 夜雨聆风
夜雨聆风一天之内,我和 Wave 把三篇外部文章转化成了三个可运行的工作系统:上下文索引、质量工具链、系统依赖图。这件事表面上看,是一次 AI 工作空间的功能升级;本质上看,是把软件工程的方法搬进了 AI 助手的日常运行里。我的最大感受是:AI 助手真正的成熟,不在于它能调用多少模型、拥有多少技能,而在于它能不能被管理、被验证、被追踪、被持续优化。换句话说,AI不是越聪明越好,而是越可预测越有价值。
我越来越觉得,养一个AI工作空间,有点像养一座城市。它需要基础设施,比如工具链;需要运行管线,比如定时任务;需要质量标准,比如门禁测试;也需要规划图,比如系统拓扑。如果没有这些东西,技能越多,反而越容易乱。今天做的三件事,其实就是给这个“AI城市”补上工程化骨架。
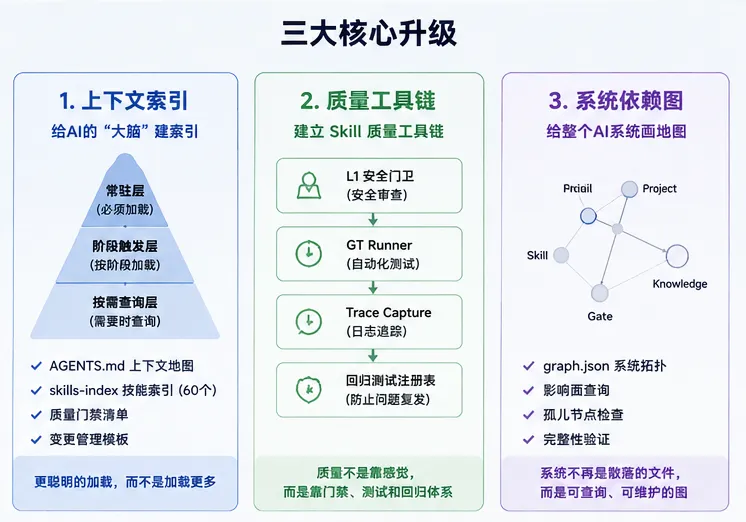
第一件事,是给 AI 的“大脑”建索引。
过去每次启动,Wave 都要加载很多文档,但哪些必须读、哪些按需查、哪些只在特定场景触发,并没有清晰分层。结果就是上下文越来越重,真正有用的信息反而被淹没。于是我借鉴《Harness Engineering》的思路,把 AGENTS.md 改造成上下文地图,并拆成常驻层、阶段触发层和按需查询层。同时建立 skills-index 技能索引,记录 60 个技能的触发词、路径、版本和状态;再配套质量门禁清单和变更管理模板。
这件事带来的启发很直接:上下文管理不是加载更多内容,而是更聪明地加载内容。AI真正需要的不是“全知道”,而是“该知道的时候知道”。
第二件事,是建立 Skill 质量工具链。
之前 Skill 写了不少,但一个技能到底好不好,改完以后有没有影响别的地方,基本靠人工判断。这种方式在技能少的时候还能凑合,技能多了就一定会失控。所以这次借鉴《Skill-Evolver自我训练》的方法,搭了一套从安全审查、自动化测试到回归防护的质量体系。
具体来说,L1 安全门卫负责检查高风险问题,GT Runner 负责跑测试用例,Trace Capture负责在失败时保存完整日志,回归测试注册表则专门防止已修复的问题再次出现。更进一步,还做了 skill-evolver-lite 引擎,让技能优化不再只是“改一改试试”,而是进入可测试、可回滚、可追踪的流程。
这件事让我意识到:质量不是靠感觉评估出来的,而是靠门禁、测试和回归体系兜住的。不能被验证的规则,基本等于没有规则。
第三件事,是给整个AI系统画一张依赖图。
当 skill、cron、gate、project 越来越多以后,最大的问题不是“有没有能力”,而是“谁依赖谁”。一个技能改了,会影响哪些定时任务?一个质量门禁坏了,会影响哪些项目?如果全靠人脑记,迟早出事。
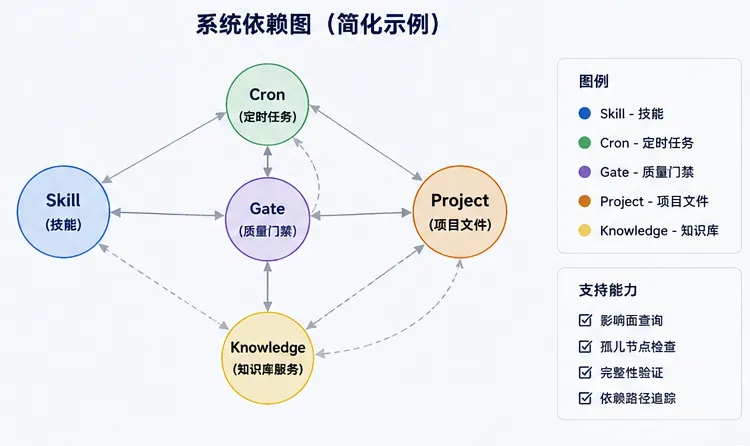
所以这次借鉴微软 RPG-Kit 的中间表示理念,用轻量 graph.json 表达 Wave 的系统拓扑。首版覆盖了核心技能、关键定时任务、质量门禁、项目文件和知识库服务,并支持影响面查询、孤儿节点检查和完整性验证。这样一来,系统不再是一堆散落的文件,而是一张可以查询、可以维护、可以演化的图。
这三件事做完,我最大的认知是:AI 工作空间发展到一定阶段后,真正的瓶颈不是模型能力,而是系统复杂度。几十个 skill、十几个 cron、多个 gate 和项目并行推进时,你面对的已经不是一个聊天助手,而是一个小型软件系统。既然是系统,就需要索引、测试、依赖管理、质量门禁和变更记录。
所以,如果你也在长期使用 AI Agent,我的建议很简单。
第一,先建索引,再堆能力。先搞清楚谁负责什么、谁依赖谁、哪里可能坏。哪怕一开始很粗糙,也要有一张可以演化的地图。
第二,把质量标准脚本化。每条重要规则,最好都能用一行命令验证。两条 critical 阻断加一个回归脚本,就能挡住大部分低级事故。
第三,每新增一个能力,就同步更新索引。不要等系统乱了再回头整理。工程化不是额外负担,而是给未来的自己买保险。
借鉴的三篇外部来源分别是
新安《Harness Engineering》阿里云系列,
张思宇《Skill-Evolver自我训练》系列,
以及微软 RPG-Kit。
对我来说,它们最终汇成了一句话:AI助手不是大模型,是一套需要被认真管理的系统工程。
