 夜雨聆风
夜雨聆风核心总结:通用框架(Agent/龙虾/Skill/RAG)的核心价值的是解决开放环境中的动态适配问题,适合需灵活组合能力的场景;而专用大模型应用通过流程固化、功能内嵌和知识封闭化,已消除对动态规划与模块化调用的依赖。若专用场景的端到端流程已完整实现,则引入通用框架不仅无法提升效果,反而会因额外抽象层增加复杂度、延迟与安全风险。关键判断标准在于:任务是否需要实时决策与工具组合——确定性流程用专用方案,开放性任务用通用框架。
首先清晰解释大模型、Agent、龙虾、Skill、RAG的定义、作用、应用场景及解决的问题,同时明确其是否适用于专用大模型应用:
1. 大模型:作为AI系统的核心决策引擎,核心作用是负责推理与内容生成,类比为人脑,是所有相关应用的基础。它解决的是AI系统“能思考、能生成”的核心问题,适用于所有大模型相关应用(包括通用和专用场景),是专用大模型应用的核心基础。
2. Agent:本质是任务执行者,核心能力是拆解目标、调用工具并自主完成多步骤任务。它主要解决通用大模型“无法自主拆解复杂任务、无法联动工具”的短板,应用场景集中在开放环境中(如多场景协同、任务流程不确定的场景),不适用于专用大模型应用。
3. 龙虾(OpenClaw):是开源的Agent运行框架,核心作用是整合大模型、Skill与MCP协议,为Agent的运行提供支撑,相当于Agent的“运行载体”。它的应用场景与Agent一致,主要服务于开放环境下的动态任务,不适用于专用大模型应用。
4. Skill:是标准化的能力模块,核心作用是提供具体的执行功能(如查天气、发邮件、数据检索等),是Agent调用的“具体工具”。它解决的是Agent“能执行具体操作”的问题,仅适用于开放环境中需要灵活调用各类工具的场景,不适用于专用大模型应用。
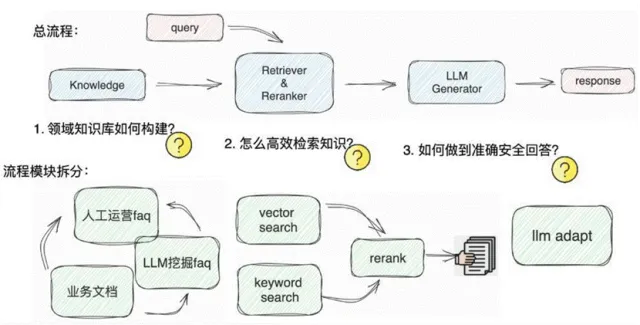
5. RAG:即知识增强技术,核心作用是通过检索外部数据,补充大模型的知识储备,减少大模型“幻觉”(生成错误信息)的问题。它解决的是通用大模型知识时效性不足、知识覆盖面有限的短板,适用于需要实时更新知识、补充外部信息的场景,若专用大模型应用无需外部知识补充(知识已封闭内嵌),则无需使用。
需要特别说明的是:从大模型应用开发至今,核心功能和技术从未发生过任何变化,所有的技术迭代和补充,都是针对“开放环境下的大模型应用”(即场景不确定、任务不固定的场景),而非专用大模型应用。
我们可以用一个通俗的类比理解核心逻辑:大模型就像一个人脑,它的处理能力是有限的,无法一次性处理一个复杂的大任务。因此,人们在大模型外部增加了一层“任务处理逻辑”——把一个大任务拆分成几个小任务(这个拆解过程也可以由大模型完成),然后逐个执行这些小任务,最后合并任务结果、检查结果正确性,整个过程从始至终没有任何变化。而这个过程,本质上就是在模拟人工的工作过程,或者说把手工的工作过程沉淀到大模型的应用中,用大模型代替一部分人脑的工作。由此可见,大模型应用的开发核心就是模拟人的工作过程,这就需要把大家有效的工作流程,或者分析测试用例的经验沉淀下来,而这离不开业务专家的协助,只有借助业务专家的专业经验,才能把测试分析等工作做得更好。
比如,让大模型直接从需求文档中生成测试用例,这个任务既超过了大模型的处理能力,也超出了普通业务分析人员的能力,导致大模型生成的结果正确性不足40%(多为混乱内容)。正是因为这个问题,我们才需要拆解任务:先将需求条目化,再从每个条目中拆解出业务规则和检查点,接着针对每个需求条目及对应规则生成测试用例,最后合并所有测试用例,标记出错误和重复的内容——这就是“任务拆解”的核心价值,但这种价值仅体现在开放、复杂、不确定的场景中。
这里需要明确龙虾和Agent的具体工作逻辑:不管面对的是什么任务,只要交给它们,只需告知任务名称,它们就会调用大模型将任务拆分成子任务,但这种拆分过程,肯定没有专用工具预先拆分的准确;拆分后再依次执行子任务,执行过程中会从RAG中查询数据。需要注意的是,RAG本质就是一个搜索引擎,它并不具备智能判断能力,因此检索到的数据可能并不适用当前场景,比如在处理活期存款相关任务时,它可能会检索到零存整取的需求,显然不如专用应用中预先设定的专用知识精准。说到底,通用技术解决的是场景无关的通用性问题,其精确度必然不如针对特定场景优化的专用工具。
而在专用大模型应用中,我们已经针对特定场景,完成了端到端的流程拆解、流程编排和功能实现(相当于提前把“复杂任务的拆解逻辑、执行步骤、所需功能”都固定好了),此时就完全不需要Agent、龙虾、Skill等通用框架下的功能。原因很简单:这些通用框架的核心价值是“动态规划任务、灵活调用工具”,而专用场景的流程是固定的、确定的,不需要动态调整,引入这些框架只会增加额外的抽象层,进而提升系统复杂度、延长响应延迟,甚至带来不必要的安全风险,完全无法提升应用效果。
