 夜雨聆风
夜雨聆风【AI认知】是我和大家一起学习 AI 的长期专栏。
我们从基础概念开始,一点点看懂 AI 的底层逻辑和现实应用,慢慢搭起一张 AI 世界地图。
AI认知003导图🗺️
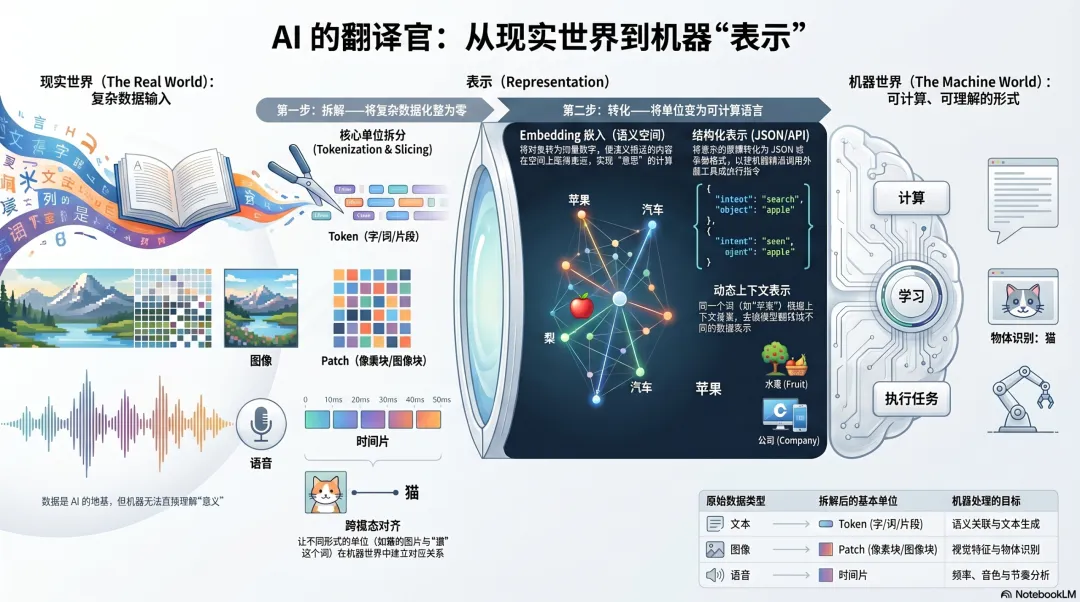
数据提供经验,但机器不能直接处理人类世界里的“意思”→ 表示,就是把信息转成机器能处理的形式→ 不同数据要先被拆成基本单位文本可以切成 Token,图像可以切成图像块,音频可以切成时间片→ 这些单位会被转成向量,也可以被转成 JSON、函数参数、API 调用格式→ Embedding 是把对象放进向量空间,让相似和相关可以被计算→ 好的表示,能保留有用关系;差的表示,会丢失或混淆关系→ 上下文会改变表示,同一个词在不同语境里不该被固定理解→ 多模态表示,让文字、图片、声音、视频之间可以互相对齐
上一篇我们讲了数据。
数据是 AI 能力的第一块地基,它决定模型接触过怎样的世界,也决定模型能从中学到什么经验。但有了数据,还不等于机器就能学习。
人看到一句话,可以直接理解大概意思;看到一张图片,可以知道里面有一只猫、一辆车、一个人;听到一段语音,可以分辨语气、停顿和情绪。机器不是这样工作的。机器不能直接处理“意思”,它只能处理数字、结构、规则、概率和运算。
所以,在数据和模型之间,还需要一层转换。
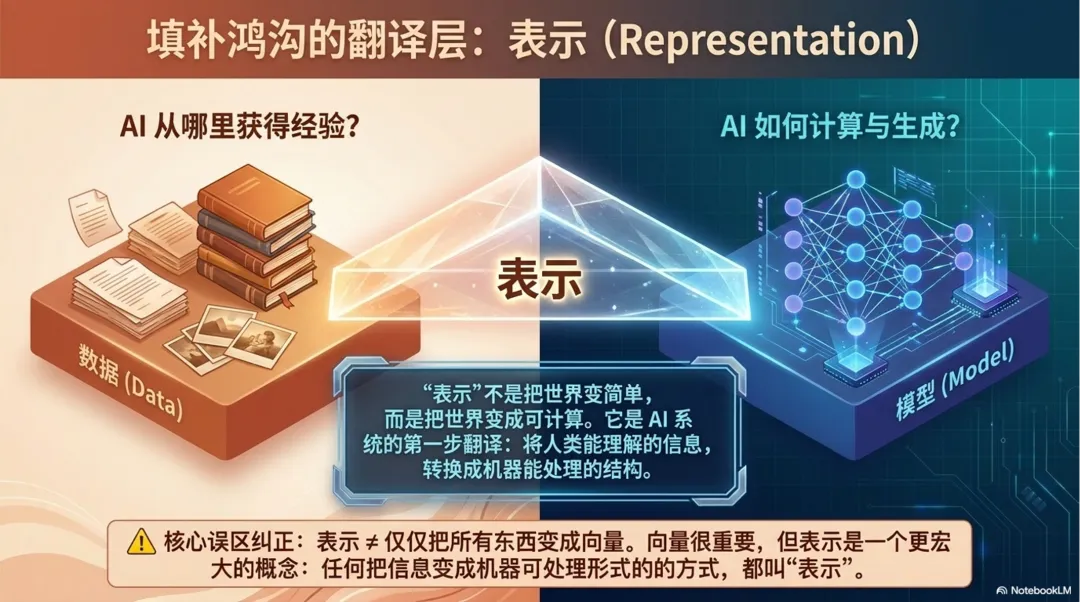
这一层就叫:表示。
如果说数据回答的是“AI 从哪里获得经验”,那么表示回答的是:这些经验怎样变成机器可以处理的形式?
01|表示不是把世界变简单,而是把世界变成可计算
表示,简单说,就是把信息转换成机器能处理的形式。
这句话听起来很普通,但它是理解 AI 的一个关键入口。
因为人类世界里的信息,本来不是为机器准备的。一句话里有字面意思,也有上下文;一张图片里有颜色、轮廓、物体、位置关系;一段声音里有音高、节奏、停顿、语气。人可以凭经验直接理解这些东西,机器必须先把它们转成可以计算的结构。
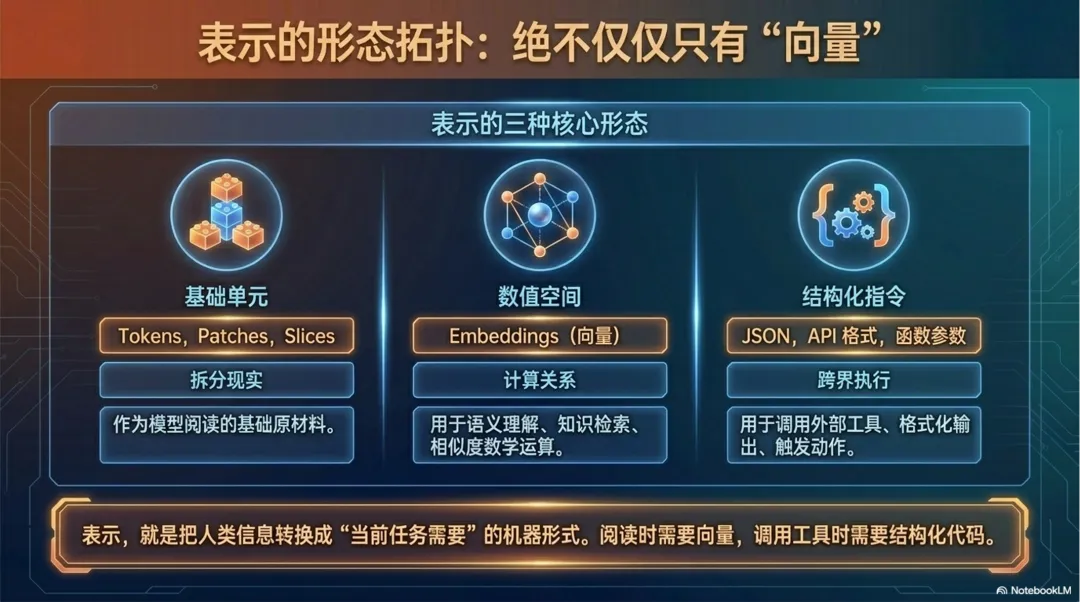
这里要先避免一个误解:表示不等于“把所有东西都变成向量(我们后面说)”。向量是非常常见、也非常重要的一种表示方式,尤其在语言理解、语义检索、图像识别里经常出现。但表示这个概念更大,它指的是任何一种“把信息变成机器可处理形式”的方式。
比如,文本进入模型时,通常先被切分成 Token 序列,再通过嵌入层映射为向量表示;用户意图可以被表示成 JSON;调用工具时,可以被表示成函数参数或 API 调用格式。它们看起来形式不同,但本质一样:都是把人类能理解的信息,转换成机器能处理的东西。
所以这一篇讲“表示”,不是只讲一个技术名词,而是讲 AI 系统里非常基础的一步:机器要先把世界翻译成自己的语言,后面才谈得上学习、理解、生成和行动。

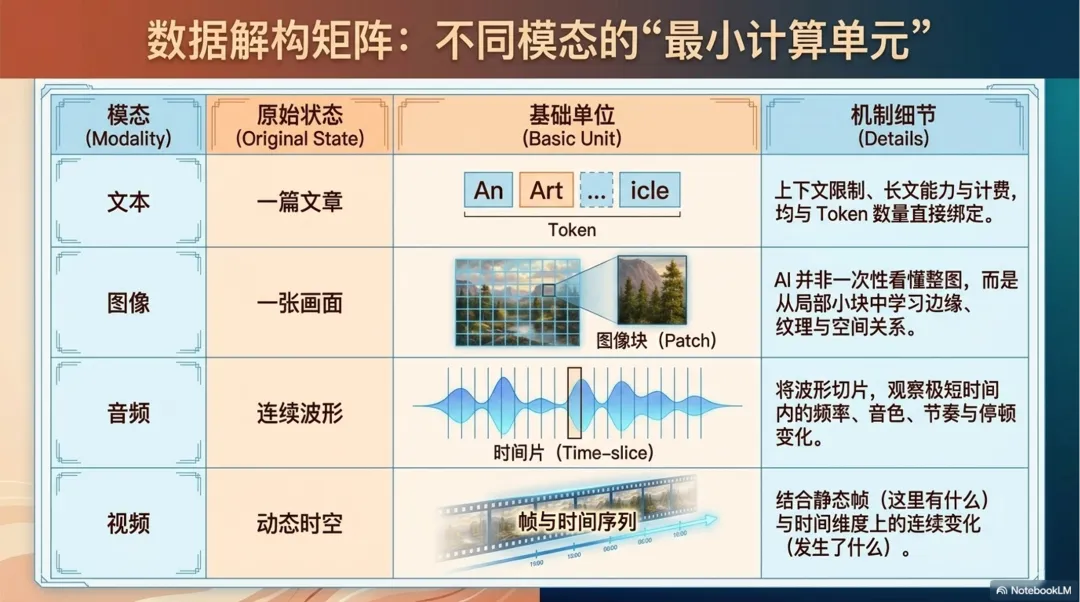
在文本里,这个单位通常叫 Token。Token 可能是一个字、一个词,也可能是一个常见片段。大语言模型看到的不是“一篇文章”这个整体,而是一串 Token 序列。上下文长度、长文处理、输出截断、模型计费,很多都和 Token 数量有关。
图像也需要切分。常见做法是把图像拆成像素块,或者更适合模型处理的图像 patch。一张图片不是被模型一次性“看懂”的,而是被分解成许多局部区域,模型再从这些局部区域里学习边缘、纹理、形状、物体和空间关系。
音频则要按时间切。声音是连续变化的波形,模型需要把它拆成很短的时间片,观察不同时间片里的频率、音色、节奏、停顿和语调。
视频更复杂,它既有一帧一帧的图像,又有时间上的连续变化。单张画面只能告诉模型“这里有什么”,连续帧之间的关系才能告诉模型“发生了什么”。
所以,Token 只是文本切分的一种形式。更一般地说,表示的第一步,是把复杂数据拆成机器可以处理的基本单位。不同类型的数据,切分方式不同,但目标一致:先把混成一团的信息,拆成可以计算、比较、组合的小块。

03|第二步:把这些单位变成机器能计算的形式
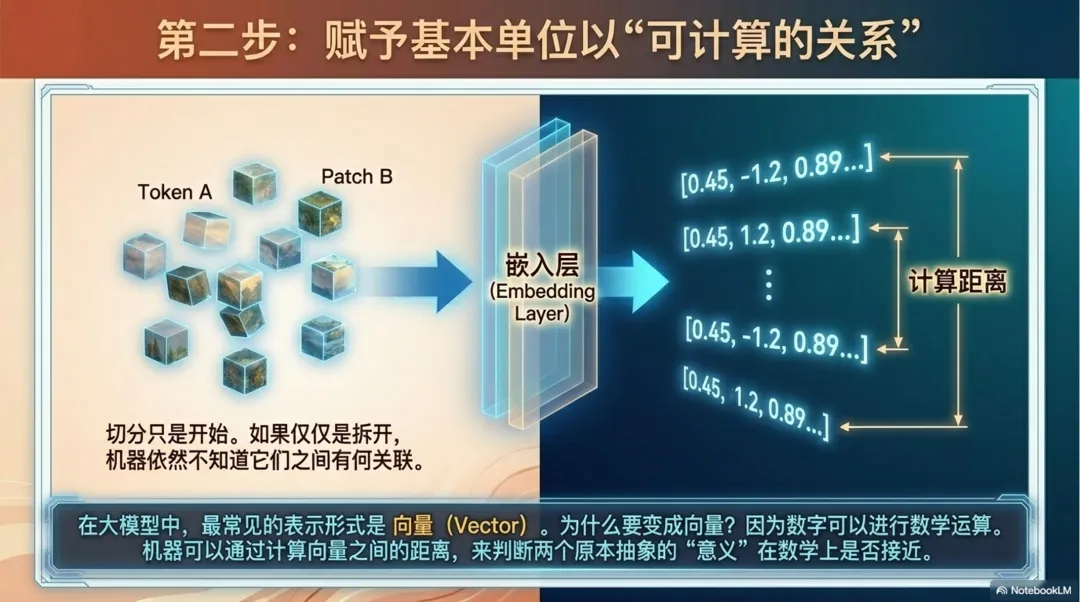
切分只是开始。Token、图像块、音频片段这些单位,如果只是被拆出来,机器仍然不知道它们之间有什么关系。接下来,还要把它们转换成更适合计算的形式。
在大模型里,最常见的一种形式就是向量。向量可以先理解成一组数字。一个 Token、一段文字、一张图片、一个文档,都可以被转换成一组数字,用来表示它在模型里的某种位置和特征。
为什么要变成向量?因为向量可以计算。机器可以计算两个向量之间的距离,可以比较它们是否接近,可以把它们放进模型里继续运算。这样,原本很难直接处理的“意义”,就变成了可以参与计算的关系。
不过这里也要再次强调:向量不是唯一的表示形式。向量适合表达语义相似、特征关系和模式结构;但当 AI 要调用工具时,表示可能会变成另一种样子。
比如你说:“帮我查一下明天北京天气,然后整理成一句话。”系统要把这句话转换成机器能执行的结构:调用天气工具,地点是北京,时间是明天,输出格式是一句话。这里的表示可能就是 JSON、函数参数或 API 调用格式。
所以,表示不是只有“转向量”这一条路。更准确地说,表示就是把信息转换成当前任务需要的机器形式。理解语言时,常常需要向量;调用工具时,常常需要结构化参数;检索资料时,可能需要向量和关键词一起用。
这也是表示这个概念容易被讲窄的地方。它不是某一种格式,而是一层转换:把人类的信息,变成机器能继续处理的信息。
04|Embedding:把对象放进可以比较关系的空间
现在我们再来看一个常见词:Embedding,中文常翻译成“嵌入”。
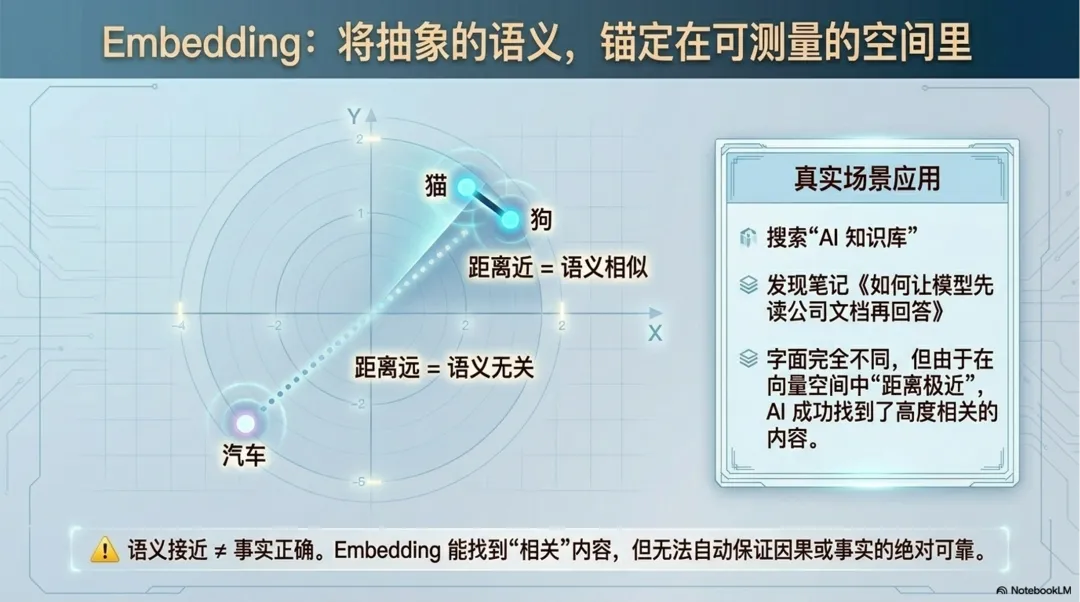
如果前面讲的是“信息可以被转成向量”,那么 Embedding 更进一步讲的是:把对象放进一个向量空间里,让对象之间的关系也能被计算。
举个简单例子。如果只是编号,“猫=001,狗=002,汽车=003”,机器只知道它们是三个不同对象,却不知道“猫”和“狗”比“猫”和“汽车”更接近。但如果通过 Embedding 把它们放进向量空间里,语义上接近的东西可以距离更近,语义上差得远的东西可以距离更远。
这就让很多事情变得可能。
比如你在知识库里搜“AI 知识库”,有一篇笔记标题叫“如何让模型先读公司文档再回答”。这篇笔记没有出现“知识库”三个字,但它讲的内容和“AI 知识库”很接近。如果系统把你的问题和文档内容都做成 Embedding,就可以通过向量距离找到这类语义相关的资料。
所以 Embedding 的重点不是“又把数据变成了一组数字”,而是让相似、相关、主题、类别这些关系进入可计算空间。它解决的是:机器怎样判断两个内容虽然字面不同,但意思接近。
不过,Embedding 也不能被神化。语义接近不等于事实正确,相关不等于因果,相似不等于可以直接替代。它能帮助系统找到相关内容,但不能自动保证内容真实可靠。
这一点后面讲知识库和 RAG 时会非常重要:向量检索能帮 AI 找到“可能相关”的资料,但最终是否准确,还要看资料质量、引用方式和生成过程。
05|表示质量:保留下来的关系,决定模型能学到什么
到这里,我们已经知道:数据要先被切分,再转成机器能处理的形式,很多时候还会通过 Embedding 进入向量空间。接下来的问题是:是不是只要转完就行?
不是。
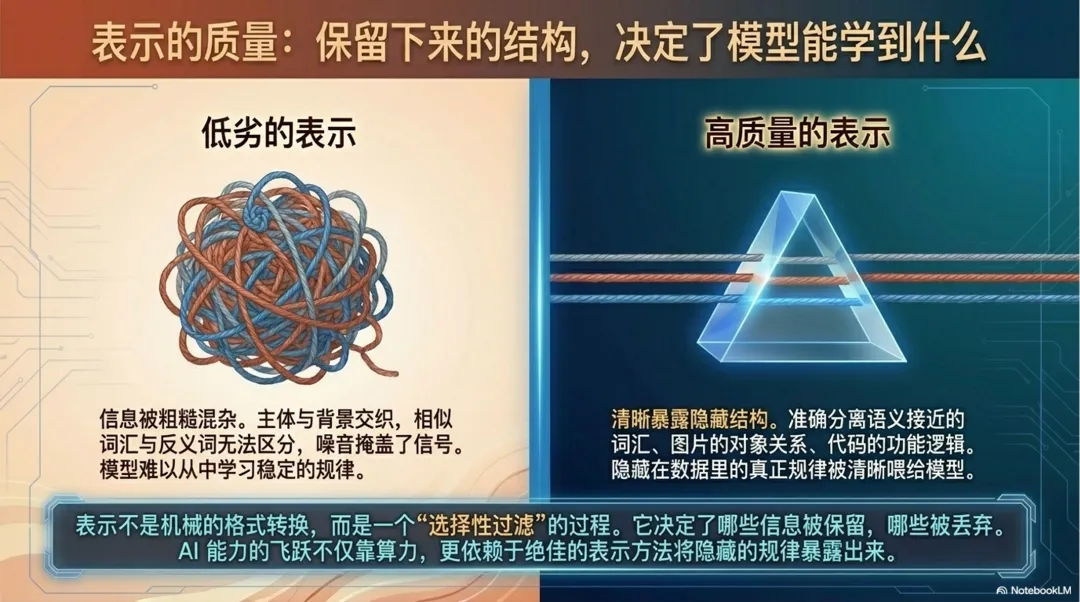
表示的质量非常关键。因为表示不是机械地把东西换个格式,而是在决定哪些信息被保留,哪些信息被压缩,哪些信息被丢掉。
如果表示太粗糙,原本不同的东西可能被混在一起。比如两个词字面相近,但含义完全不同;两个句子说法不同,但意思其实接近;一张图片里主体和背景混在一起;一段声音里内容和噪音缠在一起。表示如果处理不好,模型后面就很难学出稳定规律。
好的表示应该尽量保留有用关系。它能让模型看出词语之间的语义接近,句子之间的主题关联,图片区域之间的对象关系,音频片段之间的节奏变化,代码片段之间的功能相似。
这就是为什么 AI 能力提升不只靠更多数据和更大模型,也靠更好的表示方法。数据里本来有关系,但如果表示方式看不见这些关系,模型就很难学到。反过来,一个好的表示方式,会把隐藏在数据里的结构更清楚地暴露出来。
所以,表示质量影响的不是表面格式,而是模型能不能从数据里抓住真正有用的规律。
06|表示不是固定的,上下文会改变意义
前面为了方便理解,我们好像在说:一个词可以被转成一个向量,一个对象可以被放进一个空间。但真正进入大模型时,表示并不是永远固定的。
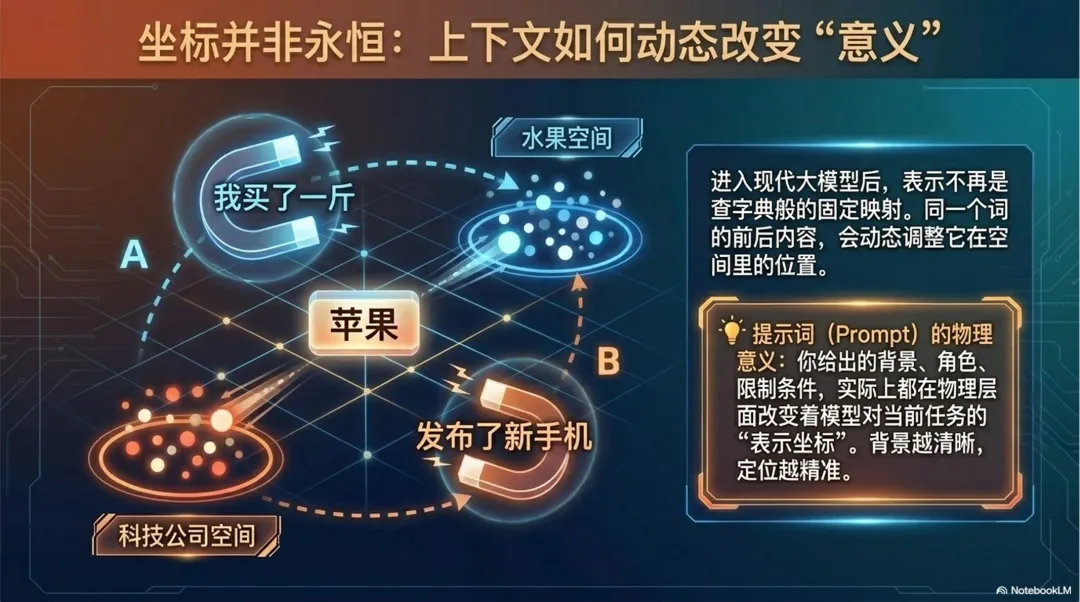
同一个词,在不同上下文里,意义会变。
比如“苹果”出现在“我买了一斤苹果”里,多半是水果;出现在“苹果发布了新手机”里,多半是公司。同一个词,如果永远只有一个固定表示,就很难处理这种变化。
现代大模型强的地方之一,就是它会根据上下文动态调整表示。
一个词前后出现了什么内容,会影响它当前应该被理解成什么。不是先查一本固定词典,再机械套用解释,而是在当前上下文里重新确定它的位置和作用。
这也是为什么 Prompt提示词 会影响输出。你给模型的背景、角色、任务、材料、限制条件,其实都在影响模型对当前问题的表示。背景越清楚,模型越容易把问题放到正确的语义空间里;背景越混乱,它就越容易误解任务。
这里先不展开模型结构。只需要先记住一点:现代大模型之所以能动态调整表示,和后面要讲的注意力机制有关。等下一篇讲模型结构时,我们再看它是怎么做到的。
这一节先建立一个概念:表示不是固定的。同一个词、同一句话、同一段材料,在不同上下文里,可以形成不同表示。
07|多模态表示:不同形式的信息要能互相对齐
前面主要讲文字。但今天的 AI 已经不只处理文字,还能看图片、听语音、理解视频,甚至把文字、图片、声音放在同一个任务里处理。
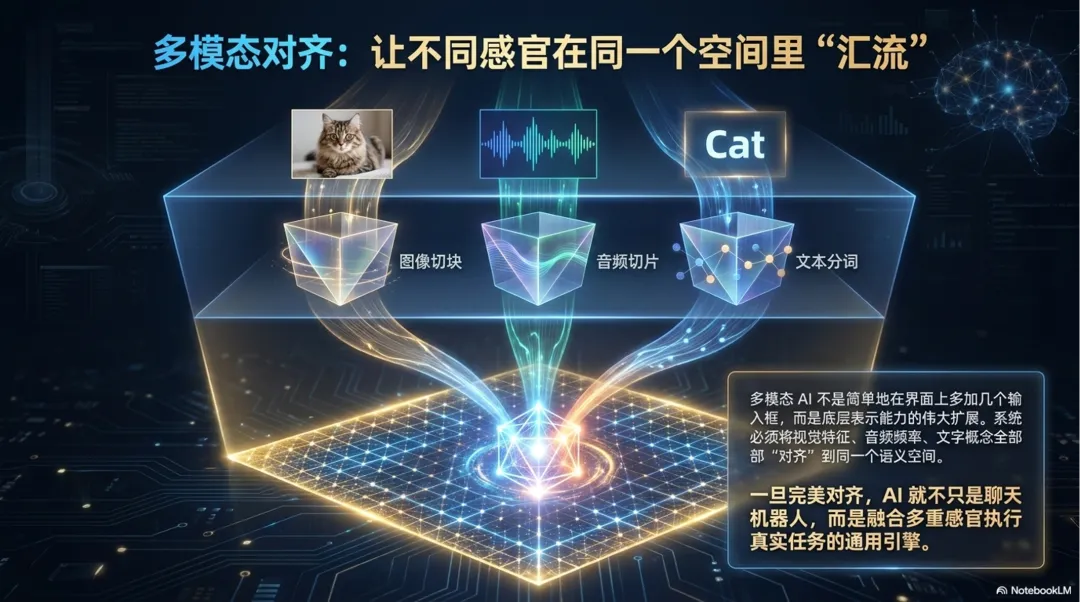
这背后仍然是表示问题。文字有文字的表示,图像有图像的表示,音频有音频的表示,视频还有时间维度上的表示。多模态 AI 的关键,不是简单地多接几种输入,而是让这些不同形式的信息能够互相对齐。
比如你给 AI 一张猫的图片,再问“这是什么动物”,系统需要把图像里的视觉特征和语言里的“猫”这个概念对应起来。你让 AI 根据图片写说明,它要从视觉表示转到语言表达。你让 AI 听一段语音并总结,它要先处理声音,再转成语义,再组织成文字。
所以,多模态不是界面升级,而是表示能力的扩展。不同形式的数据先各自变成机器可处理的表示,再通过对齐,让系统知道图片里的对象、语言里的词、声音里的内容、视频里的动作之间有什么关系。
一旦这种对齐做得更好,AI 就不只是“会聊天”。它可以观察图片、理解语音、描述视频、根据屏幕内容执行任务,也可以把不同来源的信息合在一起处理。
这就是为什么多模态能力会改变 AI 产品形态。它让 AI 从文本框里走出来,开始接触更接近真实世界的信息。
08|表示不只发生在模型训练中,也发生在 AI 每次工作时
最后,我们把表示放回整个 AI 系统里看。
表示不是模型训练阶段才用一次。模型训练时,数据要先被转换成机器能处理的形式;模型投入使用后,用户问题、知识库文档、搜索结果、工具说明、调用参数,也同样要被转换。AI 每次工作,其实都在经历某种表示过程。
比如知识库检索。系统不是只在文档里找几个关键词,而是会把用户问题和文档片段都转换成表示,再比较它们是否相关。
在真实应用里,系统不只会表示正文内容,也会表示标题、关键词、标签、时间等附加信息。这些信息可以先被单独记录下来,比如标题就是标题,标签就是标签,时间就是时间。只有当它们需要参与模型计算时,才会被转换成模型能够处理的数值形式。它们不是和向量并列的关系,而是同一批信息在不同用途下,会有不同的表示方式。
工具调用也是一样。用户用自然语言说“帮我把这篇文章整理成飞书文档”,系统要理解“这篇文章”指什么,“整理”是排版还是改写,“飞书文档”是云文档还是普通文件,最后还要把这些信息变成工具能执行的参数。
这个过程本质上仍然是表示:把人的意图转换成机器能执行的形式。
所以,不管 AI 是在学习数据,还是在使用资料、调用工具、处理任务,它都需要先把对象转换成机器能处理的形式。这个转换过程,就是我们这一篇讲的“表示”。不用把它说得很玄。表示就是 AI 系统的翻译过程:把人类世界里的内容,翻译成机器世界里能计算、能比较、能调用、能执行的形式。
09|结语
这一篇讲的是能力生成链条的第二层:表示。
数据提供经验,但机器不能直接处理人类世界里的意思。表示的作用,就是把文字、图片、声音、视频、文档、工具和用户意图,转换成机器能处理的形式。所以,表示不是一个单一形式。
为了不把概念混在一起,我们可以先粗略分成几类:一种是切分出来的单位,比如 Token、图像块、音频片段;一种是模型计算用的数值形式,比如 Embedding 这样的向量表示;还有一种是系统交互用的格式,比如 JSON、函数参数、API 调用格式。
它们都和“表示”有关,但解决的问题不一样。
理解表示之后,我们再看 AI,就不会只说“它读懂了文章”、“它看懂了图片”、“它理解了我的意思”。更准确地说,是这些内容先被转换成了某种机器可处理的表示,模型再在这些表示之间计算关系、生成输出。
下一篇,我们继续拆第三层:模型结构。也就是,数据和表示准备好之后,AI 到底需要一个什么样的结构,才能承载这些规律,并最终形成我们看到的能力。
如果文中有不准确或不完善的地方,欢迎大家留言补充。
