 夜雨聆风
夜雨聆风本文是「AI 基础设施科普」系列第 6 篇。上一篇我们聊了 AI Agent——AI 从"只会说话"变成"会自己干活"。但 Agent 再能干,如果脑子里装的是过时的知识、或者干脆就是编的,那干出来的活也不靠谱。今天我们就来聊一个让 AI "有据可依"的关键技术——RAG。
一、AI 最大的问题:会编
你可能遇到过这种情况——问 AI 一个专业问题,它回答得头头是道,但你一查,全是编的。
这不是个别现象。大语言模型有三个"先天缺陷":
RAG 就是解决这些问题的核心技术。
RAG 全称 Retrieval-Augmented Generation(检索增强生成),听起来复杂,核心思想四个字:先搜再答。
举个生活类比:
你去医院看病,医生不会凭记忆给你开药——他会先翻你的病历、看检查报告,再根据这些信息做判断。
普通的大模型就像一个不看病历就开药的医生,全凭脑子里的记忆;RAG 就像先翻病历再看检查报告的医生,有据可依。
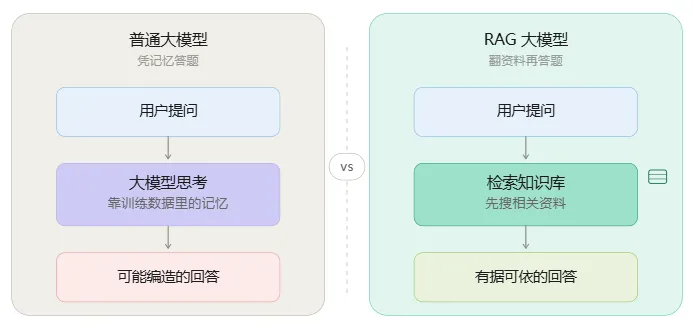
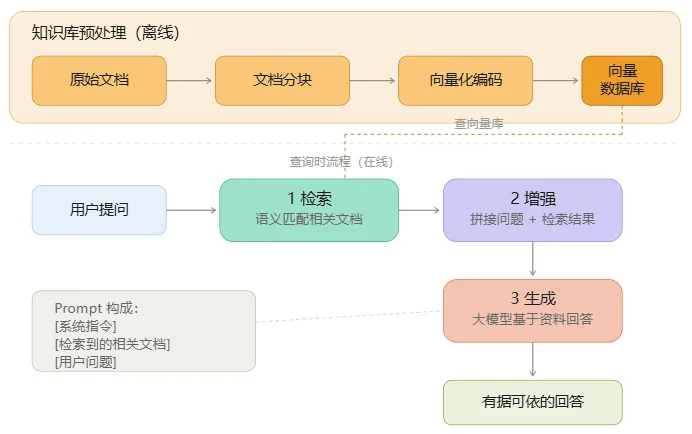
二、RAG 怎么工作?三个步骤
RAG 的工作流程可以拆成三步:
第一步:检索(Retrieve)
把你的问题丢进知识库,搜出最相关的内容。就像在图书馆用关键词查书——只不过 RAG 用的是"语义搜索",不要求关键词完全匹配,而是理解你问题的意思来找。
第二步:增强(Augment)
把搜到的内容和你的问题拼在一起,组成一个"增强版提示词"。相当于给 AI 递了一份参考资料——“这是相关的背景信息,请基于这些来回答”。
第三步:生成(Generate)
大模型基于增强后的提示词生成回答。这时候 AI 就不是凭空编了,而是基于你给它的资料来组织答案。
一个真实例子:
你问:“我们公司 2026 年 Q1 的销售额是多少?”
• 没有 RAG:AI 说"根据公开信息,2026 年 Q1 该公司销售额约为……"(编的) • 有 RAG: 1. 检索:从公司内部知识库中搜到"2026 年 Q1 财报摘要" 2. 增强:把财报摘要拼进提示词 3. 生成:AI 基于财报数据回答——“根据公司财报,2026 年 Q1 销售额为 1.23 亿元,同比增长 15%”
关键区别:AI 从"凭记忆猜"变成了"照资料答"。
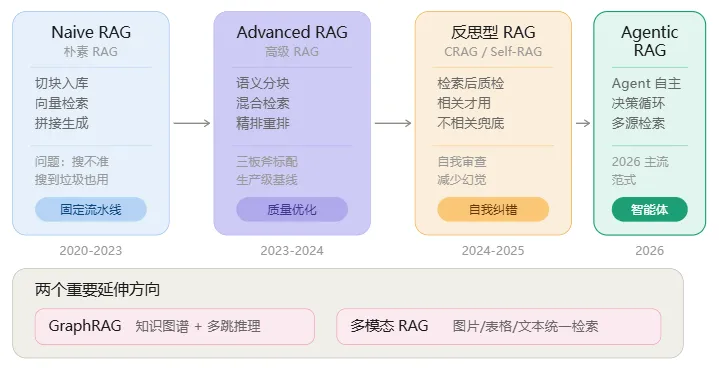
三、RAG 不只是"搜一下"——从朴素到智能的进化
最基础的 RAG(学术界叫 Naive RAG)就是把文档切块、向量化、检索、拼 Prompt、生成,一条线走完。简单,但问题也多——搜不准、搜不全、搜到垃圾也照用。
2024-2026 年,RAG 经历了快速进化,目前已经发展出十几种变体。按解决的问题分类,最重要的几代:
第一代:Naive RAG(朴素 RAG)
最基础的实现。文档切块 → 向量化入库 → 向量检索 → 拼接生成。
问题:切块可能截断语义(把一段完整论述切成两半),检索依赖向量质量,搜到不相关的内容也照用不误。
第二代:Advanced RAG(高级 RAG)
针对 Naive RAG 的每个环节做了优化:
生产级 RAG 的基本配置三板斧:语义分块 + 混合检索 + 精排。 几乎所有生产环境都建议这么做。
第三代:反思型 RAG
前两代都是"搜完就用",不管搜到的内容质量如何。反思型 RAG 加了"质检员":
• CRAG(Corrective RAG):搜完先判断相关性。相关的用,不相关的自动转 Web 搜索兜底,模糊的合并两边结果 • Self-RAG:全流程四个检查点——需要检索吗?文档相关吗?回答有依据吗?答案有用吗?每个环节都自我审查
第四代:Agentic RAG(智能体 RAG)
这是 2026 年的生产主流范式。
前面几代都是固定流水线——检索 → 增强 → 生成,走完就结束。Agentic RAG 让 Agent 自主决策:需要查哪些数据源?检索结果够不够?不够就换个方式再搜,或者同时查多个来源,直到信息充足再回答。
你可能已经用过了——Cursor 在编程时自动检索代码库,就是 Agentic RAG 的典型应用。
还有两个重要方向
GraphRAG:微软 2024 年提出。先用 AI 从文档中抽取实体和关系,构建知识图谱,查询时沿图谱推理。擅长"跨文档多跳推理"——比如"A 公司的子公司 B 持有 C 公司的股份,C 公司的 CEO 是谁?"这种需要串联多篇文档的问题。但构建成本高、查询延迟大。
多模态 RAG:把图片、表格、文本统一编码,检索时跨模态匹配。企业文档里那些流程图、架构图,终于也能被搜到了。
四、一个关键问题:上下文窗口那么大,还需要 RAG 吗?
2026 年,GPT-5.5 Pro 和 Claude Opus 4.7 的上下文窗口已经到了 1M Token(约 75 万字),Gemini 3.1 Pro 甚至到了 2M。把文档全塞进去不就行了?
不能。 三个原因:
1. 太贵
1M Token 的输入,用 GPT-5.5 Pro API 一次就要几十美元。如果有 10 万份文档,总字数远超 1M——你不可能把所有文档都塞进去。
2. 太慢
上下文越长,模型处理越慢。1M Token 的推理延迟比 10K Token 高一个数量级。
3. Lost in the Middle
我们在上一篇文章聊过——大模型对超长上下文的中间部分注意力会下降。你塞了 100 页资料进去,它可能只认真看了开头和结尾,中间 80 页都"忽略"了。
所以最佳实践是 RAG + 长上下文互补:先用 RAG 精准检索出最相关的几段内容(可能就几千 Token),再用长上下文模型对这些内容做深度推理。不是二选一,而是搭档。
五、普通人怎么用上 RAG?
不需要自己搭系统,很多产品已经内置了 RAG:
对话式产品
• ChatGPT Deep Research:自动搜索互联网资料,基于检索结果写深度报告 • Perplexity:每次回答都附带引用来源,你可以点击验证 • Kimi / 秘塔 AI 搜索:国内支持长文档上传 + 联网搜索的 RAG 产品
编程场景
• Cursor:自动检索你的代码库,基于项目上下文写代码 • GitHub Copilot:基于当前项目文件和上下文补全代码
知识管理
• Notion AI:基于你的 Notion 工作区内容回答问题 • Obsidian + 插件:基于本地笔记库检索回答 • 各种企业知识库产品:钉钉 AI、飞书智能助手、腾讯文档 AI
想自己搭?入门路径:
1. 先用 LangChain 或 LlamaIndex 跑通 Naive RAG(半天搞定) 2. 加上混合检索 + 精排(1-2 天) 3. 发现哪个环节有瓶颈再针对性优化 4. 切勿一上来就搞 GraphRAG + Multi-Agent 全家桶——先让基础跑起来
六、RAG 的局限
RAG 很有用,但不是银弹:
1. 检索质量是天花板
RAG 的回答质量上限取决于检索质量。如果知识库里没有相关内容,或者搜不到,RAG 也救不了。所谓"垃圾进,垃圾出"。
2. 向量化会丢信息
把一段文字压缩成一个高维向量,必然有信息损失。微妙的法律措辞、技术细节的精确匹配,向量检索可能抓不准。这也是为什么混合检索(向量 + 关键词)很重要。
3. 知识库维护成本
文档更新了、结构变了、新知识产生了——知识库需要持续维护。很多企业 RAG 项目上线后效果衰退,就是因为知识库没人更新。
4. 多跳推理仍然困难
"A 的创始人投资了哪些公司?那些公司的最新估值是多少?"这种需要串联多步推理的问题,Naive RAG 做不好,GraphRAG 能做但成本高。
5. 隐私和安全
RAG 让 AI 能读取企业私有数据,那谁有权限查什么?敏感信息会不会通过 RAG 被越权访问?企业部署 RAG 时,权限管控是必答题。
七、一句话总结
RAG 让 AI 从"凭记忆答题"变成"开卷考试"——先搜资料再回答,有据可依,减少瞎编。 从最基础的"切块检索"到 2026 年主流的"智能体自主检索",RAG 已经经历了四代进化。如果你想让 AI 基于你自己的数据回答问题,RAG 是目前最成熟的方案。
下一篇我们聊 RAG 背后的搭档:工具调用(Tool Use)——AI 怎么从"只会说话"变成"会动手干活"。
系列传送门
