在企业应用中,使用图像到图像(Image-to-Image)的生成方式,提供风格参考或草图,能大幅提升生成结果的可控性。Nano Banana Pro 支持最多 14 张参考图同时输入,足以覆盖复杂的品牌视觉规范。
四、视频生成:Veo 3 的七维提示词结构与起止帧控制
视频生成的难度远大于图像,因为需要同时控制画面内容、运镜方式和时间维度。Google 的 Veo 3 模型的提示词遵循一套清晰的结构:
一个高质量的 Veo 提示词需要覆盖七个维度:
维度 | 含义 | 示例 |
Shot framing | 镜头构图 | "A medium shot" / "Close-up" |
Style | 画面风格 | "historical adventure setting" |
Lighting | 光线氛围 | "Warm lamplight illuminates" |
Character | 角色描述 | 外貌、服装、表情 |
Location | 场景环境 | 室内 / 室外 / 具体地点 |
Action | 动作行为 | 人物的具体动作 |
Dialogue | 对白内容 | 支持直接在提示词中写台词 |
起止帧控制:最被低估的特性
Veo 3 还有一个非常实用的特性:起止帧控制(Start/End Frame)。你可以直接指定视频的第一帧和最后一帧,Veo 会自动在这两帧之间生成平滑、符合逻辑的过渡动画。
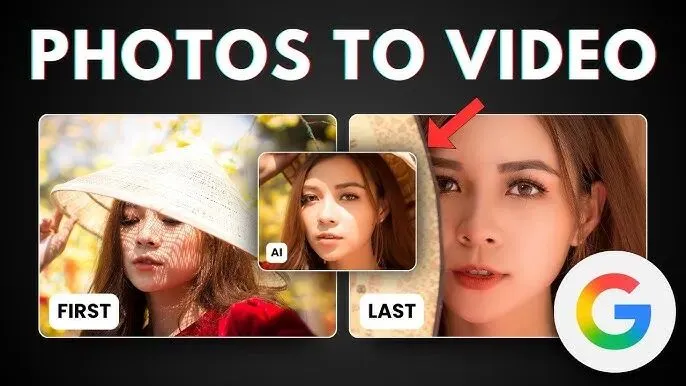
Veo起止帧控制:指定FIRST和LAST两帧图像,Veo自动生成中间的过渡动画
这对于制作有明确起承转合的产品演示短片来说非常实用:只需要准备好"开场画面"和"结尾画面",中间的过渡完全交给 Veo 来完成。
五、两个典型的 Agent 工作流
案例一:品牌 UI 设计智能体
任务目标:根据给定的品牌指南(Brand Guidelines),自动生成符合品牌调性的 App UI 界面图。
工作流设计如下:
Agent 读取包含品牌色彩、字体、Logo 规范的 PDF 文档;
调用 Nano Banana Pro 模型生成初版 UI 设计图;
调用 Gemini 1.5 Pro 作为裁判,检查生成的 UI 图是否使用了正确的品牌色、Logo 位置是否正确;
如果裁判发现色彩偏差,将具体的 RGB 值错误反馈给生成模型,强制其在下一轮迭代中修正;
最终输出一张完美契合品牌规范的高保真 UI 图。
这个工作流的核心价值在于:它将原本需要设计师反复沟通确认的品牌合规检查,完全自动化了。
案例二:多场景讲解视频 Agent
任务目标:制作一段包含多个场景切换、且带有同步语音解说的科普视频。
工作流分为四个阶段:
剧本规划:Agent 先使用 LLM 编写分镜剧本和解说词;
生成参考帧:为每个场景生成关键帧图像,确保整体画风一致;
视频生成与音频同步:使用 Veo 模型将参考帧转化为动态视频,并生成原生同步的音频;
时间一致性评估(Temporal Consistency):Agent 评估场景 A 切换到场景 B 时,人物和环境是否发生了不合理的突变,如果不合理,则退回重做。
六、动手实践:用 Gemini CLI 快速搭建第一个媒体 Agent
想搭建这样一套系统,可以从 Gemini CLI入手。这是 Google 提供的一个终端工具,支持通过自然语言指令直接构建、测试和迭代生成式媒体应用。
Gemini CLI终端界面:通过自然语言指令驱动Agent完成任务,支持MCP工具接入
Gemini CLI 对 MCP(Model Context Protocol)提供了原生支持,可以将 Nano Banana、Veo、Lyria 等媒体生成工具直接接入,用自然语言驱动整个媒体生成工作流,而不需要从头编写大量样板代码。
对于个人 Google 账户,Gemini CLI 提供了相当慷慨的免费配额:每分钟 60 次请求、每天 1000 次请求,足够用来搭建和测试一个完整的媒体 Agent。
小结
从单纯的"提示词魔法"走向"工程化的 Agent 系统",是视觉生成技术真正走向工业化的必经之路。
Generate → Evaluate → Iterate 这三个齿轮咬合在一起,构建出的不再是一个随机出图的玩具,而是一条真正能为业务创造价值的自动化视觉生产线。
如果你也受够了毫无尽头的"盲盒式抽卡",这套方法论值得一试。把生成质量的控制权从运气手里夺回来,AI 视觉生成的天花板,比你想象的要高得多。
