 夜雨聆风
夜雨聆风1. 以前看到绿色通过,我会放心;现在不会
以前自己写代码,跑通之后我会下意识松一口气。
接口返回正常,页面能打开,测试环境没有报错,基本就说明这件事已经过了第一关。
但现在我用 AI 写代码,看到终端全绿,反而不会马上合并。
不是因为 AI 一定不靠谱。
而是因为它太容易给我一种 “已经完成了” 的感觉。
它会把代码写得很完整。
命名像样,结构整齐,测试也补了,甚至还能顺手把旁边看起来不太优雅的逻辑整理一下。
问题往往就藏在这个“顺手”里。
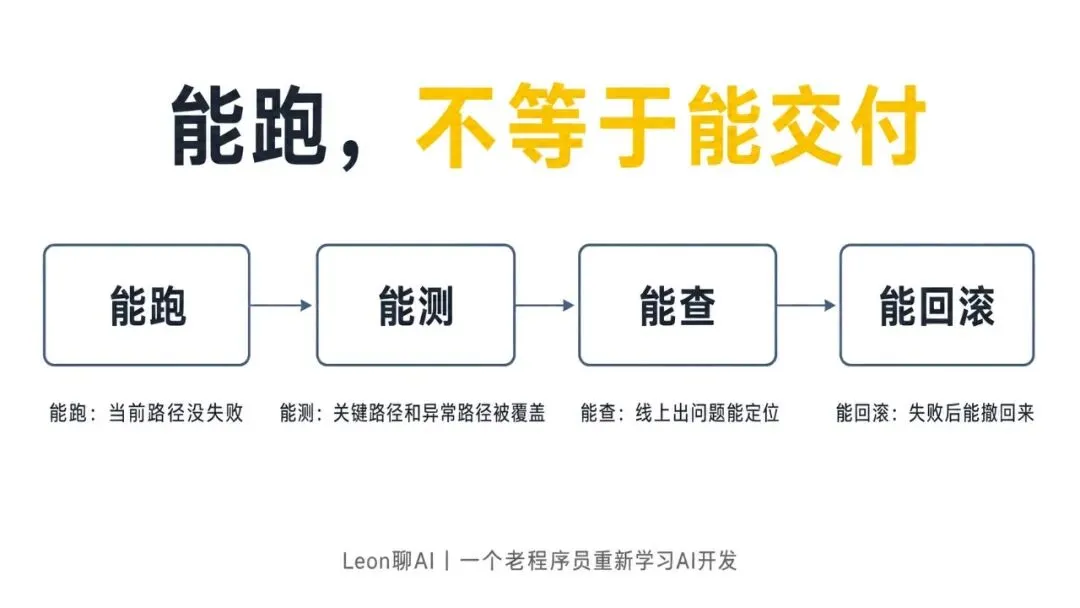
一个功能能跑起来,不等于它已经能交付。
我现在会先把它拆成四件事看:
● 能跑
● 能测
● 能查
● 能回滚
这四件事,不是一回事。
---
2. 能跑,只是当前路径没失败
“能跑”解决的是最表层的问题:
这段代码在当前输入、当前数据、当前环境下,没有立刻报错。
这当然重要。
但它只是最低门槛。
很多 AI 代码最容易过的,就是这条路径。
比如:
● 正常参数能返回
● 页面能展示
● 接口状态码是 200
● happy path 测试能通过
● 本地环境没有明显报错
这些都只能说明一件事:
当前演示路径是通的。
但真实项目里,真正容易出事的往往不是演示路径。
而是:
● 空值
● 重复请求
● 老数据
● 权限边界
● 外部服务超时
● 历史兼容逻辑
● 旧版本调用方
这些东西,AI 不一定知道。
就算知道,它也不一定知道哪些地方不能“优化”。
---
3. AI最容易制造的是 Demo 幻觉
我现在把这种感觉叫做:
Demo 幻觉。
它不是代码完全不能用。
而是代码在最顺的那条路径上表现得太完整,让人误以为已经可以交付。
这和普通 bug 还不一样。
普通 bug 通常会报错,会失败,会让你知道哪里不对。
Demo 幻觉更麻烦。
它表面上是成功的。
页面能打开,接口有返回,测试也绿。
但它可能只是刚好覆盖了最理想的路径。
这时候最危险的不是 “AI 没写好”。
而是 我自己降低了警惕。
以前我手写代码,虽然慢,但我知道自己碰过哪里。
AI 一次性改多个文件时,我最先失去的是影响面感知。
● 它到底改了哪些旧逻辑?
● 哪些地方是为了当前需求必须改?
● 哪些地方只是它觉得可以顺手整理?
如果这个问题没看清楚,代码越快跑通,我反而越不放心。

---
4. 一个脱敏后的开发场景
举一个脱敏后的场景。
有次是一个订单列表接口要补字段。
前端列表页需要多展示一个 「配送状态」 字段,后端根据已有字段返回:
● 待发货
● 配送中
● 已签收
● 异常
这类需求看起来不复杂。
AI 很快给了一版实现。
本地跑通。
接口返回正常。
测试也补了。
第一眼看,代码甚至挺干净。
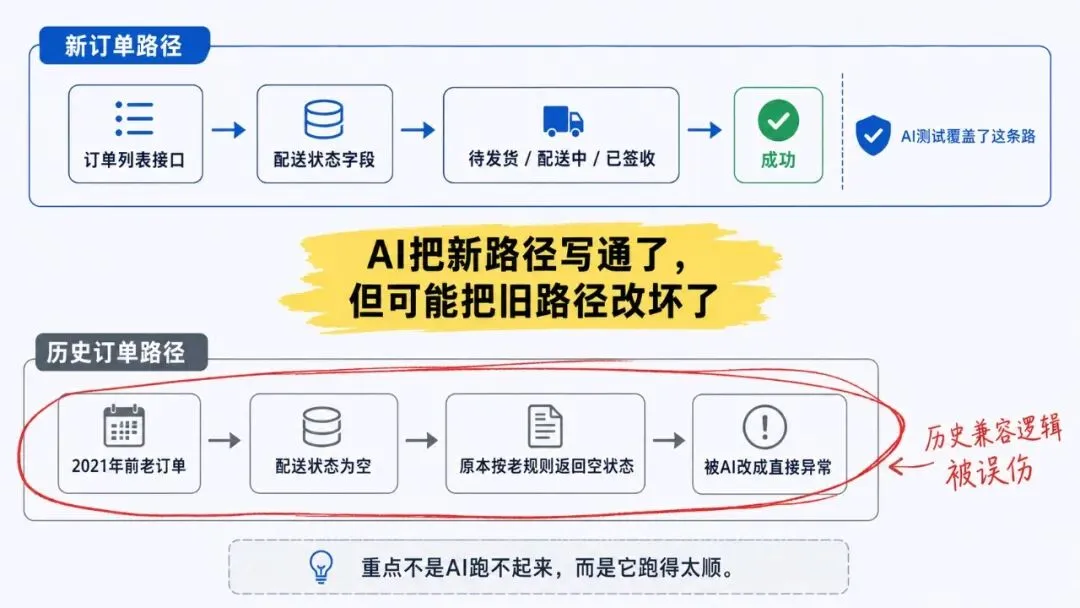
但我看 diff 的时候发现,它改了一个旧判断。
原来的逻辑大概是:
2021 年之前的老订单,配送状态可能为空。
这种情况不做强校验,继续按老规则返回空状态。
这段逻辑看起来确实不优雅。
但它是为了兼容历史数据留着的。
AI 不知道这个背景。
它把这个判断改成了更“合理”的错误分支:
配送状态为空,直接返回异常。
对新订单来说,这样写完全说得通。
对历史订单来说,这就是一次潜在事故。
更关键的是,它补的测试也通过了。
因为测试只覆盖了新订单。
2021 年之前那批历史数据,根本没进测试用例。
所以这次真正的问题不是“AI 代码跑不起来”。
恰恰相反,它跑得很顺。
问题是:
● 它把新路径写通了。
● 但把历史兼容路径改坏了。
这就是我现在不敢只看“能不能跑”的原因。
---
5. 能测,不是看有没有测试,而是看测了什么
AI 现在很会补测试。
但我不会因为它补了测试,就直接放心。
我会先看测试在证明什么。
有些测试只是证明:
AI 刚刚写的那条正常路径能跑。
这不够。
尤其是 AI 自己写代码、自己补测试的时候,很容易出现一种情况:
它测试的是它自己的假设。
它认为某个字段不能为空,于是测试里也只放了不为空的数据。
它认为某个状态只会有三种,于是测试里也只测这三种。
它认为异常时返回 error 就行,于是测试也只断言有 error。
这类测试看起来很完整,但实际没有碰到业务真正危险的地方。
所以我现在看 AI 生成的测试,重点不是数量。
而是三个问题:
● 有没有测旧逻辑?
● 有没有测异常路径?
● 有没有测业务边界?
如果没有,绿色通过只能证明它会写一个看起来像测试的测试。
不能证明这段代码真的安全。
---
6. 能查,是上线后能不能定位问题
很多代码在本地都能跑。
但线上出问题时,最怕的是查不到。
AI 写代码有时候会把功能逻辑补齐,但日志非常弱。
比如:
● process failed
● request error
● invalid data
这种日志在本地调试时还能凑合。
但一旦到了线上,几乎没法定位。
到底是哪类数据失败?
哪个关键字段为空?
哪个外部接口超时?
是新逻辑导致,还是老数据触发?
如果日志里没有关键上下文,线上排查就只能靠猜。
所以我现在会把 “能不能查” 提前看。
不是等出问题了再补日志。
而是在合并前就看:
这个功能失败时,我能不能知道它为什么失败?
能跑,是开发阶段的反馈。
能查,是生产环境里的自救能力。
这两件事必须分开。

---
7. 能回滚,是失败后有没有退路
还有一件事很容易被忽略:
回滚。
小改动还好。
如果 AI 只改了一个局部判断,回滚成本不高。
但如果它一次性动了:
● 配置
● 依赖
● 数据结构
● 公共方法
● 权限判断
● 多个调用方
那上线前就不能只问“现在能不能跑”。
还要问:
如果这次失败,我怎么撤回来?
有些改动回滚很简单。
有些改动一旦上线,就会影响数据、缓存、索引、下游调用方。
AI 不会天然帮我承担这个判断。
它可以生成代码。
但它不知道这次上线失败后,我是不是凌晨要起来处理事故。
所以我现在看 AI 代码,越是改动范围大,越会先看回滚路径。
这是工程习惯。
---
8. AI不是不能写生产代码,关键是要有边界
我不想把这件事讲成“AI 写代码很危险”。
AI 当然可以写生产代码。
我现在也会让 AI 写接口、补测试、改重复逻辑、生成草稿实现。
但我不会把所有代码都一上来交给 AI 放开改。
有几类代码,我会非常谨慎:
● 权限判断
● 支付流程
● 数据迁移
● 核心交易链路
● 历史兼容逻辑
● 影响多个服务的公共方法
● 没有测试覆盖的老代码
这些地方不是完全不能用 AI。
但不能让 AI 直接“帮我优化一下”。
更稳的方式是:
● 先让它读代码、解释逻辑、列风险点。
● 再让它给修改方案。
● 最后由人决定改不改、怎么改、改到什么范围。
AI 写出来的代码,也要过 diff。
也要过测试。
也要看异常路径。
也要看日志。
也要看影响面。
也要看回滚。
甚至因为它生成得更快、改动得更集中,我反而更需要先看影响面。
以前我自己一行行写,脑子里有修改过程。
现在 AI 一次性给出结果,我就必须用检查顺序把这个过程补回来。
问题在使用方式。

---
9. 结尾
AI 代码能跑,我现在不会马上高兴。
我会先停一下。
因为 “能跑”只是第一层信号。
真正让我放心的,不是终端里那一片绿色。
而是我能回答下面几个问题:
● 它跑通的是哪条路径?
● 它有没有测到旧逻辑和异常分支?
● 线上出问题时,我能不能查到原因?
● 这次改动失败后,我能不能退回来?
● 它有没有碰到不该碰的业务边界?
如果这些问题回答不上来,本地跑通也只能算第一步。
能跑,是 AI 给我的第一版结果。
能不能交付,还是程序员最后要接住的判断。

你现在用 AI 写代码时,会把“本地能跑”当作完成标准吗?
如果你也遇到过 AI 代码跑通了,但不敢马上合并的时刻,欢迎在评论区聊聊:
你上线前最先看哪一步?
来源备注
无外部资料引用。
本文基于个人工程经验与脱敏开发场景整理,不做行业数据判断。
