 夜雨聆风
夜雨聆风这半年,很多数据团队都会遇到一个问题:能不能做一个 AI 问数工具?
老板想在群里直接问:“上周华东区新客转化为什么下降?”业务希望不用等分析师,自己输入一句话就能拿到图表。技术团队看了几个 Demo,发现大模型确实能根据自然语言生成 SQL,接上数据库之后,似乎很快就能跑出结果。
于是很多项目的第一版设计都很直接:用户提问,大模型生成 SQL,系统执行查询,返回结果,再让模型总结。
这个链路在演示里很漂亮。
但在企业生产环境里,它也很危险。
因为企业问数真正难的,不是让模型写 SQL,而是让它在正确的口径、正确的权限、正确的上下文和可追责的流程里回答问题。
如果这些底座没有补齐,AI 问数上线得越快,风险扩散得越快。
第一件事:不要让自然语言直接撞数据库
自然语言的问题,天然是模糊的。
用户问“本月收入怎么样”,他可能想看 GMV,也可能想看实收,也可能想看财务确认收入。用户问“新客表现”,可能按首次注册算,也可能按首次下单算。用户问“华东区”,可能是销售大区、仓配大区,也可能是行政区域。
如果系统把这句话直接交给模型生成 SQL,模型会选择一个看似合理的解释。但这个解释未必是公司认可的解释。
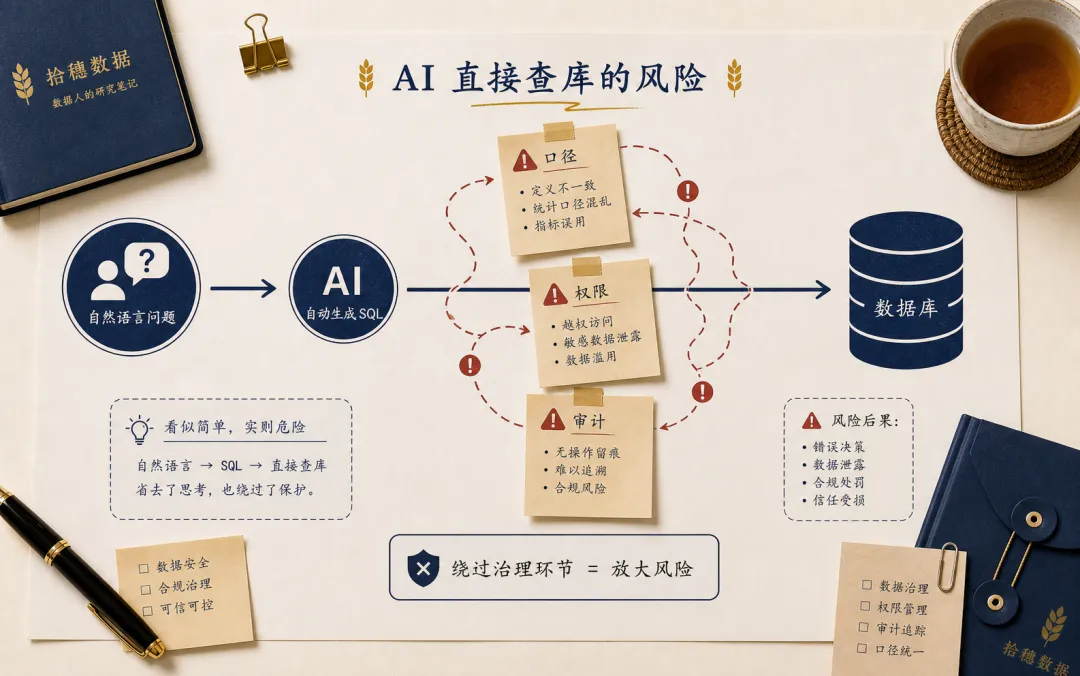
所以企业问数的第一条原则,是不要让自然语言直接撞数据库。
中间必须有语义层。
语义层不是一个时髦词,它的作用很朴素:把业务词和数据资产对应起来。收入是什么指标,新客是什么人群,华东是什么区域口径,订单表和支付表怎么关联,哪些字段可以被外部查询,哪些指标必须使用统一口径。
没有语义层,AI 只是会写 SQL 的实习生,而且是一个非常自信的实习生。
第二件事:指标口径要先有唯一入口
很多团队一上来就训练模型理解指标,其实顺序反了。
如果公司内部本来就没有统一指标入口,模型不可能凭空变出一致口径。它只会在一堆表名、字段名、历史 SQL、文档碎片里猜。
过去一个分析师猜错口径,影响一份报告。AI 问数猜错口径,可能影响几十个人的日常判断。
因此,上线问数 Agent 前,至少要先把高频指标整理出来。
不需要一开始覆盖全部指标。可以先覆盖 20 个最常用的经营指标:GMV、订单数、支付转化率、新客数、复购率、客单价、退款率、履约时长、库存周转、线索转化等。每个指标写清楚定义、计算逻辑、适用场景、时间粒度、负责人和禁用口径。
这一步不性感,但非常关键。
AI 问数不是绕开指标治理,而是倒逼指标治理。
第三件事:权限不是表级那么简单
传统数据权限常常按表、库、字段来控制。谁能查订单表,谁能看用户手机号,谁能导出明细。
AI 问数会让权限问题变复杂。
因为用户不是直接写 SQL,而是通过自然语言请求结果。模型可能组合多个字段,生成中间推断,再用自然语言表达出来。即使它没有直接展示敏感字段,也可能在回答里泄露敏感信息。
比如销售只能看自己区域的数据,但他问“全国高价值客户最近流失原因”,系统如果没有做权限过滤,就可能返回超出权限范围的聚合结果。再比如某些人不能看客户等级,但模型在解释中说“高净值客户流失明显”,也可能越界。
所以权限要从“能不能查表”升级为“能不能问这个问题、能不能看这个粒度、能不能看到这个解释”。
企业问数 Agent 至少要有三层权限:数据范围权限、指标访问权限、结果展示权限。
第四件事:所有查询都要可审计
当 AI 生成 SQL 后,系统必须记录它做了什么。
谁问的?原始问题是什么?模型解释成了什么指标?生成了什么 SQL?查了哪些表?扫描了多少数据?返回了什么结果?有没有人工确认?最后答案发给了谁?
这些记录看起来像合规要求,其实也是产品质量要求。
没有审计,就无法复盘错误。用户说“AI 昨天给我的数不对”,你不知道它当时用了什么口径,也不知道是不是权限过滤出了问题,更不知道模型有没有改写问题。
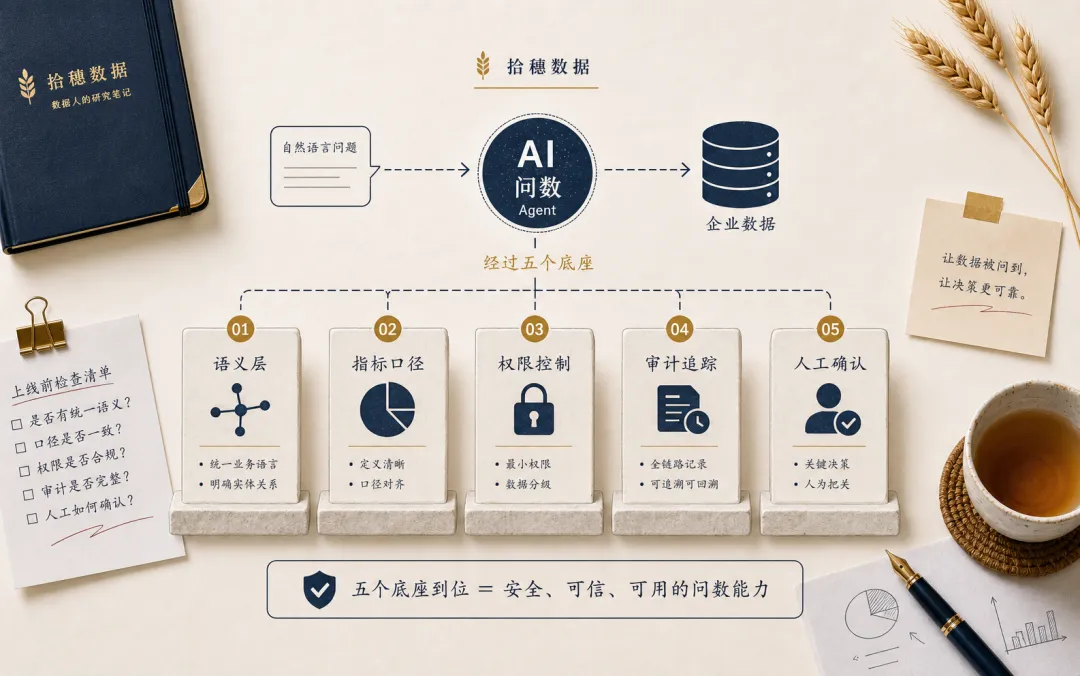
审计还可以反过来改进系统。你会看到用户最常问哪些问题,哪些问题经常失败,哪些指标缺少语义定义,哪些 SQL 成本过高,哪些权限规则经常被触发。
这些都是问数产品真正变好的材料。
第五件事:关键场景必须有人确认
很多人做 Agent 时,会默认追求全自动。但企业数据场景里,全自动不一定是好事。
尤其是经营会议、财务口径、客户分层、敏感数据、跨部门指标这些场景,AI 生成结果后最好有人确认。
人工确认不是为了拖慢,而是为了划清责任。
可以把场景分级。低风险问题,比如“昨天订单数是多少”,可以自动回答。中风险问题,比如“本周转化下降主要来自哪里”,可以自动生成分析,但标注置信度和口径。高风险问题,比如“哪个销售区域质量最差”“哪些客户可能流失”“本月收入是否达标”,需要人工确认后再发布。
这叫 human-in-the-loop,不是形式主义。
它让系统既能提高效率,又不会把关键判断交给一个不可追责的黑箱。
一个更安全的问数链路
比较稳妥的链路应该是这样的。
用户提出问题后,系统先做意图识别,判断这是查数、分析、归因还是生成报告。然后进入语义层,把自然语言映射到指标、维度、时间和过滤条件。接着做权限校验,判断用户能不能看这些数据。再生成 SQL 或调用指标服务。执行前后记录审计信息。最后根据风险等级决定是否需要人工确认。
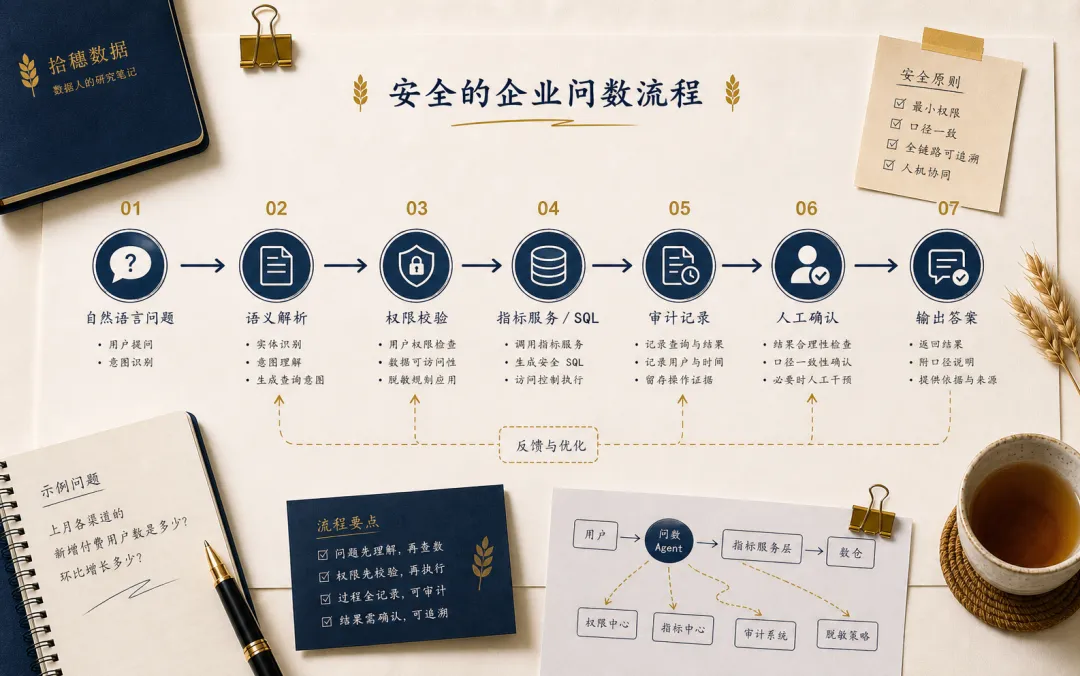
这个链路比 Demo 复杂,但它才接近生产。
真正的企业 AI,不是“模型能不能一次回答”,而是“系统能不能稳定、可控、可追责地回答”。
先做小,不要一口吃掉全公司
问数 Agent 最容易失败的方式,是一开始就想覆盖所有数据、所有部门、所有问题。
这会把语义层、权限、指标、性能、治理、产品体验全部压到第一版里,最后要么做不完,要么上线后没人敢用。
更好的方式,是选一个高频、边界清楚、风险可控的场景。
比如只做销售经营问数,只覆盖 20 个核心指标,只允许查询聚合数据,不开放明细,不跨权限域,所有高风险答案需要人工确认。先让这一个场景跑通,再扩到运营、产品、财务。
AI 问数不是一个模型项目,而是一个数据产品项目。
模型只是其中一环。真正决定成败的,是指标、语义、权限、审计、责任和使用场景。
所以,如果你的团队正在准备让 AI 接数据库,不妨先停一下。不要先问“模型选哪个”,先问:我们的指标有没有唯一入口?语义层有没有?权限能不能按问题控制?查询能不能审计?关键答案由谁确认?
这些问题答清楚之前,别急着让 AI 直接查库。

如果你正在系统学习 AI Agent、语义层、指标治理和企业数据平台,可以继续看数据从业者全栈知识库[1]。这类内容我会持续整理成更完整的工程化路径,而不只是停留在 Demo 层面。
关于「拾穗数据」
十来年数据行业里摸爬滚打的一点东西——
周刊、长文、观点,把踩过的坑和看到的局一点点写下来。
都在 ss-data.cc,点下方【阅读原文】去看。
想一起聊?扫码加微信,备注「拾穗」拉你进群:

[1]数据从业者全栈知识库https://pro.ss-data.cc
