 夜雨聆风
夜雨聆风
一、 全球海洋状态估算的技术困境
(一) 海洋建模与预测的核心科学意义
海洋是地球系统的核心要素,从根本上调节全球气候、驱动资源分布并维系各类生态系统运转。精准的全球海洋建模与预测,是理解地球系统运行规律、应对气候变化、保障海洋资源可持续利用的关键基础。然而,当前数值海洋模型的预测能力始终面临双重核心瓶颈:一是初始条件的不确定性,二是多源观测数据量激增带来的计算挑战。
(二) 传统数据同化方法的固有瓶颈
数据同化是通过最优结合观测数据与数值模型来缓解上述局限性的成熟方法,其核心目标是利用观测信息修正模型初始场,提升预测精度。但传统数据同化方法正面临难以突破的规模扩展难题。
1. 计算成本的指数级增长
四维变分法、集合卡尔曼滤波器等主流传统方法,其计算成本会随着模型分辨率的提升呈多项式增长。这导致高分辨率的全球海洋数据同化应用,在现有计算资源下几乎难以实现。同时,这些方法普遍依赖线性动力学假设或高斯误差统计等简化物理模型,无法准确捕捉海洋系统中固有的强非线性动力学复杂性。
2. 数据保真度的不可逆损失
海洋观测数据具有高度异质性,覆盖范围从稀疏的现场剖面测量到高分辨率的卫星条带数据。为应对海量数据带来的计算压力,传统方法在实际应用中通常会对观测数据进行稀疏化或平均化预处理。这种处理方式会不可逆地牺牲宝贵的精细尺度信息,导致数据可用性的增加并未转化为模型性能的相应提升。
(三) 现有深度学习数据同化方案的架构缺陷
深度学习技术的最新进展为克服传统数据同化的局限性提供了新的可能,其在捕捉非线性动态和加速计算方面展现出显著优势。目前,深度学习已在观测算子构建、动态误差协方差估计、在线模型误差校正等数据同化组件增强中取得成功,部分研究甚至展现出完全替代传统数据同化方法的潜力。
然而,绝大多数现有的深度学习数据同化框架存在一个关键的架构缺陷:它们过度依赖卷积神经网络、视觉Transformer等基于视觉的深度学习模型。这类模型要求输入数据必须是均匀规则的网格结构,因此需要对原始异构观测数据进行大量预处理步骤,包括插值或下采样到统一网格。这些预处理过程同样会不可逆地丢弃高频信息,限制高分辨率传感器的效能发挥。此外,训练这类视觉模型需要消耗大量图形处理单元内存,严重制约了其在高维海洋数据挖掘任务中的可扩展性。
二、 ADAF-Ocean:人工智能驱动的海洋数据同化新范式
(一) 框架核心设计理念
为同时突破计算可扩展性不足与数据保真度下降的双重瓶颈,人工智能驱动的海洋数据同化框架ADAF-Ocean被提出。该框架从根本上重构了数据同化的技术范式,其核心设计理念是无需任何插值或降质预处理,直接处理原始、异构、多尺度的海洋观测数据。
ADAF-Ocean的核心目标是通过将稀疏、含噪的观测数据与预测模型得出的背景场相结合,重建全球海洋域内任意目标位置的海洋状态变量。同时,该框架通过人工智能驱动的超分辨率技术,能够从粗略的低分辨率背景场中重建高分辨率的中尺度动力学过程,在保证计算效率的前提下实现可扩展性。
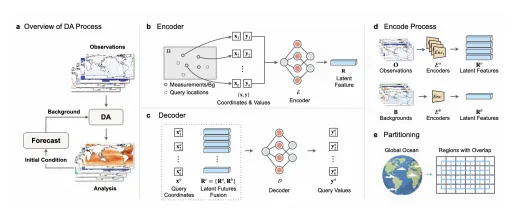
(二) 神经过程启发的编码器-解码器架构
ADAF-Ocean采用受神经过程理论启发的编码器-解码器架构,该架构特别适用于处理不规则、稀疏且多尺度的环境传感器数据。框架选用多层感知机作为核心计算组件,因其结构简单、计算效率高且适应性强,能够将空间坐标和变量值编码为潜在表示,实现卫星影像与现场测量等多源数据的无缝整合,同时完整保留原始观测数据的保真度。
1. 异构数据的专用编码机制
(1) 观测数据与背景场的统一结构化处理
为实现对异构输入的统一处理,稀疏观测数据和网格化背景场在编码前均被转换为组合点向量形式。对于稀疏观测数据,测量值首先与其三角编码坐标相结合;对于网格化背景场,则先在各自网格位置处被采样或展平为离散数据点,再与对应坐标组合。这种结构同质性设计,使得框架能够以统一的方式处理不同来源、不同格式的输入数据。
(2) 多源数据的独立编码与特征融合
框架包含一组专门设计的编码器,分别用于处理不同类型的观测数据和背景场。虽然所有编码器都基于相似的多层感知机架构,包含深度线性层、激活函数和跳跃连接,但它们的输入层经过专门定制,第一层的维度被调整以匹配对应数据源中的特定变量数量。
不同来源的观测数据通过各自的专用编码器转换为潜在特征,背景场也通过独立的编码器编码为包含空间和物理上下文信息的潜在特征。这些潜在特征随后被整合为单一的融合表征,输入到解码器中进行最终的状态估计。
2. 支持超分辨率的解码机制
解码器负责执行最终的海洋状态估计,并驱动分辨率增强过程。解码器接收三个输入:目标查询坐标、所有观测数据的独立潜在特征以及背景场的潜在特征。通过学习连续的非线性映射关系,解码器能够在任意指定的经纬度坐标处预测对应的海洋状态分析变量。
通过在高分辨率网格上查询目标坐标,该架构本质上实现了超分辨率能力。解码器能够直接预测分析增量,在目标高分辨率处实现高频误差校正,从而从低分辨率背景场中重建出高分辨率的海洋分析场。
(三) 全球尺度可扩展的工程化设计
为高效处理全球尺度的高维海洋数据,ADAF-Ocean采用了一系列工程化设计,确保框架能够在有限计算资源下实现全球高分辨率海洋状态估算。
1. 重叠分区计算策略
ADAF-Ocean将全球海洋划分为多个重叠的子区域(斑块)进行并行计算。这种重叠设计对于确保边界区域被完整捕获、避免区域间断至关重要。
分区策略的核心优势在于将瞬时图形处理单元内存占用与全局域总规模解耦。若不进行分区处理,处理整个全球域需要同时加载所有输入张量,这在计算上几乎不可行。通过分区,图形处理单元内存需求仅取决于单个区域的大小,而非全局域的规模,使得模型能够扩展至任意高分辨率,而不会增加瞬时内存需求。此外,分区策略还实现了隐式数据增强:将单一全局状态分割为多个重叠区域,每个区域都作为独立的训练样本,极大扩展了训练数据集,使模型能够从相对较短的时间序列中学习。
2. 地理空间位置的三角编码方法
多层感知机本身并不具备感知空间位置的能力。为了整合地理空间信息,框架通过三角函数变换将经纬度坐标编码为连续、循环且标准化的表示形式。这种编码方式能够保留地理空间坐标的循环特性,例如经度的周期性,同时提高训练过程的数值稳定性。
通过将分区策略与三角定位编码相结合,模型可以在全球域的任意子集上构建场预测。这种灵活性显著降低了计算需求,因为预测可以分块生成,而非一次性处理整个全球域。
三、 ADAF-Ocean的性能验证与关键发现
(一) 多源数据同化的整体性能评估
为验证ADAF-Ocean对多样化观测数据源的全面同化能力,研究采用了六类多源观测数据,并设计了严格的对比实验进行性能评估。
1. 实验设计与对比配置
(1) 数据集与训练验证划分
研究采用高分辨率GLORYS(全球海洋再分析与模拟系统)再分析产品作为基准数据,该产品基于欧洲海洋模型核心构建,原生空间分辨率为1/12度。研究重点关注五个关键海表变量:温度、盐度、纬向速度、经向速度和海面高度,所有变量均经过时间聚合处理,达到日尺度分辨率。
研究整合了六类多源观测数据,包括基于卫星的测量和现场测量。卫星观测数据包括4公里分辨率的海表温度、25公里分辨率的海面盐度、25公里分辨率的海面风、100公里分辨率的海冰浓度以及25公里分辨率的海平面异常;现场测量数据来自船舶、浮标和剖面浮标的稀疏点状表层及次表层温度和盐度测量值。
模型以深度学习海洋预报模型Triton的3天预报场作为背景数据进行训练,目标数据为GLORYS再分析结果。训练使用2018年数据,验证采用2019年数据,测试则使用2020年数据,同化过程每日执行一次。
(2) 三组对比实验的设置逻辑
为全面评估ADAF-Ocean的性能,研究设计了三种实验配置:
第一种配置为ADAF-Ocean-Full,利用框架有效整合多源多分辨率数据的能力,对原始空间分辨率的观测数据进行同化处理,用于凸显同化高分辨率观测数据的优势。
第二种配置为ADAF-Ocean-Thinned,将同化后的观测数据预处理为统一的1度分辨率,用于对比不同数据预处理方式对模型性能的影响。
第三种配置为ADAF-Thinned,采用现有深度学习框架对相同1度分辨率数据进行同化,作为稳健的基线对比,用于证明ADAF-Ocean在处理多源数据方面相较于现有深度学习数据同化方法的优越性。
2. 核心性能指标表现
研究采用地球物理数据分析中常用的三项关键指标评估模型性能:纬度加权均方根误差、平均绝对误差及纬度加权异常相关系数。
(1) 异常相关系数与均方根误差的全局提升
采用原始保真度同化观测数据的ADAF-Ocean-Full配置,通过规避数据退化预处理始终在所有地表变量上实现最高的异常相关系数提升和更优的均方根误差降低。其中,温度和海面高度的异常相关系数改进幅度超过6%,显著优于其他配置。
盐度变量呈现出独特现象:虽然ADAF-Ocean-Full配置显示出最高的异常相关系数改进,表明其空间模式相关性更优,但其绝对均方根误差的降低幅度相对较小。这种差异源于ADAF-Ocean-Full配置在增强盐度场与参考数据的空间相关性的同时,仍保留了局部变异性,从而略微限制了绝对误差的整体降低。
(2) 误差降低的季节性与空间异质性
ADAF-Ocean-Full的月平均纬度加权均方根误差在所有变量上均持续低于背景值。其中,海面高度的均方根误差降幅最大,约为18%;盐度的降幅最小,约为5%。
误差降低效果存在显著的季节性变化规律。温度、海表温度和海面高度的改进效果在7月至12月达到峰值,这表明夏季和秋季更密集的卫星热数据对密度驱动变量的约束更有效;而速度分量的改进效果在1月至5月达到最大值,这表明当风强迫通常最强时,其优化效果最佳。
网格点平均绝对误差降低率在温度、盐度、纬向速度、经向速度和海面高度区域分别达到85%、68%、93%、95%和80%。不同区域的改善效果存在明显空间异质性:温度区域的改善效果在北极和南极最为显著;海面高度在黑潮区域表现出明显提升;纬向速度和经向速度在全球海洋范围内的改善幅度均超过90%,其中北太平洋区域因动力学约束条件特殊,其改善效果最为突出。
(3) 不同观测数据的贡献度差异
研究通过系统评估排除特定观测数据对平均绝对误差的影响,量化了不同类型观测数据的贡献度。结果凸显了卫星观测,特别是海表温度、海面风和海面盐度,在提升海洋状态估算精度中的关键作用。
基于卫星的海表温度观测对改善温度估算贡献最大,尤其在黑潮和墨西哥湾流等西部边界流中。对于盐度,卫星海面风观测的影响最为显著,特别是在西太平洋地区,这是因为海面风驱动着海洋环流、蒸发与降水、表层混合以及淡水通量的再分配等关键物理过程,这些过程都会影响海面盐度。
基于卫星的海面风观测对表层洋流的改善最为显著,北印度洋、北太平洋和南大洋的观测数据均有明显提升,充分说明风力在驱动表层洋流和塑造全球环流格局中起着关键作用。就海面高度而言,卫星海面盐度观测数据影响最为突出,几乎所有海域都呈现明显改善,其中北极洋的提升尤为显著,这凸显了盐度对海洋密度和海平面变化的决定性影响。
海平面异常数据呈现出微妙的发现:敏感性分析显示海平面异常是维持地转平衡的主要约束条件,但贡献度测试却将其独特贡献度列为次要。这种差异凸显了测量维度的不同,即影响力与不可替代性的对比。海平面异常信息存在部分冗余,框架通过海表温度、海面盐度和海面风的约束,能够隐含地从密度和风驱动动力学中推导出海平面分量。
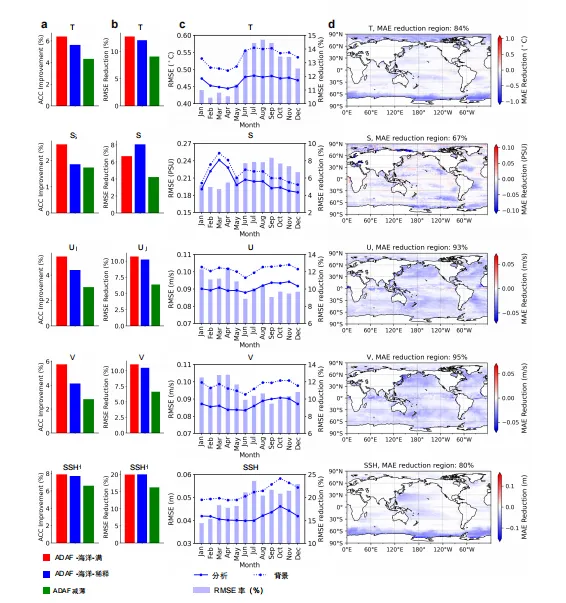
图1 多源数据同化性能对比
(二)AI驱动超分辨率重建的物理保真度验证
高分辨率海洋建模能显著提升海洋状态的逼真度,这就需要有效的高分辨率数据同化技术。ADAF-Ocean实现了人工智能驱动的超分辨率重建,能够从粗略的1.0度背景生成0.25度分辨率的分析场。
1. 高分辨率重建的技术实现路径
为训练超分辨率能力,研究采用高保真度0.25度GLORYS再分析作为真实目标。
ADAF-Ocean的深度学习模型学习到一个连续的数据同化算子,该算子可直接预测分析增量,从而在目标0.25度分辨率处实现高频误差校正。
这种高保真重建仅需2800万参数,较传统1.0度数据同化所需的2700万参数仅有微小提升,与传统数据同化方法通常需要的计算规模形成鲜明对比。
2. 功率谱密度分析的物理一致性验证
功率谱密度分析为ADAF-Ocean的物理重建能力提供了关键证据。与线性插值法急剧衰减的功率谱密度曲线相比,ADAF-Ocean的功率谱密度曲线在高波数区域更接近真实GLORYS谱。这种收敛性证实了ADAF-Ocean能有效捕捉并重建与中尺度及亚中尺度涡旋相关的能量级联,而这些物理特征完全被线性插值法丢失或失真。
3. 高动态区域的精细结构重建效果
为验证ADAF-Ocean在精细尺度重建中的能力,研究将其性能与应用于1.0度次数据分析的统计线性插值法进行对比,并聚焦于高度动态的黑潮区域进行案例研究。
总体而言,ADAF-Ocean在多数变量上均展现出更优的性能,其平均绝对误差低于线性插值法。在黑潮区域内,ADAF-Ocean捕捉到更精细的海洋结构并显著降低误差:温度的平均绝对误差降低区域占比为51%,盐度为48%,流速为53%,海面高度为58%。
流速场和海面高度场的高保真重建效果尤为明显,线性插值法会严重衰减这些区域的中尺度涡旋。虽然ADAF-Ocean在温度和盐度场的局部平均绝对误差略高于线性插值法,但这是由于线性插值法无法在复杂的陆海边界附近生成有效值,而ADAF-Ocean在这些具有挑战性的区域能够重建细节而非省略它们。
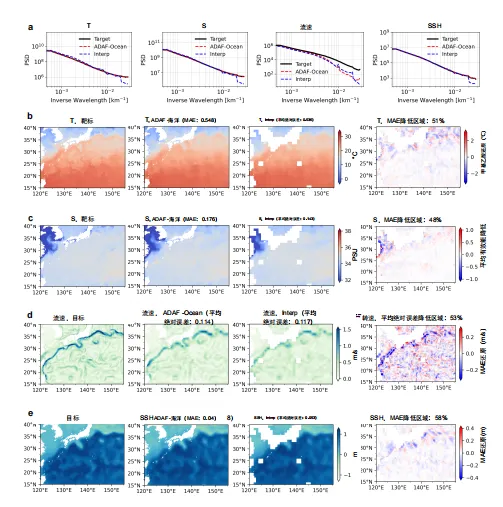
图2 超分辨率重建效果对比
(三) 海洋预报精度的提升效果
数据同化的主要目标是提供精确的初始条件以提升预报精度。为评估ADAF-Ocean生成分析的有效性,研究采用基于深度学习的预报模型进行了27天全球预报。
1. 预报验证实验设计
研究通过比较三种初始条件下的预报性能:ADAF-Ocean-Full生成的分析、ADAF-Ocean-Thinned分析和ADAF-Thinned分析。使用GLORYS初始条件的3-30天预报作为基准,该基准未进行数据同化。
2. 预报时效与精度的量化提升
所有三种数据同化初始化配置均较基准方案展现出显著的预测能力提升。它们实现了初始均方根误差的大幅缩减,其中温度最高降低15%,海面高度最高降低21%。
ADAF-Ocean-Full始终显著优于两种数据稀释配置,该方法在初始分析状态时展现出最大均方根误差缩减幅度,表明其改进效果达到最优。值得注意的是,ADAF-Ocean-Thinned相较于ADAF-Thinned仍保持稳定优势,尤其在温度、纬向速度等变量上表现突出,这凸显了ADAF-Ocean框架本身的卓越能力,即使在处理相同稀疏数据时也是如此。
虽然所有数据同化方法的技能优势都会自然衰减,但ADAF-Ocean-Full度、纬向速度和海面高度上仍保持着最显著且持久的优越性,所有变量的预测优势持续至少20天。对于经向速度,三种数据同化方法的技能水平在约10天后趋于一致。
3. 典型区域的预报偏差分析
研究分析了一个以ADAF-Ocean-Full初始条件为基准的代表性15天预测案例,其结果与GLORYS参考目标基本吻合。
对于海表温度和流速,两种初始条件的空间分布偏差相似,表明预测精度相当。然而,以ADAF-Ocean-Full分析为基准的温度和海面高度预测,在高纬度地区的误差比GLORYS基准更大。这直接归因于这些极地区域ADAF-Ocean-Full初始条件本身已存在的较大初始误差。
四、 技术范式革新与未来研究方向
(一) 对地球系统数据同化领域的范式突破
ADAF-Ocean通过直面计算规模与观测数据保真度的双重挑战,实现了地球系统数据同化领域的范式革新,这一挑战长期制约着全球高分辨率建模的发展。
1. 计算效率的数量级提升
ADAF-Ocean用单次轻量级前向推断流程取代了传统方法的迭代式高成本优化,大幅降低计算成本。实现全球0.25度精度分析仅需求解包含2800万参数的系统,其计算规模比基于数值天气预报的数据同化系统所需的庞大线性代数运算规模级。通过整合纯深度学习预测模型,该框架进一步构建了计算效率极高的预测系统。
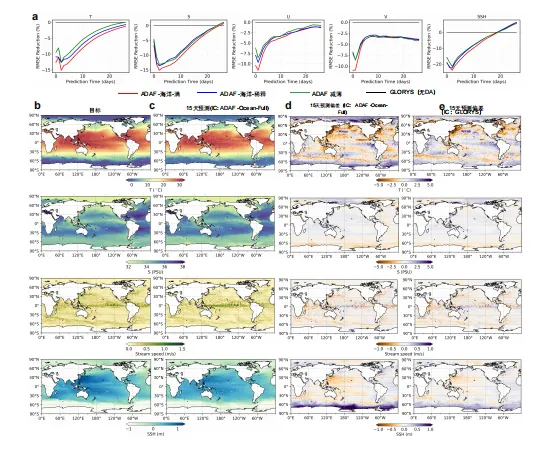
图3 计算效率对比
2. 数据保真度的根本性保障
与先前未能解决数据保真度危机的深度学习数据同化方法不同,ADAF-Ocean中受神经过程启发的架构天生具备处理观测数据不规则性的能力。通过将原始多源多尺度数据转化为潜在空间,框架消除了插值和数据稀疏化的必要性,极大提升了观测网络的信息承载能力。
3. 观测网络优化的科学支撑
ADAF-Ocean通过数据驱动的高效方法,能够评估各类观测数据的贡献度,从而为优化全球海洋监测网络提供可操作性见解。通过量化不同观测数据在不同区域的贡献差异,研究为推进数据同化框架和提升全球海洋估算能力奠定了基础。
(二) 当前研究的局限性
当前研究主要聚焦于海洋表面变量,尚未有效同化原位平台的垂直剖面数据,这限制了其对海洋深层状态的评估能力。此外,虽然基于人工智能的高波数频谱重建已展现出对动力学过程的强隐式捕捉能力,但框架尚未直接将质量、热量或动量平衡等物理约束条件纳入损失函数,分析结果的物理一致性仍有提升空间。同时,当前框架仅能同化海洋观测数据,尚未实现海洋与大气观测数据的同步同化。
(三) 未来核心研究方向
未来研究将从三个核心方向推进ADAF-Ocean的发展:
第一,将框架扩展至有效同化原位平台的垂直剖面数据,实现对海洋深层状态的准确评估,显著增强其在气候与生态系统建模中的应用价值。
第二,在新一代ADAF-Ocean中直接将质量、热量或动量平衡等软物理约束条件纳入损失函数,确保分析结果的物理一致性。
第三,开发全耦合框架,同步同化海洋与大气观测数据,如风应力和表面热通量,显著提升对热带气旋或厄尔尼诺事件等复杂耦合现象的表征能力。
来源: Yanfei Xiang, Yuan Gao, Hao Wu, et al. Advancing Efficient and Scalable AI for Ocean State Estimation. arXiv Preprint, 2025, arXiv:2511.06041v1

